




1 数据导入
在kaggle上下载完训练数据和测试数据之后,将数据导入。由于训练数据集过大,电脑配置有限,训练集只导入100000条记录。
trainData=pd.read_csv('train.csv',nrows=100000)
testData=pd.read_csv('test.csv')
2 数据审查
2.1. 数据的整体情况
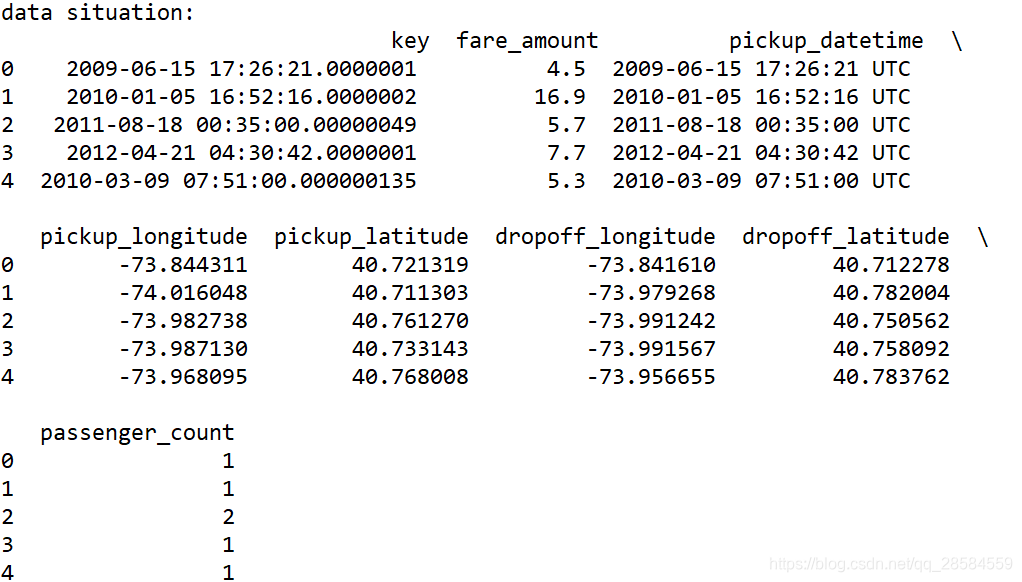
2.2 类型审查
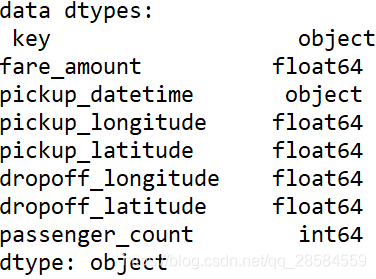
key列和pickup_datetime列显示为字符串类型,需要将其转换为时间类型。
2.3 数据的基本情况
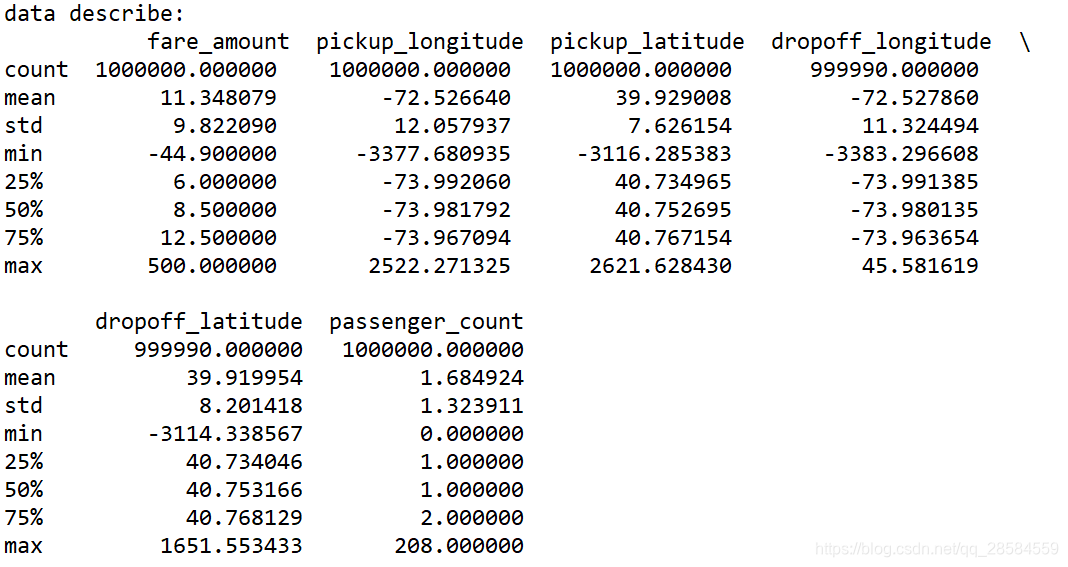
观察每一个变量的数据基本情况:从fare_amount来看,最小值为负数,不合常理;从经纬度来看,最小值为-3000多,最大值为2000多,不合常理;乘客人数最大为208人,最小为0人,不合常理。
2.4 缺失值审查
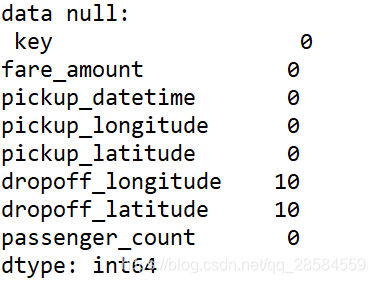
综上,需要首先对数据进行以下处理:
(1)异常值处理:去除明显异常的记录
(2)缺失值处理:去除存在缺失值的记录
(3)类型转换:将字符串类型的列转换成时间类型的列
3 数据预处理
数据预处理包括类型转化、异常值处理、缺失值处理等
###类型转换
trainData['key']=pd.to_datetime(trainData['key'])
trainData['pickup_datetime']=pd.to_datetime(trainData['pickup_datetime'])
print('data dtypes:\n',trainData.dtypes)
###缺失值处理
trainData=trainData.dropna(axis=0)
print('data null:\n',trainData.isnull().sum())
###异常值处理
#去除fare_amount异常值
trainData=trainData.drop(trainData[trainData['fare_amount']<=0].index)
#passenger_count异常值
trainData=trainData.drop(trainData[trainData['passenger_count']<=0].index)
trainData=trainData.drop(trainData[trainData['passenger_count']>6].index)
#去除经纬度异常值
#去除不在纽约市区经纬度范围内的上车下车点
def select_within_boundingbox(dataframe 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 651
651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









