







上一节,我尝试了构建悟空的微调数据集(InternLM微调孙悟空卖货主播模型(一):数据集生成-优快云博客),构建好数据集之后,我们本节尝试使用xtuner对模型进行微调,使用swanlab对过程进行可视化,这里基座模型选用InternLM2-7B模型。
环境准备
免费GPU资源
- modelscope 魔搭社区
给的开发资源还挺好用的,缺点是给的服务器只能保存.ipynb文件,其他文件重新开机之后就会丢失。不过对于白嫖党已经很友好了
- 阿里云dsw 阿里云免费试用 - 阿里云


环境配置
anaconda安装
# 下载anaconda安装包
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
# 增加运行权限
chmod +x Miniconda3-latest-Linux-x86_64.sh
# 运行安装脚本
./Miniconda3-latest-Linux-x86_64.sh创建虚拟环境
# 创建虚拟环境
conda create -n wukong python=3.10 -y
# 激活虚拟环境
source activate wukong关键的第三方包安装
# 安装一些必要的库
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia -y
# 安装其他依赖
pip install transformers==4.43.3
pip install streamlit==1.37.0
pip install huggingface_hub==0.24.3
pip install openai==1.37.1
pip install lmdeploy==0.5.2
pip install swanlab
# modelscope
pip install modelscope模型下载
创建一个文件夹作为所有操作的根目录
mkdir wukong
cd wukong用如下脚本,下载Interlm2
import os
from modelscope.hub.snapshot_download import snapshot_download
snapshot_download("Shanghai_AI_Laboratory/internlm2-chat-7b",
cache_dir=r"InternML2",
)模型测试
用微调之前的模型进行问答方便微调后的模型进行对比,使用lmdepl将模型部署为openai的模型接口形式
CUDA_VISIBLE_DEVICES=0 lmdeploy serve api_server /model/Shanghai_AI_Laboratory/internlm2-chat-1_8b --server-port 23333 --api-keys internlm2
构建使用streamlit构建一个简单的前端,测试。代码如下:
import streamlit as st
from openai import OpenAI
import os
import json
import time
def side_bar():
# 设置聊天机器人的侧边
st.sidebar.title("设置")
state=st.session_state
# 配置表单
with st.sidebar.form(key='settings'):
# 设置最大长度
max_tokens=st.number_input("最大token长度",min_value=0,max_value=2048,value=100,step=1)
# 设置温度
temperature=st.number_input("Temperature",min_value=0.0,max_value=1.0,value=0.0,step=0.01)
# 设置对应的openai服务的key
api_key=st.text_input("API Key",value="internlm2")
# 设置调用的接口地址
base_url=st.text_input("Base URL",value="http://0.0.0.0:23333/v1")
# 设置系统提示词
system_prompt=st.text_area("系统提示",value="")
# 添加提交按钮
submit=st.form_submit_button("保存设置")
# 如果点击提交按钮,保存设置
if submit:
if max_tokens!=0:
state.max_tokens=max_tokens
state.api_key=api_key
state
state.temperature=temperature
state.api_key = api_key
state.base_url = base_url
state.message_history=[]
if system_prompt!="":
state.system_prompt=system_prompt
state.message_history.append({"role":"system","content":system_prompt})
state.client=OpenAI(api_key=state.api_key,base_url=state.base_url)
pass
if st.sidebar.button("开启新对话"):
if not os.path.exists("chat_history"):
os.mkdir("chat_history")
pass
with open(f"chat_history/{time.time()}.json",'w') as f:
json.dump(state.message_history,f,ensure_ascii=False)
pass
state.message_history=[]
st.rerun()
# print(f"侧边设置的state:{state}")
pass
def chat_ui():
state = st.session_state
# Set the title of the app
st.title("悟空卖货模型测试")
st.caption("悟空卖货模型测试")
print(state)
# Create a client for the OpenAI API
if "client" not in state:
st.info("请配置Chatbot的基本设置,其中API Key和Base URL是必须的。")
pass
else:
user_input = st.chat_input("输入消息")
if user_input:
state.message_history.append({"role": "user", "content": user_input})
# Generate a response from the chatbot
if "max_tokens" in state:
response = state.client.chat.completions.create(
model=state.client.models.list().data[0].id,
messages=state.message_history,
max_tokens=state.max_tokens,
temperature=state.temperature
)
else:
response = state.client.chat.completions.create(
model=state.client.models.list().data[0].id,
messages=state.message_history,
temperature=state.temperature
)
state.message_history.append({"role": "assistant", "content": response.choices[0].message.content})
pass
for message in state.message_history:
if message["role"] == "system":
continue
else:
st.chat_message(message["role"]).write(message["content"])
# Create a text input for the user to type their message
pass
if __name__ == '__main__':
side_bar()
chat_ui()

使用Xtuner进行微调
Xtuner安装
在文件下创建一个code文件夹,用于存放Xtuner的源码
mkdir code
cd code
git clone -b v0.1.21 https://github.com/InternLM/XTuner /mnt/workspace/wukong/code/XTuner
# 进入Xtuner
cd Xtuner
# 执行安装
pip install -e '.[deepspeed]'配置文件准备
Xtuner中提供了很多开箱即用的配置文件,通过以下的语法将配置文件罗列出来
xtuner list-cfg -p internlm2
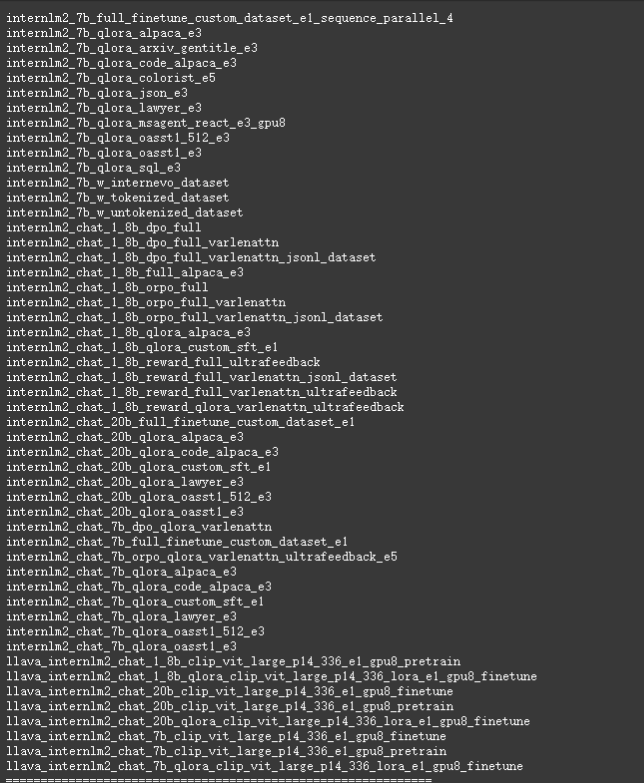
从配置文件中没有找到大佬的配置文件,所以这里使用的是:internlm2_chat_7b_qlora_oasst1_e3.py.
将配置文件拷贝到当前路径
xtuner copy-cfg internlm2_chat_7b_qlora_oasst1_e3 .配置文件的修改如下所示
- 模型部分

这里主要是修改的是模型和数据集的地址,以及batch_size的大小(主要根据显存大小调整,我最大只能设置为3),save_steps:设置成50,每50轮保存一次模型,evaluation_inputs,我这里设置了三段提问,主要是为了测试当前微调的模型在这三个问题上的回答效果
- 数据部分
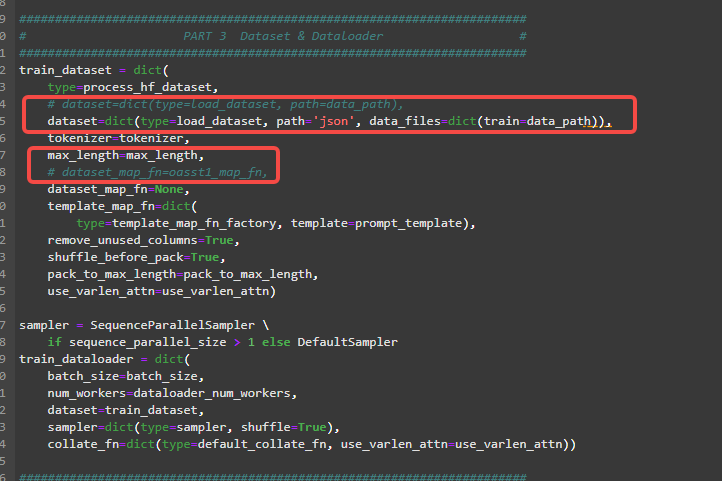
- 运行部分
这里添加了swanlab的可视化部分
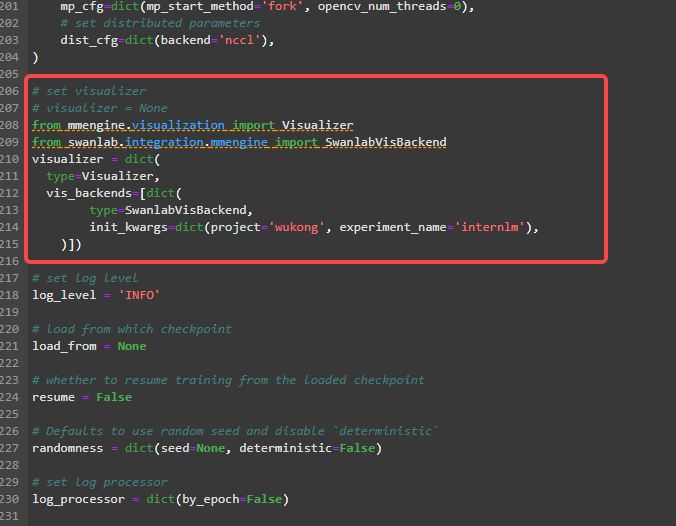
添加swanlab可视化部分
from mmengine.visualization import Visualizer
from swanlab.integration.mmengine import SwanlabVisBackend
visualizer = dict(
type=Visualizer,
vis_backends=[dict(
type=SwanlabVisBackend,
init_kwargs=dict(project='wukong', experiment_name='internlm'),
)])启动微调
xtuner train internlm2_chat_7b_qlora_oasst1_e3_copy.py --deepspeed deepspeed_zero2
可视化
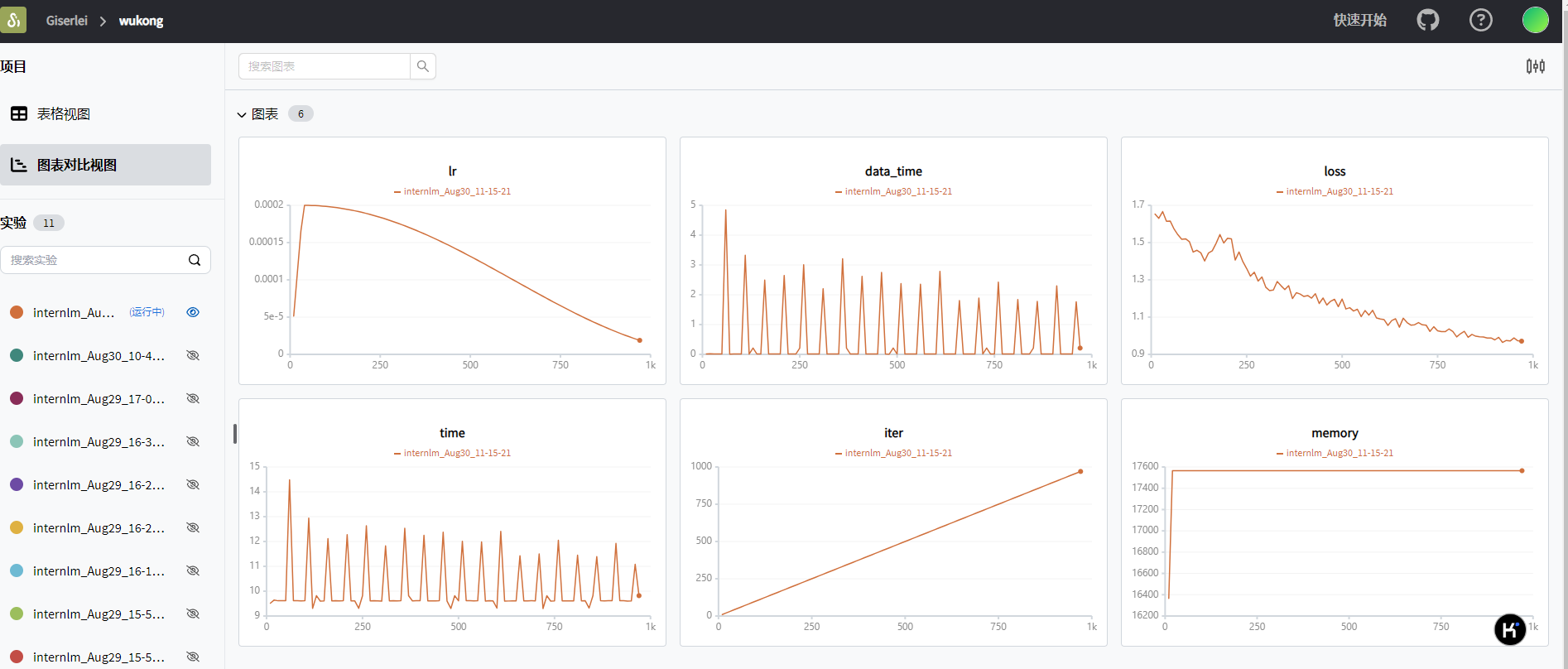
模型格式转换与合并
需要将模型从pth装维HF格式,再与原来的模型合并成一个完整的模型,为例加快推理速度使用lmdeploy对模型进行4bit量化。
- 格式转换
将pytorch训练的模型权重文件转换为目前通用的HuggingFace格式的文件
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER=GNU
xtuner convert pth_to_hf internlm2_chat_7b_qlora_oasst1_e3_copy.py /mnt/workspace/wukong/work_dirs/internlm2_chat_7b_qlora_oasst1_e3_copy/iter_1200.pth ./hf- 模型合并
将微调生成的权重模型和原来的模型合并到一起
xtuner convert merge /mnt/workspace/wukong/InternML2/Shanghai_AI_Laboratory/internlm2-chat-7b ./hf ./merged --max-shard-size 2GB
模型测试结果
CUDA_VISIBLE_DEVICES=0 lmdeploy serve api_server /mnt/workspace/wukong/internlm2-chat-7b --server-port 23333 --api-keys internlm2这里有个小bug,部署的时候要将模型的文件夹名称改成”internlm2-chat-7b“否则会报错。
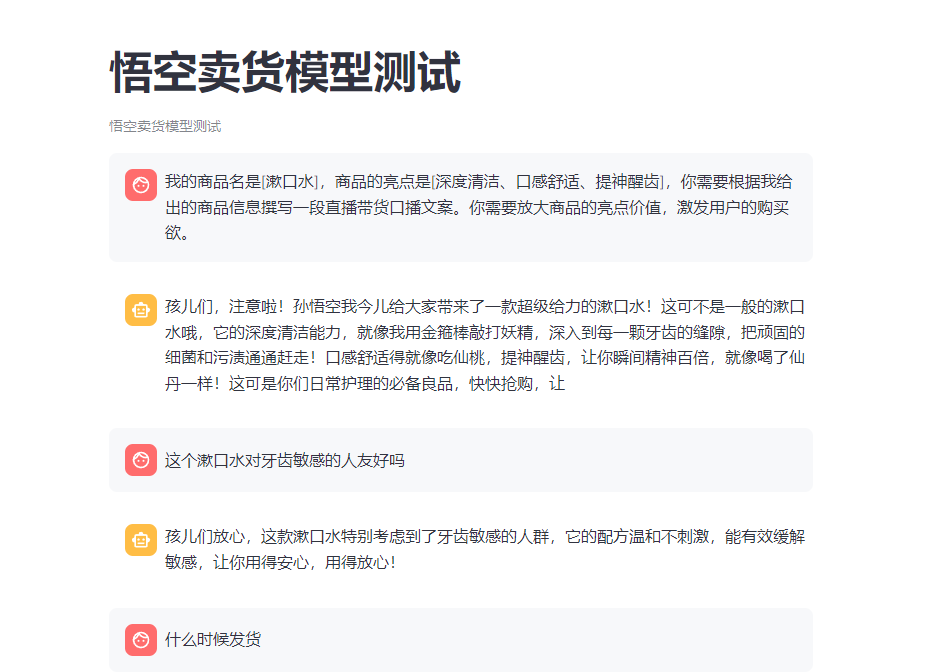
- 模型微调中的问题
- 数据量问题:上一节的数据集准备的数据量不够,微调效果不好,于是我简单粗暴的将数据集复制进行数据扩充
- 需要添加系统提示词,否则模型的回答效果不是很好
- 自我认知问题:自我认知数据集太少,需要增加更多的数据,
以上微调一个悟空卖货主播的微调结果,由于设备以及数量的原因,没有能够进行充分的训练(GPU太贵啦),后面将会后面将会介绍TTS,将文字转成孙悟空的语音。
参考:
- GitHub - PeterH0323/Streamer-Sales: Streamer-Sales 销冠 —— 卖货主播 LLM 大模型🛒🎁,一个能够根据给定的商品特点从激发用户购买意愿角度出发进行商品解说的卖货主播大模型。🚀⭐内含详细的数据生成流程❗ 📦另外还集成了 LMDeploy 加速推理🚀、RAG检索增强生成 📚、TTS文字转语音🔊、数字人生成 🦸、 Agent 使用网络查询实时信息🌐、ASR 语音转文字🎙️
- Tutorial/docs/L1/XTuner at camp3 · InternLM/Tutorial · GitHub
- Xtuner | SwanLab官方文档



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









