







 本文详细介绍了Python机器学习中的三种聚类算法:K均值聚类、凝聚聚类和DBSCAN。K均值通过迭代找到数据点的均值作为聚类中心,适合简单形状的数据;凝聚聚类自下而上合并相似聚类,形成层次结构;DBSCAN基于密度划分聚类,能处理复杂形状数据并自动识别噪声。
本文详细介绍了Python机器学习中的三种聚类算法:K均值聚类、凝聚聚类和DBSCAN。K均值通过迭代找到数据点的均值作为聚类中心,适合简单形状的数据;凝聚聚类自下而上合并相似聚类,形成层次结构;DBSCAN基于密度划分聚类,能处理复杂形状数据并自动识别噪声。
1.K均值聚类
1.K均值聚类的工作原理:
假设我们的数据集中的样本因为特征不同,像下沙堆一样散步在地上,K均值算法会在小沙堆上插上旗子。而第一遍插的旗子并不能完美地代表沙堆的分布,所以K均值还要继续,让每个旗子能够插入到每个沙滩最佳的位置上,也就是数据点的均值上,这就是K均值算法名字的由来。接下来会一直重复上述的步骤,直到找不到更好的位置。如下图所示:
尝试用手工生成的数据集展示一下K均值聚类算法工作原理:
from sklearn.datasets import make_blobs
blobs = make_blobs(random_state=1,centers=1)
X=blobs[0]
plt.scatter(X[:,0],X[:,1],c='r',edgecolor='k')
plt.show()
运行代码,如下图所示:
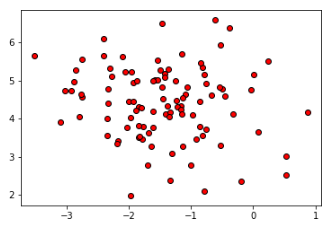
结果分析:由于代码里指定了make_blobs的centers参数为1,因此所有的数据都属于1类,并没有差别
下面使用K均值帮助这些数据进行聚类:
import numpy as np
 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1253
1253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











