






 这是一篇关于Java面试的选择题集锦,涵盖了二叉树遍历、数据结构性能分析、排序算法复杂度、堆排序原理、进程间通信、静态变量存储区域、数据库查询优化、IP地址分类、HTTP状态码含义、进制转换、TCP/IP协议栈、线程共享内容、构造函数执行顺序、递归函数特性、编译过程解析等方面的知识。
这是一篇关于Java面试的选择题集锦,涵盖了二叉树遍历、数据结构性能分析、排序算法复杂度、堆排序原理、进程间通信、静态变量存储区域、数据库查询优化、IP地址分类、HTTP状态码含义、进制转换、TCP/IP协议栈、线程共享内容、构造函数执行顺序、递归函数特性、编译过程解析等方面的知识。
(此系列试题来源于Java面试宝典书籍)
一、选择题
1. 已知一颗二叉树,如果先序遍历的节点顺序是:ADCEFGHB,中序遍历是:CDFEGHAB,则后序遍历结果为:
- A. CFHGEBDA
- B. CDFEGHBA
- C. FGHCDEBA
- D. CFHGEDBA
解析:
二叉树
- 前序遍历:根结点 左子树 右子树
- 中序遍历:左子树 根节点 右子树
- 后序遍历:右子树 根节点 左子树
思路:
- 根据前序遍历可以知道根节点
- 通过根节点将中序遍历分为两截进行递归操作
public class BinaryTree {
static class Node{
String value;
Node leftTree;
Node rightTree;
public Node(String value, Node leftTree, Node rightTree) {
this.value = value;
this.leftTree = leftTree;
this.rightTree = rightTree;
}
void printValue(){
System.out.println(value);
}
}
public static Node createNode(String value){
return new Node(value,null,null);
}
public static Node createNode(char value){
return createNode(String.valueOf(value));
}
/**
* 添加节点到左子树
*/
public static void addNodeToLeft(Node root,Node child){
if (root.leftTree == null){
root.leftTree = child;
}else {
throw new RuntimeException("the left child has already created");
}
}
/**
* 添加节点到右子树
*/
public static void addNodeToRight(Node root, Node child) {
if (root.rightTree == null) {
root.rightTree = child;
} else {
throw new RuntimeException("the right child has already created");
}
}
/**
* 前序遍历
*/
public static void preShow(Node root){
root.printValue();
if (root.leftTree != null){
preShow(root.leftTree);
}
if (root.rightTree != null){
preShow(root.rightTree);
}
}
/**
* 中序遍历
*/
public static void midShow(Node root){
if (root.leftTree != null){
midShow(root.leftTree);
}
root.printValue();
if (root.rightTree != null){
midShow(root.rightTree);
}
}
/**
* 后序遍历
*/
public static void postShow(Node root){
if (root.leftTree != null){
postShow(root.leftTree);
}
if (root.rightTree != null){
postShow(root.rightTree);
}
root.printValue();
}
/**
* 根据前序和中序遍历,推断后序遍历
*/
public static Node createTreeByPreAndMid(Node root,String pre_values,String mid_values){
if (!"".equals(mid_values)){
// 同步先序和中序字符串
String new_pre_values = synchronizedPreAndMid(pre_values,mid_values);
//这样可以保证,先序的第一个肯定是这棵树的根节点
char rootValue = new_pre_values.charAt(0);
root = createNode(rootValue);
int rootIndexOfIn = mid_values.indexOf(rootValue);//得到根节点在中序中的位置
// 根节点左边的一大串
String leftMidValues = mid_values.substring(0,rootIndexOfIn);
// 根节点右边的一大串
String rightMidValues = mid_values.substring(rootIndexOfIn+1,mid_values.length());
// 如果左边一大串就剩下一个了,
// 说明这肯定就是这课树的左节点,如果还剩下多个就继续递归调用
if(leftMidValues.length() == 1){
addNodeToLeft(root, createNode(leftMidValues));
}else if(leftMidValues.length() != 0){
addNodeToLeft(root, createTreeByPreAndMid(root, new_pre_values, leftMidValues));
}
// 如果右边一大串就剩下一个了,
// 说明这肯定就是这课树的右节点,如果还剩下多个就继续递归调用
if(rightMidValues.length() == 1){
addNodeToRight(root, createNode(rightMidValues));
}else if(rightMidValues.length() != 0){
addNodeToRight(root, createTreeByPreAndMid(root, new_pre_values, rightMidValues));
}
}
return root;
}
/**
* 每次都把在pre_values但是不在in_values里面的元素删掉,但是顺序不要变
*/
private static String synchronizedPreAndMid(String preValues, String midValues) {
String retVal = "";
for (int i = 0; i < preValues.length(); i++) {
for (int j = 0; j < midValues.length(); j++) {
if(preValues.charAt(i) == midValues.charAt(j)){
retVal += preValues.charAt(i);
}
}
}
return retVal;
}
public static void main(String[] args) {
Node a = createTreeByPreAndMid(null,"ADCEFGHB", "CDFEGHAB");
System.out.println("先序遍历:");
preShow(a);
System.out.println();
System.out.println("中序遍历:");
midShow(a);
System.out.println();
System.out.println("后序遍历:");
postShow(a);
System.out.println();
}
}
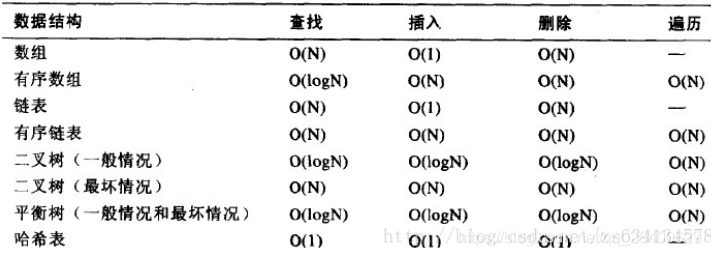
2. 下列哪两个数据结构,同时具有较高的查找和删除性能
- A. 有序数组
- B. 有序链表
- C. AVL树
- D. Hash表
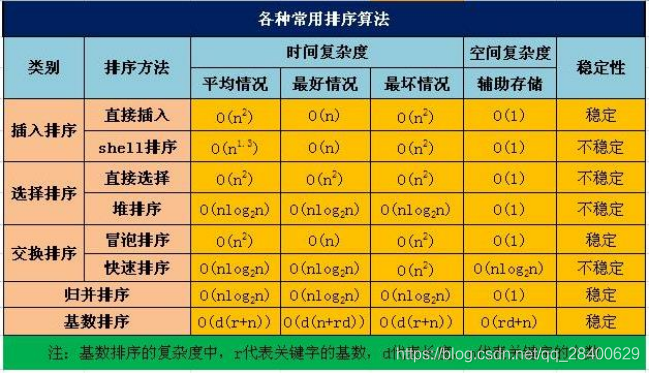
3. 下列排序算法中,哪些时间复杂度不会超过nlogn
- A. 快速排序
- B. 堆排序
- C. 归并排序
- D. 冒泡排序
解析:https://www.cnblogs.com/onepixel/articles/7674659.html 作者:一像素
稳定性分析:
- 当数值相等时,排序前和排序后其相等数值的位置不变,则该算法时稳定的,否则不稳定
时间复杂度:
- 算法语句执行的次数(比较次数和交换次数),时间复杂度考虑的是最坏的情况
- 如果是常数-->O(1),如果是n-->O(n),如果是n^2-->O(n^2)
例1
int count = 1;
while (count < n){
count = count * 2;
}
// 时间复杂度分析![]()
例2
for ( int i = 0;i<n; i++){
for (int j = 0;j<n; j++){
// 时间复杂度为O(1)的程序步骤序列
}
}
// 时间复杂度:O(n^2)例3
for ( int i = 0;i<n; i++){
for (int j = i;j<n; j++){
// 时间复杂度为O(1)的程序步骤序列
}
}
![]()
空间复杂度:
- 在运行过程中临时占用的存储空间的大小,创建次数最多的变量,即空间复杂度是多少
- 例:
// 临时变量temp创建了n次,因此空间复杂度为O(n)
for(int i=0;i<n;i++){
int temp = i;
}
// ---------------------------------------
// 临时变量只创建了一次,因此空间复杂度为O(1)
int temp = 0;
for(int i=0;i<n;i++){
temp = i;
}
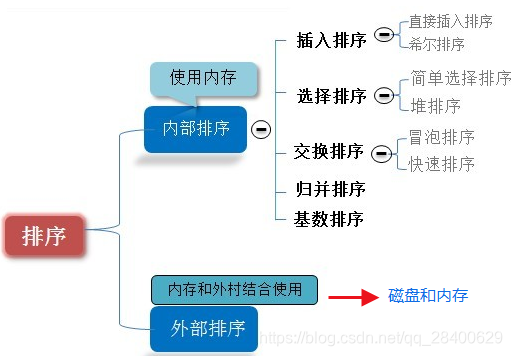 图片来源于上面的链接
图片来源于上面的链接
1) 冒泡排序:比较相邻的元素并交换位置,每个循环都将最大值移到最后
- 比较的趟数:arr.length-1
- 每次比较后,最大的数在最后
- 进行下一次后最后一个数不参与比较:arr.length-1-i
public static void BubbleSort(int[] arr){
for (int i=0;i<arr.length;i++){
int temp = 0;
for (int j=0;j<arr.length-1-i;j++){
if (arr[j]>arr[j+1]){
temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
}
}
}
for (int i: arr) {
System.out.print(i+" ");
}
}算法分析:
稳定性:稳定
时间复杂度:冒泡算法是以时间换空间的算法
- 最好情况:数组正序,则只比较n-1次即可,因此T(n)=O(n)
- 最坏情况:数组反序,比较的次数
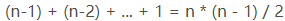 ,取数量级为O(n^2)
,取数量级为O(n^2) - 平均复杂度:O(n^2)
空间复杂度:临时变量创建次数,因此为O(n)
优化:使用flag进行优化,如果不在进行交换,就停止
public static void BubbleSort_up(int[] arr){
for (int i=0;i<arr.length-1;i++){
boolean flag = false;
for (int j=0;j<arr.length-1-i;j++){
if (arr[j]>arr[j+1]){
swap(arr,j,j+1);
flag = true;
}
}
if(!flag){
break;
}
}
for (int i: arr) {
System.out.print(i+" ");
}
}2) 选择排序:每趟找到数组的最小(最大元素),与前面进行交换
- 每一趟使得开始的值作为最小值
- 要记录的最小值的索引值
public static void SelectSort(int[] arr){
for (int i=0;i<arr.length-1;i++){
// 记录最小值的索引值
int minIndex = i;
for (int j=i+1;j<arr.length;j++){
if (arr[minIndex]>arr[j]){
minIndex = j;
}
}
int temp = arr[minIndex];
arr[minIndex] = arr[i];
arr[i] = temp;
}
for (int i: arr) {
System.out.print(i+" ");
}
}算法分析:
稳定性:不稳定 (取最小值和前面的进行交换)
其时间复杂度与空间复杂度和冒泡排序相似
3) 插入排序:每一个数与前面的所有数进行比较,知道比前面的数大,比后面的数小
- 每次循环都能排好一个数
- 把要排序的值抽出来,如果当前值比前面的值大,则前面的值往后移
- 直到当前值比前面的值大,则当前值插进去
public static void InsertSort(int[] arr){
for (int i=0;i<arr.length-1;i++){
// 要进行排序的数
int current = arr[i+1];
int preIndex = i;
while (current<arr[preIndex] && preIndex>0){
arr[preIndex+1] = arr[preIndex];
preIndex--;
}
arr[preIndex+1] = current;
}
for (int i: arr) {
System.out.print(i+" ");
}
}算法分析
稳定性:稳定
时间复杂度:
- 最好情况:正序,O(n)
- 最坏情况:反序,进行n-1次循环,比较次数1+2+3+...+n-1=n(n-1)/2
空间复杂度:O(n)
4) 希尔排序:主要思想是分组:每次增量为前面的一倍
- 排序的思想还是插入排序

public static void ShellSort(int[] arr){
int N = arr.length;
// 进行分组,最开始的增量为(gap)为数组长度的一半
for (int gap = N/2; gap>0; gap/=2){
// 对各个分组进行插入排序
for (int i=gap; i<N;i++){
int temp = arr[i];
int preIndex = i-gap;
while (preIndex>=0 && arr[preIndex]>temp){
arr[preIndex+gap] = arr[preIndex];
preIndex -= gap;
}
arr[preIndex+gap] = temp;
}
}
for (int i: arr) {
System.out.print(i+" ");
}
}算法分析
错位情况,由于分组 --> 所以不稳定
时间复杂度:
- 最优:O(n)
- 最差:O(n^2)
空间复杂度:O(1)
5) 归并排序:分治思想
- 把长度为n的输入序列分为两个子序列
public static int[] MergeSort(int[] arr){
if (arr.length < 2){
return arr;
}
int mid = arr.length / 2;
// 包括下标from,不包括上标to
int[] left = Arrays.copyOfRange(arr,0,mid);
int[] right = Arrays.copyOfRange(arr,mid,arr.length);
return merge(MergeSort(left),MergeSort(right));
}
private static int[] merge(int[] left, int[] right) {
int[] result = new int[left.length + right.length];
for (int index=0,i=0,j=0; index<result.length;index++){
if (i >= left.length){
result[index] = right[j++];
}else if (j >= right.length){
result[index] = left[i++];
}else if (left[i] > right[j]){
result[index] = right[j++];
}else {
result[index] = left[i++];
}
}
return result;
}算法分析
稳定性:稳定
时间复杂度:
- 最优:O(nlogn)
- 最差:O(nlogn)
空间复杂度:O(n)
6) 快速排序:也是分治思想
- 分为两个字串
- 从一个数列中挑出一个元素作为基准
- 重新排序,所有元素比基准值小的摆在基准前面,所有元素比基准值大的摆在基准的后面,相同的数可以到任一边
public static void quickSort(int[] arr,int start,int end) {
if(start<end) {
//把数组中的第0个数字做为标准数
int stard=arr[start];
//记录需要排序的下标
int low=start;
int high=end;
//循环找比标准数大的数和比标准数小的数
while(low<high) {
//右边的数字比标准数大
while(low<high&&stard<=arr[high]) {
high--;
}
//使用右边的数字替换左边的数
arr[low]=arr[high];
//如果左边的数字比标准数小
while(low<high&&arr[low]<=stard) {
low++;
}
arr[high]=arr[low];
}
//把标准数赋给低所在的位置的元素
arr[low]=stard;
//处理所有的小的数字
quickSort(arr, start, low);
//处理所有的大的数字
quickSort(arr, low+1, end);
}
}算法分析
稳定性:不稳定
时间复杂度:
- 最优:O(nlogn)
- 最差:O(nlogn)
空间复杂度:O(1)
7) 堆排序:堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点
public static void heapSort(int[] arr) {
//开始位置是最后一个非叶子节点,即最后一个节点的父节点
int start = (arr.length-1)/2;
//调整为大顶堆
for(int i=start;i>=0;i--) {
maxHeap(arr, arr.length, i);
}
//先把数组中的第0个和堆中的最后一个数交换位置,再把前面的处理为大顶堆
for(int i=arr.length-1;i>0;i--) {
int temp = arr[0];
arr[0]=arr[i];
arr[i]=temp;
maxHeap(arr, i, 0);
}
}
public static void maxHeap(int[] arr,int size,int index) {
//左子节点
int leftNode = 2*index+1;
//右子节点
int rightNode = 2*index+2;
int max = index;
//和两个子节点分别对比,找出最大的节点
if(leftNode<size&&arr[leftNode]>arr[max]) {
max=leftNode;
}
if(rightNode<size&&arr[rightNode]>arr[max]) {
max=rightNode;
}
//交换位置
if(max!=index) {
int temp=arr[index];
arr[index]=arr[max];
arr[max]=temp;
//交换位置以后,可能会破坏之前排好的堆,所以,之前的排好的堆需要重新调整
maxHeap(arr, size, max);
}
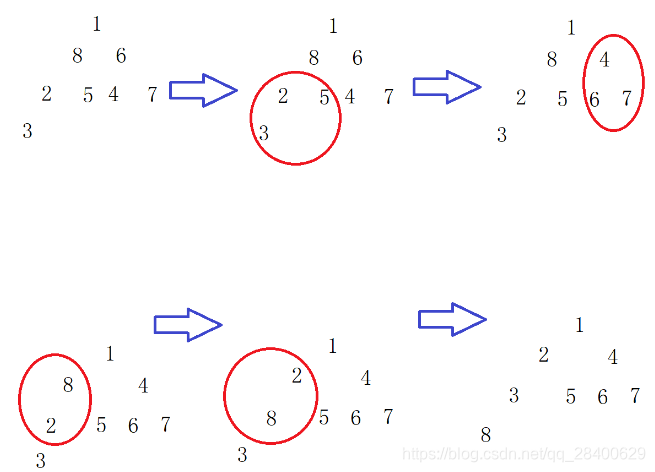
}4. 初始序列为1 8 6 2 5 4 7 3一组数采用堆排序,当建堆(小根堆)完毕时,堆所对应的二叉树中序遍历序列为:
- A. 8 3 2 5 1 6 4 7
- B. 3 2 8 5 1 4 6 7
- C. 3 8 2 5 1 6 7 4
- D. 8 2 3 5 1 4 7 6
解析:
堆排序
- 堆实际上是一棵完全二叉树
- 堆排序:利用大顶堆(小顶堆)堆顶记录的是最大关键字(最小关键字)这一特性,使得每次从无序中选择最大记录(最小记录)变得简单
- 最大堆的任意子树根节点不小于任意子结点
- 最小堆的根节点不大6于任意子结点
小根堆:
5. Linux系统中,哪些可以用于进程间的通信
- A. Socket
- B. 共享内存
- C. 消息队列
- D. 信号量
解析:https://www.cnblogs.com/liugh-wait/p/8533003.html 作者:刘广辉
6. 静态变量通常存储在进程哪个区
- A. 栈区
- B. 堆区
- C. 全局区
- D. 代码区
解析:静态变量的修饰关键字:static,又称静态全局变量
7. 如何提升查询Name字段的性能
- A . 在Name字段上添加主键
- B. 在Name字段上添加索引
- C. 在Age字段上添加主键
- D. 在Age字段上添加索引
8. Ip地址131.153.12.71是一个什么类的Ip地址
- A. A
- B. B
- C. C
- D. D
解析
IP地址分类 :
A类网络的IP地址范围为1.0.0.1-127.255.255.254;
B类网络的IP地址范围为:128.1.0.1-191.255.255.254;
C类网络的IP地址范围为:192.0.1.1-223.255.255.254。
9. 浏览器访问某页面,HTTP协议返回状态码为403时表示
- A. 找不到该页面 404
- B. 禁止访问 403
- C. 内部服务器访问
- D. 服务器繁忙 500 内部错误
10. 如果某系统15*4=112成立,则系统采用的是几进制
- A. 6
- B. 7
- C. 8
- D. 9
解析:假设X进制,则(x+5) * 4 = 1* x^2+1*x^1+1*x^0 --> 6
11. TCP和IP分别对应了OSI中哪几层

12. 同一进程下的线程可以共享
- A. stack
- B. data section
- C. register set
- D. file fd
解析:
线程共享的内容包括
- 进程代码段
- 进程的公有数据(利用这些共享的数据,线程很容易的实现相互之间的通讯)
- 进程打开的文件描述符、信号的处理器、进程的当前目录和进程用户ID与进程组ID
线程独有的内容包括:
- 线程id
- 寄存器组的值
- 线程的堆栈
- 错误返回码
- 线程的信号屏蔽码
13. 对于派生类的构造器,在定义对象时构造函数的执行顺序为
成员对象的构造函数
基类的构造函数
派生类本身的构造函数
- A. 123
- B. 231
- C. 321
- D. 213
解析类:
- 派生类:子类
- 基类:又称父类
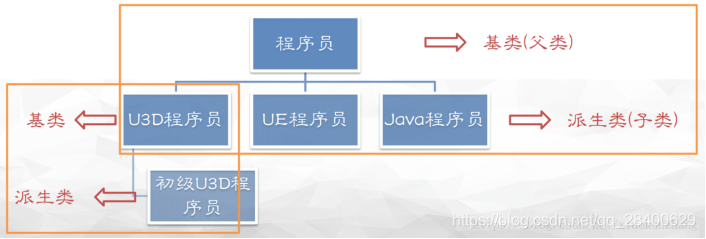
当派生类中不含对象成员时
- 在创建派生类对象时,构造函数的执行顺序是:基类的构造函数→派生类的构造函数;
- 在撤消派生类对象时,析构函数的执行顺序是:派生类的构造函数→基类的构造函数。
当派生类中含有对象成员时
- 在定义派生类对象时,构造函数的执行顺序:基类的构造函数→对象成员的构造函数→派生类的构造函数;
- 在撤消派生类对象时,析构函派生类的构造函数→对象成员的构造函数→基类的构造函数。
13. 递归函数最终回结束,那么这个函数一定
- A. 使用局部变量
- B. 有一个分支不调用自身
- C. 使用全局变量或者使用了一个或多个参数
- D. 没有循环调用
解析:递归函数一定要有终止条件,一般时if判断,并不在调用自身
14. 编译过程,语法分析器的任务是
- A. 分析单词是怎样构成的
- B. 分析单词串是如何构成语言和说明的
- C. 分析语句和说明是如何构成程序
- D. 分析程序的结构
解析
- 词法分析:词法分析是编译过程的第一个阶段。这个阶段的任务是从左到右的读取每个字符,然后根据构词规则识别单
词
-
语法分析:语法分析是编译过程的一个逻辑阶段。语法分析在词法分析的基础上,将单词序列组合成各类语法短语,如 “程序”,“语句”,“表达式”等等。语法分析程序判断程序在结构上是否正确
-
语义分析:属于逻辑阶段。对源程序进行上下文有关性质的审查,类型检查。如赋值语句左右端类型匹配问题。
15. 进程进入等待状态有哪几种方式
- A. CPU调度给优先级更高的线程
- B. 阻塞的线程获得资源或者信号
- C. 在时间片轮转的情况下,如果时间片到了
- D. 获得spinlock未果
解析:
进程分为基本的三个状态:运行、就绪、阻塞/等待。
- 高优先级的抢占CPU,使得原来处于运行状态的进程转变为就绪状态
- 阻塞的进程等待某件事情的发生,一旦发生则它的运行条件已经满足,从阻塞进入就绪状态
- 时间片轮转使得每个进程都有一小片时间来获得CPU运行,当时间片到时从运行状态变为就绪状态。
- 自旋锁(spinlock)是一种保护临界区最常见的技术。在同一时刻只能有一个进程获得自旋锁,其他企图获得自旋锁的任何进程将一直进行尝试(即自旋,不断地测试变量),除此以外不能做任何事情。因此没有获得自旋锁的进程在获取锁之前处于忙等(阻塞状态)
16.
结构型模式:

行为型模式


并发型模式



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









