







 本文介绍如何下载特定区域的百度街景照片,包括从OSM获取路网数据,采用ArcPy进行采点,WGS84到百度墨卡托坐标转换,获取全景图ID和元数据,最后下载全景图。
本文介绍如何下载特定区域的百度街景照片,包括从OSM获取路网数据,采用ArcPy进行采点,WGS84到百度墨卡托坐标转换,获取全景图ID和元数据,最后下载全景图。
下载特定区域内百度街景照片数据
本文是在康博的博文的基础上再整理的。
01 下载路网数据
基本上都是使用 Open Street Map (OSM) 的路网数据。下载 OSM 数据的方法有很多,这里就不再赘述。
我个人是使用 OpenStreetMap Data Extracts 下载了整个中国的数据,然后用研究区的边界数据进行了裁剪。具体是使用了 ArcGIS 的 (ArcToolbox - Analysis Tools - Extract - Clip) 工具进行的裁剪。
02 对道路进行采点
使用 Ian Broad 开发的 Create Points on Polylines with ArcPy 工具箱进行采点。可以去工具箱的链接下载 tbx 文件,然后把文件复制到
C:\Users\Ivy\AppData\Roaming\ESRI\Desktop10.5\ArcToolbox\My Toolboxes
文件夹即可,在 Catalog 看到新下载的工具箱(上面的路径需要自己改一下,特别是用户名!)。
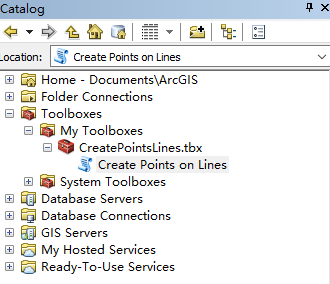
运行 CreatePointsLines 工具,设置参数,类型可以选“INTERVAL BY DISTANCE",然后 Distance 字段填 0.00001。这样大概就是每条路间隔 1 米取一个点。
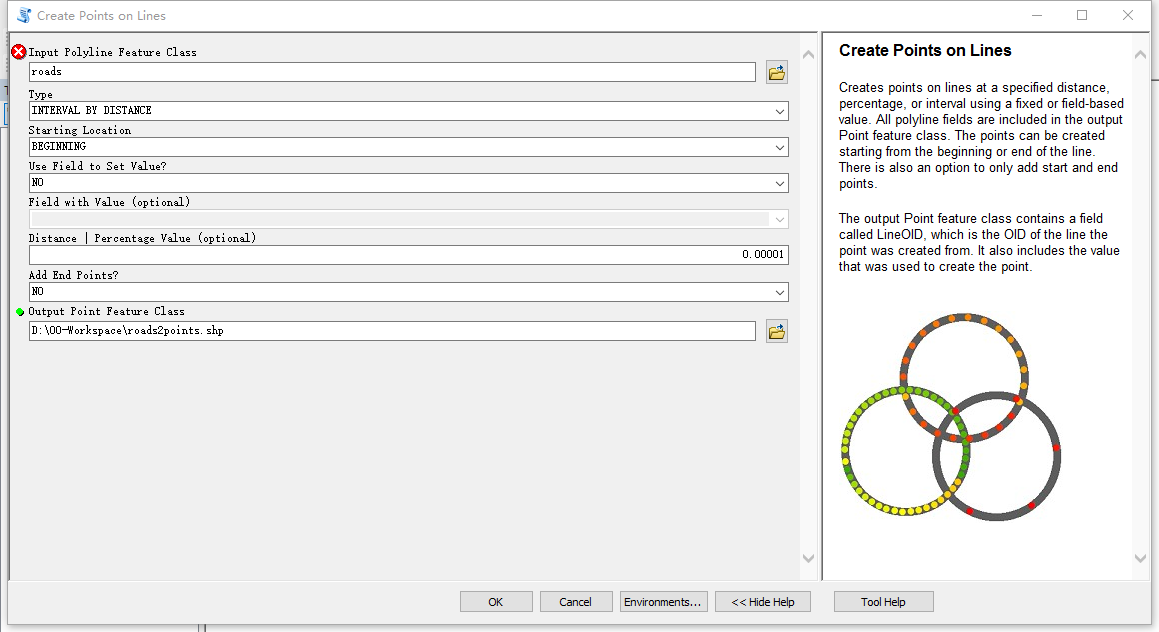
然后在属性表里新建经纬度的字段
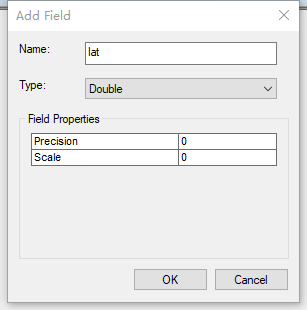
然后对字段进行【计算几何】的操作,把经纬度给算出来。
(康博的博文是把坐标系转换为了 wgs84 的 web 墨卡托坐标,但是我验证了一下,这个墨卡托坐标和百度使用的平面墨卡托坐标不是一致的,所以这里还是先输出 wgs84 的坐标,后面使用百度的 api 转换为 bd09mc。)
然后把属性表导出为 txt 文件。(不要导出为 dbf 文件,转换还挺麻烦的,用 python 的话需要额外的库,用 excel 的话数据量太大会打不开(excel 有行数限制))
接着把导出的点使用下面的代码存入数据库,我使用的是 mongodb。
import pandas as pd
import pymongo
df = pd.read_csv("../maps/points.txt")
new_df = df[["lon", "lat"]] # 只要坐标列
new_df = new_df[(new_df["lon"] != 0) & (new_df["lat"] != 0)] # 删除计算错误的点
new_df["wgs84"] = new_df["lon"].map(str)+","+new_df["lat"].map(str)
new_df["ok"] = 0
del new_df["lon"], new_df["lat"]
print(new_df.shape)
# 把读出来的 dataframe 转化为 dict,形式为[{"wgs84": "x,y", "ok": 0}, ...]
data = new_df.to_dict(orient = 'records')
# 存入数据库
client = pymongo.MongoClient("mongodb://localhost:27017/")
db = client["area"]
col = db["rpoints_wgs84"]
col.insert_many(data)数据库内的形式大概是如下所示。ok 字段是记录状态的。因为当点很多的时候,可能由于意外导致程序崩溃或者打断,而不知道程序的进度来重新启动。
03 WGS84 转换为百度墨卡托坐标
使用百度官方的 api 把 wgs84 坐标系转换为百度墨卡托坐标。
需要使用百度的开发者 ak,我是创建了一个形如下面这样的 json 文件来存储可用的 ak,方便程序调用。
{
"ak": [
"ak1",
"ak2"
]
}转换坐标的代码如下。因为 api 一次可以接收 100 个点,所以用到了均分列表的函数。
import requests, json
import pymongo
import sys, traceback
import random, time
from tqdm import tqdm
def convert_points(point):
# 每次 100 个点
coords = ";".join(point)
url = "http://api.map.baidu.com/geoconv/v1/?coords={}&from=1&to=6&ak={}".format(coords, random.choice(aks))
while True:
try:
res = requests.get(url)
data = res.json()
if data["status"] == 0:
return data["result"]
else:
print(data)
except (requests.exceptions.ConnectionError, json.decoder.JSONDecodeError) as e:
print("\n Error: ", repr(e))
except:
print("\n ************************ Alert!! ********************************")
traceback.print_exc()
return False
def write_data(mc_point):
client = pymongo.MongoClient("mongodb://localhost:27017/")
db = client["area"]
col = db["rpoints_mc"]
data = []
for point in mc_point:
data.append({"bd09mc": "{},{}".format(point["x"], point["y"]), "ok": 0})
now = time.time()
print("Ready to insert data")
while True:
try:
if len(data) <= 1000:
col.insert_many(data)
else:
groups = split_list(data, n=1000)
for group in groups:
col.insert_many(group)
print("Inserting data used", time.time()-now,"s")
break
except:
traceback.print_exc()
sys.exit(1)
def split_list(l, n=100):
# 均分列表
new_l = []
for i in range(0,len(l),n):
new_l.append(l[i:i+n])
return new_l
def get_points():
client = pymongo.MongoClient("mongodb://localhost:27017/")
db = client["area"]
col = db["rpoints_wgs84"]
docs = col.find({"ok": 0})
points = [doc["wgs84"] for doc in docs]
return points
if __name__=="__main__":
## 读取出点坐标
wgs_points = get_points()
points_groups = split_list(wgs_points)
print("There're", len(points_groups), "groups")
## 读取出备用的 ak
with open("ak.json", 'r', encoding='utf8') as f:
j = json.load(f)
aks = j["ak"]
valid_points = []
for wgs_point in tqdm(points_groups, ncols=80):
while True:
mc_point = convert_points(wgs_point)
if mc_point:
valid_points += mc_point
break
write_data(valid_points)04 获取全景图 id
这时,使用的是一个非官方的链接来访问这个坐标点是否存在全景图(不同坐标点可能存在同一全景图)。
https://mapsv0.bdimg.com/?qt=qsdata&x={}&y={}返回的是 json 数据,含有全景图的 id。
使用下面的代码多线程爬取全景图 id,并存入数据库,这里仍然使用的是 mongdb。
import pymongo
import threading
from queue import Queue
from threading import Thread
import requests, urllib3
from requests.adapters import HTTPAdapter
from requests.packages.urllib3.util.retry import Retry
import sys, traceback
from fake_useragent import UserAgent # 构造假的 Headers
from ippool.ippool_fast import * # 自己写的代理池的包
import time
import random
class Spider():
def __init__(self):
self.thread_num = 10
self.start = time.time()
self.all_panoids = self.get_panoids()
# 各种队列
self.point_q = self.get_points() # 待确认的点的队列
self.all_lenth = self.point_q.qsize() # 队列总长度
self.finish_q = Queue(100000) # 已经确认的点的队列
self.panoid_q = Queue() # 全景图id队列
self.ippool_q = Queue() # 代理池队列
def get_points(self):
client = pymongo.MongoClient("mongodb://localhost:27017/")
db = client["area"]
col = db["rpoints_mc"]
docs = col.find({"ok": 0})
point_q = Queue()
for doc in docs:
point_q.put(doc["bd09mc"])
return point_q
def get_panoids(self):
client = pymongo.MongoClient("mongodb://localhost:27017/")
db = client["area"]
col = db["streetview"]
docs = col.find()
if docs:
print(len(list(docs)))
panoids = [doc["panoid"] for doc in docs]
return panoids
return []
def writeData(self, panoids):
client = pymongo.MongoClient("mongodb://localhost:27017/")
db = client["area"]
col = db["streetview"]
docs = []
for panoid in panoids:
docs.append({"panoid": panoid,
"bd09mc": "",
"bd09ll": "",
"wgs84": "",
"date": "",
"ok": 0,
"info": {}})
col.insert_many(docs)
def req(self, url):
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "en-US,en;q=0.9",
"DNT": "1",
"Host": "mapsv0.bdimg.com",
" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 224
224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









