




 探讨了众包中上下文敏感任务(CST)的质量控制问题,提出了一种结合上下文信息的迭代推理算法,实验证明该方法优于现有技术。
探讨了众包中上下文敏感任务(CST)的质量控制问题,提出了一种结合上下文信息的迭代推理算法,实验证明该方法优于现有技术。
Context-aware result inference in crowdsourcing
作者
Yili Fang
a
,
b
^{a , b}
a,b, Hailong Sun
a
,
b
^{a , b}
a,b, ∗, Guoliang Li
c
^{c}
c , Richong Zhang
a
,
b
^{a , b}
a,b, Jingpeng Huai
a
,
b
^{a , b}
a,b
a
^a
aSKLSDE Lab, School of Computer Science and Engineering, Beihang University, Beijing 100191, China
b
^b
bBeijing Advanced Innovation Center for Big Data and Brain Computing, Beijing 100191, China
c
^c
cDepartment of Computer Science, Tsinghua University, Beijing, China
摘要
针对众包质量控制问题,提出了多种结果推理方法。然而,现有的方法对于上下文敏感任务(Context-Sensitive Task,CST)无效,例如手写识别、翻译、语音转录,因为两个原因不能忽略任务中的上下文关联。首先,由于要正确完成一个复杂的任务相当困难,因此将整个 C S T \mathrm{CST} CST(如识别手写文本)挤在一起并使用任务级推理方法来推理答案是无效的。其次,虽然 C S T \mathrm{CST} CST由一组原子子任务组成(例如,识别手写字),但不适合将其拆分为多个子任务,并采用子任务级推理算法来推理结果,因为这样会丢失子任务之间的上下文关联性(例如,短语),增加完成任务的难度。因此,它需要一种处理 C S T \mathrm{CST} CST的新方法。本文研究了 C S T \mathrm{CST} CST的结果推理问题,提出了一种上下文感知的推理算法。结合上下文信息,设计了一种推理算法。此外,我们还引入了一种迭代的方法来提高质量。在实际 C S T \mathrm{CST} CST上的实验结果表明,我们的方法与目前最先进的方法相比具有优越性。
1 介绍
众包旨在利用群体的智慧来解决计算机难以解决的问题[2]。在许多应用中,特别是在数据管理[25]领域,其成功表现在从简单任务(如图像标记[10,21]和实体分辨[38])到复杂任务(如文本编辑[4]和软件开发[19])的各种应用中。
由于工人可能返回噪音结果,众包的核心问题是确保结果质量[25]。结果推理是一种广泛采用的控制质量的方法,它首先将每个任务分配给多个工人,然后使用推理算法对分配的工人的结果进行汇总。以图像标签为例。图像被分配给多个工人,他们将提供描述图像内容的标签。最后的结果是通过投票[40]或其他推理方法[41]从所有收集的标签中选择标签的子集。
在众包中,有一个重要的任务类别,由一组上下文关联的子任务组成,例如手写识别[7]、翻译[47]、路线规划[45]和音频转录[34]。在这项工作中,我们称这种众包任务为上下文敏感的任务(即
C
S
T
\mathrm{CST}
CST)。例如,图1(a)显示了手写识别的示例,要求工人识别由多个单词组成的手写句子。一个句子中的词在对应句子所确定的一致语义环境中有着密切的联系。因此手写识别是一种典型的
C
S
T
\mathrm{CST}
CST。然而,对于结果推理,现有的方法对于上下文敏感任务(
C
S
T
\mathrm{CST}
CST)并不有效。一方面,
C
S
T
\mathrm{CST}
CST相当困难,每个工人都无法正确回答整个任务(例如,正确识别一个句子中的所有单词用于手写识别任务)。图1(b)说明了三个工人给出的答案,每个答案都是完全或部分被认可的句子。任何工人都不能正确识别这个句子。因此,对于任务级推理算法[18,38,48],它将每个完整任务分配给不同的工人,并汇总每个任务的答案,很难从单个工人那里获得高质量的答案。另一方面,每个任务在其子任务之间都有内部上下文关联。例如,一个句子中的单词不是独立的,它们在上下文中相互关联。显然,在结果推理中不能忽略上下文。例如,单词3-5的第二个答案是“misspelled several words”,而第三个答案是“misspelled several works”。显然,第二个答案更为合理,因为“misspelled”与“several words”比“several works”更为密切关联。此外,假设另一个工人将单词3-5识别为“拼写错误的多个作品”。如果忽略上下文关联,基于投票的推理可能会将“misspelled several works”视为最终结果,这显然是错误的。因此,子任务级推理算法[4,38,44]将每个任务拆分为多个子任务,并从工作人员那里聚合每个子任务的答案,也不有效。因此,这两种方法都不适用于
C
S
T
\mathrm{CST}
CST,因为它们不使用上下文关联来共同考虑结果推理中已识别的答案。
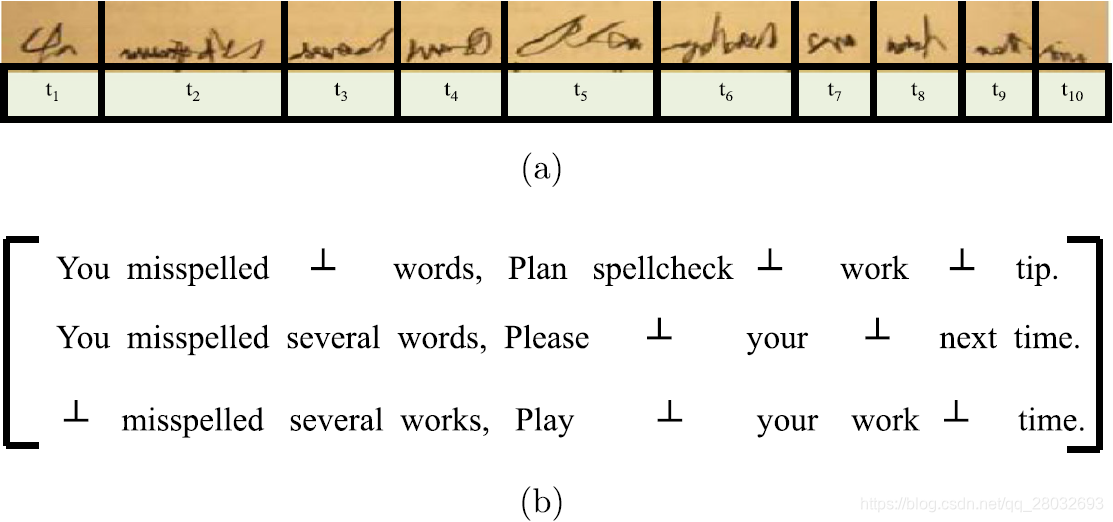
图1. CST任务 (a)手写识别任务 (b)三名工人提供的答案
处理 C S T \mathrm{CST} CST有两个主要挑战。
- 首先,捕获上下文关联是非常重要的,因为 C S T \mathrm{CST} CST通常不包含足够的信息。这就带来了一个挑战,即对上下文关联进行建模,用稀疏信息解决模型,并推理出高质量的答案。
- 第二, C S T \mathrm{CST} CST比简单的任务更复杂,一次迭代通常无法获得高质量的结果。为了解决这两个难题,
我们研究了两个问题:结果推理和迭代决策。前者的目的是从工人提交的答案中推理出最佳结果,后者主要检查推理结果是否可以进一步改进:如果结果足够好,迭代过程将终止;否则将开始新的迭代。
在这项工作中,我们提出了一种上下文感知的推理方法来提高 C S T \mathrm{CST} CST的质量。首先,我们使用隐马尔可夫模型(HMM)[15,33]来描述上下文关联和设计上下文感知推理算法(Context-Inf)。特别是,我们结合外部知识来解决缺乏上下文关联信息的挑战。然后,我们建议使用上下文信息支持众包的迭代改进。综上所述,我们做出如下贡献:
- 我们确定了众包任务的一个重要类别,即上下文敏感任务( C S T \mathrm{CST} CST)。据我们所知,这是第一次尝试研究上下文感知推理。
- 我们建立了一个描述 C S T \mathrm{CST} CST众包过程的概率模型,提出了将HMM与外部知识结合到MLE和EM算法中的上下文信息来推理结果。
- 对于复杂的 C S T \mathrm{CST} CST,我们设计了一个基于 P O M D P \mathrm{POMDP} POMDP的迭代决策模型来提高质量。
- 我们对两种 C S T \mathrm{CST} CST进行了广泛的实验:手写识别和音频转录。实验结果表明了该方法的优越性。
2 问题公式化
在本节中,我们首先介绍表1中所用的符号,并将本文研究的主要问题公式化。上下文敏感任务( C S T \mathrm{CST} CST)包含多个子任务,这些子任务与特定上下文关联。关键问题是尽可能地推理出高质量 C S T \mathrm{CST} CST的结果。如果拆分( C S T \mathrm{CST} CST)的这些子任务,则上下文将丢失。例如,图1(a)显示了一个上下文敏感的任务,即手写识别。如果将手写句子拆分为10个子任务(如单词),则由于上下文关联性的丢失,识别难度会增加。
表1.符号说明
| 符号 | 描述 |
|---|---|
| A \mathcal{A} A | HMM的状态转移矩阵 |
| B \mathcal{B} B | HMM的输出概率矩阵 |
| π \pi π | HMM的初始状态概率 |
| λ \lambda λ | 隐马尔可夫模型 λ = ( A , B , π ) \lambda=(\mathcal{A},\mathcal{B},\pi) λ=(A,B,π) |
| T \mathrm{T} T | 一个上下文敏感任务 |
| T ′ \mathrm{T'} T′ | 一个带有真值标签的测试任务 |
| o i j T o_{ij}^\mathrm{T} oijT | 工人 i i i提交的 T \mathrm{T} T的子任务 j j j的输出 |
| O T O^\mathrm{T} OT | C S T T \mathrm{CST\ T} CST T的输出矩阵 O T = { o i j T } O^T=\{o_{ij}^T\} OT={oijT} |
| K j T K_j^\mathrm{T} KjT | 子任务 j j j的候选回答集合 |
| k i j T k_{ij}^\mathrm{T} kijT | 子任务 j j j在 T \mathrm{T} T中的第 i i i个候选答案 |
| z j T z_j^\mathrm{T} zjT | 子任务 j j j的真值标签 |
| Z T Z^\mathrm{T} ZT | C S T T \mathrm{CST\ T} CST T的真值标签 |
| Γ \Gamma Γ | 测试任务集合 Γ = { ( T ′ , Z T ′ ) } \Gamma=\{(\mathrm{T'},Z^{\mathrm{T'}})\} Γ={(T′,ZT′)} |
| C T \mathrm{C_T} CT | C S T T \mathrm{CST\ T} CST T的一个候选输出向量 |
| C T \mathcal{C}^\mathrm{T} CT | 所有可能 C O V \mathrm{COV} COV的集合 C T = { C T } \mathcal{C}^\mathrm{T}=\{\mathrm{C_T}\} CT={CT} |
| d j T d_j^\mathrm{T} djT | 子任务的难度 d j T ∈ [ 0 , 1 ] d_j^\mathrm{T}\in[0,1] djT∈[0,1] |
| D T D^\mathrm{T} DT | C S T \mathrm{CST} CST的难度 D T = { d j T } D^\mathrm{T}=\{d_j^\mathrm{T}\} DT={djT} |
| w i T w_i^\mathrm{T} wiT | 准确度参数 w i ∈ [ 1 , + ∞ ] w_i\in[1,+\infty] wi∈[1,+∞] |
| W T W^\mathrm{T} WT | 回答 T \mathrm{T} T的工人准确度参数集合 |
| c T l c_\mathrm{T}^l cTl | C S T T \mathrm{CST\ T} CST T的第 l l l个 C O V \mathrm{COV} COV |
| s i m ( k i j T , k i ′ j T ) sim(k_{ij}^\mathrm{T},k_{i'j}^\mathrm{T}) sim(kijT,ki′jT) | 候选结果 k i j T k_{ij}^\mathrm{T} kijT和 k i ′ j T k_{i'j}^\mathrm{T} ki′jT之间的原始相似度 |
| θ ( k i ′ ′ j T , k i ′ j T ) \theta(k_{i''j}^\mathrm{T},k_{i'j}^\mathrm{T}) θ(ki′′jT,ki′jT) | 两个错误结果 k i ′ ′ j T k_{i''j}^\mathrm{T} ki′′jT和 k i ′ j T k_{i'j}^\mathrm{T} ki′jT之间的归一化距离 |
| δ \delta δ | 一个克罗内克函数(Kronecker Delta Function) |
| l T ′ l_\mathrm{T'} lT′ | 一个测试任务 T ′ \mathrm{T'} T′的对数似然函数 |
| L Γ L_\Gamma LΓ | 一个测试任务集合 Γ \Gamma Γ的对数似然函数 |
| P k i j T P^{k_{ij}^\mathrm{T}} PkijT | k i j T k_{ij}^\mathrm{T} kijT是正确结果的概率 |
| Q Q Q | EM算法的辅助函数 |
| b k i j ( O ∗ j ) b_{k_{ij}}(O_{*j}) bkij(O∗j) | C o n t e x t − I n f \mathrm{Context-Inf} Context−Inf模型的输出概率 |
给定一个带有 m m m个子任务的 C S T T \mathrm{CST\ T} CST T,每个子任务分配给 n n n个工人,我们使用一个输出矩阵来表示这些工人的答案。
定义1(输出矩阵,Output Matrix)。 n n n个工人对于 T \mathrm{T} T的回答表示为一个 n × m n\times m n×m矩阵, O T = ( o i j T ) n × m O^\mathrm{T}=(o_{ij}^\mathrm{T})_{n\times m} OT=(oijT)n×m,其中 o i j T o_{ij}^\mathrm{T} oijT是工人 i i i对子任务 j j j的输出,如果工人 i i i没有提供子任务 j j j输出,则 o i j T = ⊥ o_{ij}^\mathrm{T}=\perp oijT=⊥,我们用 O ∗ j T O_{*j}^\mathrm{T} O∗jT表示子任务 j j j的输出向量,用 O i ∗ T O_{i*}^\mathrm{T} Oi∗T表示工人 i i i的输出向量。
注意,当且仅当工人 i i i无法处理子任务 j j j时 o i j T o_{ij}^\mathrm{T} oijT是 ⊥ \perp ⊥。例如,图1(b)说明了图1(a)中手写识别 C S T T \mathrm{CST\ T} CST T的输出矩阵。 o 31 T = ⊥ o_{31}^\mathrm{T}=\perp o31T=⊥因为第三个工人不能识别第一个词。为了生成 T \mathrm{T} T的推理结果,我们定义了候选输出向量来表示推理结果。
定义2(候选输出向量,Candidate Output Vector–COV)。 O ∗ j T O_{*j}^\mathrm{T} O∗jT表示子任务 j j j的输出向量。 K j T = { k i j T = o i j T ∣ o i j T ∈ O ∗ j T } K_j^\mathrm{T}=\{ k_{ij}^\mathrm{T}=o_{ij}^\mathrm{T}|o_{ij}^\mathrm{T}\in O_{*j}^\mathrm{T}\} KjT={kijT=oijT∣oijT∈O∗jT}表示子任务 j j j的不同结果的集合。 C T = ⟨ k i 1 1 T , . . . k i j j T , . . . , k i m m T ⟩ \mathrm{C_T}=\langle k_{{i_1}1}^\mathrm{T},...k_{{i_j}j}^\mathrm{T},...,k_{{i_m}m}^\mathrm{T} \rangle CT=⟨ki11T,...kijjT,...,kimmT⟩表示一个候选输出向量,其中 k i j j T ∈ K j T k_{{i_j}j}^\mathrm{T}\in K_j^\mathrm{T} kijjT∈KjT是子任务 j j j的一个结果。
注意, O ∗ j T O_{*j}^\mathrm{T} O∗jT是子任务 j j j的结果向量, K j T K_j^\mathrm{T} KjT是子任务 j j j的不同结果的集合,表2说明了图1(b)中输出矩阵 O T O^\mathrm{T} OT的所有12个 C O V \mathrm{COV} COV,其中 c T l c_\mathrm{T}^l cTl是 C S T T \mathrm{CST\ T} CST T(手写识别)的第 l l l个 C O V \mathrm{COV} COV.接下来,我们将 C S T \mathrm{CST} CST的结果推理问题转化为识别最佳 C O V \mathrm{COV} COV的问题。
表2.一个手写识别任务的COV
| c T 1 c_\mathrm{T}^1 cT1 | You misspelled several work, Plan spellcheck your work next tip. |
| c T 2 c_\mathrm{T}^2 cT2 | You misspelled several work, Plan spellcheck your work next time. |
| c T 3 c_\mathrm{T}^3 cT3 | You misspelled several work, Please spellcheck your work next tip. |
| c T 4 c_\mathrm{T}^4 cT4 | You misspelled several work, Please spellcheck your work next time. |
| c T 5 c_\mathrm{T}^5 cT5 | You misspelled several work, Play spellcheck your work next tip. |
| c T 6 c_\mathrm{T}^6 cT6 | You misspelled several work, Play spellcheck your work next time. |
| c T 7 c_\mathrm{T}^7 cT7 | You misspelled several words, Plan spellcheck your work next tip. |
| c T 8 c_\mathrm{T}^8 cT8 | You misspelled several words, Plan spellcheck your work next time. |
| c T 9 c_\mathrm{T}^9 cT9 | You misspelled several words, Please spellcheck your work next tip. |
| c T 10 c_\mathrm{T}^{10} cT10 | You misspelled several words, Please spellcheck your work next time. |
| c T 11 c_\mathrm{T}^{11} cT11 | You misspelled several words, Play spellcheck your work next tip. |
| c T 12 c_\mathrm{T}^{12} cT12 | You misspelled several words, Play spellcheck your work next time. |
定义3(识别最佳COV,Identifying the Best COV–ICOV)。 设 T \mathrm{T} T为 C S T \mathrm{CST} CST, O T O^\mathrm{T} OT为 T \mathrm{T} T的输出矩阵, C T \mathcal{C}^\mathrm{T} CT为所有可能的 C O V \mathrm{COV} COV的集合,设 p { C T ∣ T , O T } p\{\mathrm{C_T}|\mathrm{T},O^\mathrm{T}\} p{CT∣T,OT}表示 C T \mathrm{C_T} CT为正确输出的概率,则问题是从 C T \mathrm{C_T} CT中找到最佳 C O V \mathrm{COV} COV,如下所示:
C T ′ = arg max C T ∈ C T p { C T ∣ T , O T } . (1) \mathrm{C'_T}={\arg\max}_{\mathrm{C_T}\in \mathcal{C}^\mathrm{T}}p\{\mathrm{C_T}|\mathrm{T},O^\mathrm{T}\}.\tag{1} CT′=argmaxCT∈CTp{CT∣T,OT}.(1)
例如,用图1(b)中的 O T O^\mathrm{T} OT装配最佳结果等于从表2中的 C O V \mathrm{COV} COV集合中选择最佳 C O V \mathrm{COV} COV。我们将讨论如何计算概率 p { C T ∣ T , O T } p\{\mathrm{C_T}|\mathrm{T},O^\mathrm{T}\} p{CT∣T,OT},并在第4节中确定最佳 C O V \mathrm{COV} COV。
为了提高推理质量,广泛采用迭代法来决定何时终止众包过程。
定义4(迭代决策问题,Iterative Decision Problem–IDP)。 设 T \mathrm{T} T为 C S T \mathrm{CST} CST, O T O^\mathrm{T} OT为 T \mathrm{T} T的输出矩阵, c T c_\mathrm{T} cT和 c T ′ c'_\mathrm{T} cT′分别为当前迭代和上一次迭代的推理结果。IDP问题是确定是否终止迭代过程。
定义4定义了一个迭代地获得满意的CST推理结果的决策问题,我们在第5节描述了我们的方法。
讨论。 根据定义2,在最坏的情况下,可以有 n m n^m nm个 C O V \mathrm{COV} COV。理论上, C O V \mathrm{COV} COV集的大小随子任务的数量呈指数增长,定义3中的 I C O V \mathrm{ICOV} ICOV问题是一个NP难问题[52]。然而,正如在[7]中提到的,由于 C S T \mathrm{CST} CST的大小有限,并且工人重复子任务结果, C O V \mathrm{COV} COV的状态空间很小。例如,在表2中,手写识别任务的 C O V \mathrm{COV} COV大小仅为12,远远小于理论值(即310)。
3 上下文感知的众包框架
在本节中,我们概述了我们的CST上下文感知众包框架,如图2所示,其中任务生成、结果推理和迭代决策是三个主要步骤。
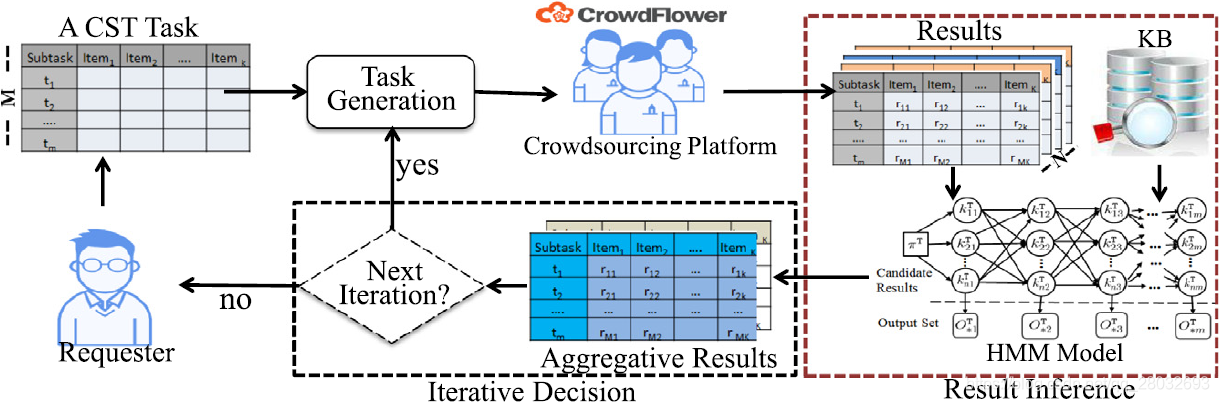
图2. 我们的上下文感知众包概述
任务生成。 我们首先将每个任务分成一系列子任务。例如,我们可以使用OpenCV 1 ^1 1将手写识别任务拆分为单词序列,如图1(a)所示。然后,我们将整个任务众包给人群,并要求工人按顺序回答子任务的顺序,最后,我们收集答案。
结果推理。 此步骤旨在对每个 C S T \mathrm{CST} CST进行结果推理。我们建立了一个概率模型来描述工人的绩效。然后,我们用HMM模型[15]对上下文关联进行建模,并将HMM推理算法引入到EM算法中。为了了解HMM的参数,我们从外部知识库中获取信息。
迭代决策。 我们使用迭代改进方法,在下一轮中,工人将改进当前轮的结果。
我们认为,这种框架一般用于处理各种 C S T \mathrm{CST} CST,也可用于两种典型的众包场景:有和无黄金测试(Golden Tests)。对于没有黄金测试的情况,请求者提交一组任务 T \mathcal{T} T集合;对于有黄金测试,除了 T \mathcal{T} T之外,请求者还提交一组具有已知真值标签 Γ \Gamma Γ的任务,其中 Γ = { ( T ′ , Z T ′ ) ∣ T ′ \Gamma=\{(\mathrm{T'},Z^{\mathrm{T'}})|\mathrm{T'} Γ={(T′,ZT′)∣T′是黄金测试任务, Z T ′ Z^{\mathrm{T'}} ZT′是 T ′ \mathrm{T'} T′的真值标签 } \} }。我们主要使用EM算法和MLE算法来学习未知参数。因为在EM算法中,推理结果与实际情况不绝对完全一致。最大似然估计(MLE)中的真值标签是预先知道的。因此,EM算法得到的参数精度低于MLE算法得到的参数精度。因此,在我们的工作中, Γ \Gamma Γ和 T \mathcal{T} T是混合在一起的,工人不知道哪些是黄金测试任务。 Γ \Gamma Γ用MLE估计工人的准确度,然后用EM算法推理出 T ∈ T \mathrm{T}\in\mathcal{T} T∈T的最佳 C O V \mathrm{COV} COV和任务难度。每项任务 T ∈ T \mathrm{T}\in\mathcal{T} T∈T和 T ′ ∈ Γ \mathrm{T'}\in\Gamma T′∈Γ将分配给 N N N个工人。一旦工人完成了他们的任务,根据对测试任务的评估,将淘汰质量较低的输出。不同之处在于对 Γ \Gamma Γ,我们可以使用MLE来推理参数。
4 CST的上下文感知推理
本节主要介绍两种解决 I C O V \mathrm{ICOV} ICOV问题的方法。
4.1 模拟子任务的众包过程
本小节模拟了子任务的众包过程。基于上述讨论,受Whitehill等人[46]的启发,我们给出了图3所示的图形模型。
工人 i i i在 T \mathrm{T} T中提交子任务 j j j的输出 o i j T o_{ij}^\mathrm{T} oijT主要取决于三个因素:
- 子任务的难度 d j T ∈ [ 0 , 1 ] d_j^\mathrm{T}\in[0,1] djT∈[0,1]。一般来说, d j T d_j^\mathrm{T} djT越高任务越难。
- 工人 i i i提交的结果的准确度: w i T ∈ [ 1 , + ∞ ] ( 1 / w i T ∈ [ 0 , 1 ] ) w_i^\mathrm{T}\in[1,+\infty](1/w_i^\mathrm{T}\in[0,1]) wiT∈[1,+∞](1/wiT∈[0,1]),表示准确度的倒数,较小的 w i T w_i^\mathrm{T} wiT是指工人 i i i提交的结果更准确;(请注意,为了简明地模拟我们的模型,我们使用准确度的倒数,见公式(2))。
- 子任务 j j j的真值标签 z j T z_j^\mathrm{T} zjT。然后,我们可以给出一个概率模型来模拟回答过程。
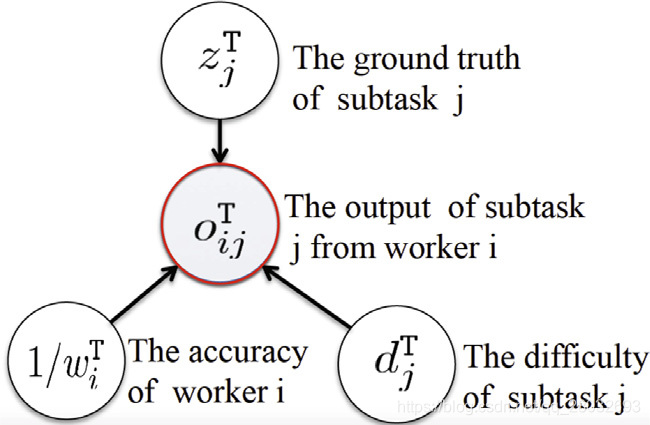
图3.
C
S
T
T
\mathrm{CST\ T}
CST T的子任务
j
j
j的概率图模型
首先,我们建立工人回答正确的概率模型。我们的直觉是,生成正确答案的概率取决于三个因素:任务难度、工人的准确度以及在候选答案集中正确答案的分布。假设 k i ′ j T ∈ K j T k_{i'j}^\mathrm{T}\in K_j^\mathrm{T} ki′jT∈KjT是子任务 j j j的正确答案。如果工人 i i i给出了子任务 j j j的正确答案,即 o i j T = k i ′ j T o_{ij}^\mathrm{T}=k_{i'j}^\mathrm{T} oijT=ki′jT,那么工人i的输出 o i j T o_{ij}^\mathrm{T} oijT是子任务 j j j的正确答案的概率定义如下:
P ( o i j T = k i ′ j T ∣ z j T = k i ′ j T , w i T , d j T ) = ( a i j T ) d j T w i T . (2) P(o_{ij}^\mathrm{T}=k_{i'j}^\mathrm{T}|z_j^\mathrm{T}=k_{i'j}^\mathrm{T},w_i^\mathrm{T},d_j^\mathrm{T})=(a_{ij}^\mathrm{T})^{d_j^\mathrm{T}w_i^\mathrm{T}}.\tag{2} P(oijT=ki′jT∣zjT=ki′jT,wiT,djT)=(aijT)djTwiT.(2)
其中, a i j T = s i m ( k i ′ j T , k i ′ j T ) ∑ i ′ ′ = 1 ∣ K j T ∣ s i m ( k i ′ ′ j T , k i ′ j T ) a_{ij}^\mathrm{T}=\frac{sim(k_{i'j}^\mathrm{T},k_{i'j}^\mathrm{T})}{\sum_{i''=1}^{|K_j^\mathrm{T}|}sim(k_{i''j}^\mathrm{T},k_{i'j}^\mathrm{T})} aijT=∑i′′=1∣KjT∣sim(ki′′jT,ki′jT)sim(ki′jT,ki′jT)表示 K j T K_j^\mathrm{T} KjT中 k i ′ j T k_{i'j}^\mathrm{T} ki′jT的辨别度,用 k i ′ j T k_{i'j}^\mathrm{T} ki′jT与候选结果集 K j T K_j^\mathrm{T} KjT之间的归一化相似度计算, s i m ( k i ′ ′ j T , k i ′ j T ) sim(k_{i''j}^\mathrm{T},k_{i'j}^\mathrm{T}) sim(ki′′jT,ki′jT)表示候选结果 k i ′ ′ j T k_{i''j}^\mathrm{T} ki′′jT和 k i ′ j T k_{i'j}^\mathrm{T} ki′jT之间的原始相似度。例如,在手写识别中, s i m ( k i ′ ′ j T , k i ′ j T ) sim(k_{i''j}^\mathrm{T},k_{i'j}^\mathrm{T}) sim(ki′′jT,ki′jT)表示两个单词(两个字符序列)的相似度对应它们对应外形的相似度。如果 k i j T k_{ij}^\mathrm{T} kijT与未知的真值标签 z j T z_j^\mathrm{T} zjT非常相似,那么很可能由工人给出 k i j T k_{ij}^\mathrm{T} kijT作为候选答案,这也意味着 s i m ( k i ′ ′ j T , k i ′ j T ) sim(k_{i''j}^\mathrm{T},k_{i'j}^\mathrm{T}) sim(ki′′jT,ki′jT)应接近1(特别是 s i m ( k i j T , k i j T ) = 1 sim(k_{ij}^\mathrm{T},k_{ij}^\mathrm{T})=1 sim(kijT,kijT)=1)。
其次,如果工人 i i i给出的答案与正确答案 k i ′ j T k_{i'j}^\mathrm{T} ki′jT不同,即 o i j T = k i ′ ′ j T ≠ k i ′ j T o_{ij}^\mathrm{T}=k_{i''j}^\mathrm{T}\neq k_{i'j}^\mathrm{T} oijT=ki′′jT=ki′jT,那么候选回答 k i ′ ′ j T ∈ K j T k_{i''j}^\mathrm{T}\in K_j^\mathrm{T} ki′′jT∈KjT被工人 i i i错误地确定为是正确答案的概率是:
P ( o i j T = k i ′ ′ j T ∣ z j T = k i ′ j T , w i T , d j T ) = ( 1 − ( a i j T ) d j T w i T ) θ ( k i ′ ′ j T , k i ′ j T ) . (3) P(o_{ij}^\mathrm{T}=k_{i''j}^\mathrm{T}|z_j^\mathrm{T}=k_{i'j}^\mathrm{T},w_i^\mathrm{T},d_j^\mathrm{T})=(1-(a_{ij}^\mathrm{T})^{d_j^\mathrm{T}w_i^\mathrm{T}})\theta(k_{i''j}^\mathrm{T},k_{i'j}^\mathrm{T}).\tag{3} P(oijT=ki′′jT∣zjT=ki′jT,wiT,djT)=(1−(aijT)djTwiT)θ(ki′′jT,ki′jT).(3)
其中, θ ( k i ′ ′ j T , k i ′ j T ) = s i m ( k i ′ ′ j T , k i ′ j T ) ∑ i = 1 ∣ K j T ∣ s i m ( k i ′ j T , k i j T ) − 1 \theta(k_{i''j}^\mathrm{T},k_{i'j}^\mathrm{T})=\frac{sim(k_{i''j}^\mathrm{T},k_{i'j}^\mathrm{T})}{\sum_{i=1}^{|K_j^\mathrm{T}|}sim(k_{i'j}^\mathrm{T},k_{ij}^\mathrm{T})-1} θ(ki′′jT,ki′jT)=∑i=1∣KjT∣sim(ki′jT,kijT)−1sim(ki′′jT,ki′jT)表示两个错误结果 k i ′ ′ j T k_{i''j}^\mathrm{T} ki′′jT和 k i ′ j T k_{i'j}^\mathrm{T} ki′jT与所有错误结果的归一化距离比。这有助于更好地捕捉工人的表现,这与现有的模型(如GLAD模型[46]和Dawid-Skene模型[9])有着明显的区别。
为了化简的公式(2)和(3),我们定义 σ ( o i j T ) = ( a i j T ) d j T w i T \sigma(o_{ij}^\mathrm{T})=(a_{ij}^\mathrm{T})^{d_j^\mathrm{T}w_i^\mathrm{T}} σ(oijT)=(aijT)djTwiT和 δ ( o i j T , z j T ) \delta(o_{ij}^\mathrm{T},z_j^\mathrm{T}) δ(oijT,zjT)表示克罗内克函数(Kronecker Delta Function)[37],进一步简化为 δ \delta δ。然后我们有了
P ( o i j T ∣ z j T , w i T , d j T ) = σ ( o i j T ) δ ( ( 1 − σ ( o i j T ) ) θ ( o i j T ) ) 1 − δ . (4) P(o_{ij}^\mathrm{T}|z_j^\mathrm{T},w_i^\mathrm{T},d_j^\mathrm{T})=\sigma(o_{ij}^\mathrm{T})^\delta((1-\sigma(o_{ij}^\mathrm{T}))\theta(o_{ij}^\mathrm{T}))^{1-\delta}.\tag{4} P(oijT∣zjT,wiT,djT)=σ(oijT)δ((1−σ(oijT))θ(oijT))1−δ.(4)
在众包中,从已知的先验分布中抽取真值标签 z j T z_j^\mathrm{T} zjT、工人精度参数 w i T w_i^\mathrm{T} wiT和子任务难度 d j T d_j^\mathrm{T} djT。如果给定了 O ∗ j T O_{*j}^\mathrm{T} O∗jT,则可由 O ∗ j T O_{*j}^\mathrm{T} O∗jT求出 K j T K_j^\mathrm{T} KjT,我们可用公式(4)通过一些推理方法推理出 z j T z_j^\mathrm{T} zjT在 K j T K_j^\mathrm{T} KjT中的最可能值。
4.2 贝叶斯推理(Bayes-Inf):不捕获上下文关联
本小节给出了不考虑上下文关联的结果推理的 B a y e s − I n f \mathrm{Bayes-Inf} Bayes−Inf。在定义4的基础上,将替代答案之间的相似度引入到结果推理中,并给出 B a y e s − I n f \mathrm{Bayes-Inf} Bayes−Inf来推理真值标签。最后,我们使用MLE算法和EM算法来估计 B a y e s − I n f \mathrm{Bayes-Inf} Bayes−Inf的参数,并按照[46]中使用的方法来描述EM算法的过程。
4.2.1 Bayes-Inf概述
我们从 C S T \mathrm{CST} CST中的子任务 j j j的推理模型开始,然后将所有子任务的结果作为 C S T \mathrm{CST} CST的最终结果合并到 C O V \mathrm{COV} COV中。
对于 C S T \mathrm{CST} CST的每个子任务 j j j(无真值标签),给出观测数据 O ∗ j T O_{*j}^\mathrm{T} O∗jT,并生成候选结果集 K j T K_j^\mathrm{T} KjT。完成子任务 j j j的所有工人的准确度参数表示为 W j T = { w i T ∣ w i T W_j^\mathrm{T}=\{w_i^\mathrm{T}|w_i^\mathrm{T} WjT={wiT∣wiT表示回答子任务 j j j的工人 i i i的准确度 } \} },回答 C S T \mathrm{CST} CST的所有工人的准确度参数表示为 W T = { W j T ∣ 0 ≤ j ≤ m } W^\mathrm{T}=\{ W_j^\mathrm{T}|0\leq j\leq m\} WT={WjT∣0≤j≤m}。然后,子任务 j j j的最佳结果如下:
k i j j T = arg max k i ′ j T ∈ K j T P ( z j T = k i ′ j T ∣ O ∗ j T , W j T , d j T ) , (5) k_{{i_j}j}^\mathrm{T}={\arg\max}_{k_{i'j}^\mathrm{T}\in K_j^\mathrm{T}}P(z_j^\mathrm{T}=k_{i'j}^\mathrm{T}|O_{*j}^\mathrm{T},W_j^\mathrm{T},d_j^\mathrm{T}),\tag{5} kijjT=argmaxki′jT∈KjTP(zjT=ki′jT∣O∗jT,WjT,djT),(5)
其中
P ( z j T = k i ′ j T ∣ O ∗ j T , W j T , d j T ) = P ( z j T = k i ′ j T ∣ W j T , d j T ) P ( O ∗ j T ∣ z j T = k i ′ j T , W j T , d j T ) P ( O ∗ j T ∣ W j T , d j T ) ∝ P ( z j T = k i ′ j T ∣ W j T , d j T ) P ( O ∗ j T ∣ z j T = k i ′ j T , W j T , d j T ) ∝ P ( z j T = k i ′ j T ) ∏ i = 1 , o i j T ≠ ϕ n P ( o i j T ∣ z j T = k i ′ j T , w i T , d j T ) . (6) \begin{aligned} P(z_j^\mathrm{T}=k_{i'j}^\mathrm{T}|O_{*j}^\mathrm{T},W_j^\mathrm{T},d_j^\mathrm{T}) &=\frac{P(z_j^\mathrm{T}=k_{i'j}^\mathrm{T}|W_j^\mathrm{T},d_j^\mathrm{T})P(O_{*j}^\mathrm{T}|z_j^\mathrm{T}=k_{i'j}^\mathrm{T},W_j^\mathrm{T},d_j^\mathrm{T})}{P(O_{*j}^\mathrm{T}|W_j^\mathrm{T},d_j^\mathrm{T})}\\ &\propto P(z_j^\mathrm{T}=k_{i'j}^\mathrm{T}|W_j^\mathrm{T},d_j^\mathrm{T})P(O_{*j}^\mathrm{T}|z_j^\mathrm{T}=k_{i'j}^\mathrm{T},W_j^\mathrm{T},d_j^\mathrm{T})\\ &\propto P(z_j^\mathrm{T}=k_{i'j}^\mathrm{T})\prod_{i=1,o_{ij}^\mathrm{T}\neq\phi}^{n}P(o_{ij}^\mathrm{T}|z_j^\mathrm{T}=k_{i'j}^\mathrm{T},w_i^\mathrm{T},d_j^\mathrm{T}). \end{aligned}\tag{6} P(zjT=ki′jT∣O∗jT,WjT,djT)=P(O∗jT∣WjT,djT)P(zjT=ki′jT∣WjT,djT)P(O∗jT∣zjT=ki′jT,WjT,djT)∝P(zjT=ki′jT∣WjT,djT)P(O∗jT∣zjT=ki′jT,WjT,djT)∝P(zjT=ki′jT)i=1,oijT=ϕ∏nP(oijT∣zjT=ki′jT,wiT,djT).(6)
注意 p ( z j T ) = p ( z j T = k i ′ j T ∣ W j T , d j T ) p(z_j^\mathrm{T})=p(z_j^\mathrm{T}=k_{i'j}^\mathrm{T}|W_j^\mathrm{T},d_j^\mathrm{T}) p(zjT)=p(zjT=ki′jT∣WjT,djT)是根据我们的图形模型中的条件独立性假设得出的。由于从候选答案中选择正确答案的概率是相同的,所以我们得到 p ( z j T ) = 1 / ∣ K j T ∣ p(z_j^\mathrm{T})=1/|K_j^\mathrm{T}| p(zjT)=1/∣KjT∣。
利用公式(5),我们得到每个子任务j的 k i j j T k_{{i_j}j}^\mathrm{T} kijjT。不考虑输出矩阵中的上下文关联,我们可以生成一个 C O V C T ′ = ⟨ k i 1 1 T , . . . k i j j T , . . . , k i m m T ⟩ \mathrm{COV\ C'_T}=\langle k_{{i_1}1}^\mathrm{T},...k_{{i_j}j}^\mathrm{T},...,k_{{i_m}m}^\mathrm{T} \rangle COV CT′=⟨ki11T,...kijjT,...,kimmT⟩,这是定义3中 C S T \mathrm{CST} CST的最佳 C O V \mathrm{COV} COV。
4.2.2 参数学习
B a y e s − I n f \mathrm{Bayes-Inf} Bayes−Inf模型的过程包含两个参数集,即工作能力集 W W W和任务难度集 D D D。每个工人的能力不因任务的不同而不同。因此,我们根据黄金任务的结果使用MLE方法来评估每个工人的能力。因为任务的难度不同。使用基于黄金任务的方法无法获得任务(黄金任务除外)的难度级别。因此,我们使用EM算法来估计没有真值标签的 C S T \mathrm{CST} CST的难度,并推理出最终结果,类似于[46]。
(1). 黄金测试任务参数学习
对于一组测试任务 Γ = { ( T ′ , Z T ′ ) } \Gamma=\{(\mathrm{T'},Z^{\mathrm{T'}})\} Γ={(T′,ZT′)}, O T ′ O^\mathrm{T'} OT′是测试任务 T ′ \mathrm{T'} T′的输出矩阵, W T ′ W^\mathrm{T'} WT′表示完成 T ′ \mathrm{T'} T′的工人对应的准确度参数, Z T ′ Z^\mathrm{T'} ZT′是真值标签。未观察到的变量是不同的工人准确度 W T ′ = { w i T ′ } W^\mathrm{T'}=\{w_i^\mathrm{T'}\} WT′={wiT′}和子任务难度参数 D T ′ = { d j T ′ } D^\mathrm{T'}=\{d_j^\mathrm{T'}\} DT′={djT′}。对于每个测试任务 T ′ \mathrm{T'} T′,我们将似然函数 l T ′ l_\mathrm{T'} lT′介绍如下:
l T ′ ( W T ′ , D T ′ ) = ∏ i j P ( o i j T ′ ∣ z j T ′ , w i T ′ , d j T ′ ) . (7) l_\mathrm{T'}(W^\mathrm{T'},D^\mathrm{T'})=\prod_{ij}P(o_{ij}^\mathrm{T'}|z_j^\mathrm{T'},w_i^\mathrm{T'},d_j^\mathrm{T'}).\tag{7} lT′(WT′,DT′)=ij∏P(oijT′∣zjT′,wiT′,djT′).(7)
在实践中,我们经常使用多个测试任务作为黄金测试。根据公式(7),我们得到对数似然函数
L Γ ( W T ′ , D T ′ ) = ln ∏ T ′ ∈ Γ l T ′ ( W T ′ , D T ′ ) . (8) L_\Gamma(W^\mathrm{T'},D^\mathrm{T'})=\ln\prod_{\mathrm{T'}\in\Gamma}l_\mathrm{T'}(W^\mathrm{T'},D^\mathrm{T'}).\tag{8} LΓ(WT′,DT′)=lnT′∈Γ∏lT′(WT′,DT′).(8)
为了使 L Γ ( W T ′ , D T ′ ) L_\Gamma(W^\mathrm{T'},D^\mathrm{T'}) LΓ(WT′,DT′)最大化,我们可以对函数 L Γ L_\Gamma LΓ进行区分,得到梯度:
∂ L Γ ∂ w i T ′ = ∑ T ′ ∈ Γ ∑ j δ ( o i j T ′ , z j T ′ ) − σ ( o i j T ′ ) 1 − σ ( o i j T ′ ) d j T ′ ln a i j T ′ . (9) \frac{\partial L_\Gamma}{\partial w_i^\mathrm{T'}}=\sum_{\mathrm{T'}\in\Gamma}\sum_j\frac{\delta(o_{ij}^\mathrm{T'},z_j^\mathrm{T'})-\sigma(o_{ij}^\mathrm{T'})}{1-\sigma(o_{ij}^\mathrm{T'})}d_j^\mathrm{T'}\ln a_{ij}^\mathrm{T'}.\tag{9} ∂wiT′∂LΓ=T′∈Γ∑j∑1−σ(oijT′)δ(oijT′,zjT′)−σ(oijT′)djT′lnaijT′.(9)
和
∂ L Γ ∂ d j T ′ = ∑ i δ ( o i j T ′ , z j T ′ ) − σ ( o i j T ′ ) 1 − σ ( o i j T ′ ) w i T ′ ln a i j T ′ . (10) \frac{\partial L_\Gamma}{\partial d_j^\mathrm{T'}}=\sum_i\frac{\delta(o_{ij}^\mathrm{T'},z_j^\mathrm{T'})-\sigma(o_{ij}^\mathrm{T'})}{1-\sigma(o_{ij}^\mathrm{T'})}w_i^\mathrm{T'}\ln a_{ij}^\mathrm{T'}.\tag{10} ∂djT′∂LΓ=i∑1−σ(oijT′)δ(oijT′,zjT′)−σ(oijT′)wiT′lnaijT′.(10)
其中符号 σ \sigma σ、 δ \delta δ和 a i j T ′ a_{ij}^\mathrm{T'} aijT′在第4.1节中进行了讨论。用公式(9)和(10),我们可以使用梯度上升法[46]获得 W T ′ W^\mathrm{T'} WT′和 D T ′ D^\mathrm{T'} DT′。
(2). 用EM算法进行推理
本部分介绍了学习子任务难度参数的EM算法。与黄金测试的情况不同,很难获得工人的真实准确度,即 W T W^\mathrm{T} WT未知。对于 C S T T ∈ T \mathrm{CST\ T}\in\mathcal{T} CST T∈T,让 O T O^\mathrm{T} OT表示 T \mathrm{T} T的输出矩阵, W T W^\mathrm{T} WT表示准确度参数集, D T = { d j ∣ 0 ≤ j ≤ m } D^\mathrm{T}=\{d_j|0\leq j\leq m\} DT={dj∣0≤j≤m}为 C S T \mathrm{CST} CST的难度。由于在加工不同的 C S T \mathrm{CST} CST时,工人的准确度参数可以被视为常数,因此我们可以用 W T ′ W^\mathrm{T'} WT′来估计 W T W^\mathrm{T} WT,即 W T = W T ′ W^\mathrm{T}=W^\mathrm{T'} WT=WT′。由于 C S T \mathrm{CST} CST的不同子任务具有不同的难度参数,因此 T \mathrm{T} T的 D T D^\mathrm{T} DT仍然未知,我们研究如何学习这些参数。
观测数据 O ∗ j T O_{*j}^\mathrm{T} O∗jT是输出矩阵 O T O^\mathrm{T} OT的每个子任务样本。未观察到的变量是真值标签 z j T z_j^\mathrm{T} zjT和子任务的难度参数 d j T d_j^\mathrm{T} djT。 B a y e s − I n f \mathrm{Bayes-Inf} Bayes−Inf的目的是利用观测数据 O ∗ j T O_{*j}^\mathrm{T} O∗jT和 w i T ∈ W w_i^\mathrm{T}\in W wiT∈W有效地搜索不可观测变量 Z T = { z j T } Z^\mathrm{T}=\{z_j^\mathrm{T}\} ZT={zjT}和 d j T d_j^\mathrm{T} djT的最可能值。在这里,我们使用期望最大化算法(EM)来获得参数的最大似然估计。
E-步骤: 让 K j T K_j^\mathrm{T} KjT表示具有 m m m个子任务的 C S T T \mathrm{CST\ T} CST T子任务 j j j的候选结果集, z j T z_j^\mathrm{T} zjT被视为潜在变量。参加 C S T \mathrm{CST} CST的工人不能总是完成 C S T \mathrm{CST} CST的所有子任务,那么 ∣ O ∗ j T ∣ ≤ n |O_{*j}^\mathrm{T}|\leq n ∣O∗jT∣≤n。利用最后一个M-步骤计算的 d j T d_j^\mathrm{T} djT,观察到的输出 O ∗ j T O_{*j}^\mathrm{T} O∗jT和 W T = W T ′ W^\mathrm{T}=W^\mathrm{T'} WT=WT′,候选结果 k i ′ j T k_{i'j}^\mathrm{T} ki′jT是子任务 j j j正确答案的后验概率可计算如下:
P k i ′ j T = P ( z j T = k i ′ j T ∣ O ∗ j T , W j T , d j T ) , (11) P^{k_{i'j}^\mathrm{T}}=P(z_j^\mathrm{T}=k_{i'j}^\mathrm{T}|O_{*j}^\mathrm{T},W_j^\mathrm{T},d_j^\mathrm{T}),\tag{11} Pki′jT=P(zjT=ki′jT∣O∗jT,WjT,djT),(11)
其中 P ( z j T = k i ′ j T ∣ O ∗ j T , W j T , d j T ) P(z_j^\mathrm{T}=k_{i'j}^\mathrm{T}|O_{*j}^\mathrm{T},W_j^\mathrm{T},d_j^\mathrm{T}) P(zjT=ki′jT∣O∗jT,WjT,djT)可以由公式(6)获得。
M-步骤: 最大化辅助函数 Q Q Q,即观测数据和未观测数据 Z T = { z j T } Z^\mathrm{T}=\{z_j^\mathrm{T}\} ZT={zjT}的联合对数似然期望值,可从 D o l d T D_{old}^\mathrm{T} DoldT参数中获得。根据E-步骤计算的 Z T Z^\mathrm{T} ZT的后验概率,我们定义了辅助函数 Q Q Q:
Q ( D T , D o l d T ) = E ( ln ( P ( O T , Z T ∣ W T ′ , D o l d T ) ) ) = E ( ln ( ∏ j ( P ( z j T ) ∏ i P ( o i j T ∣ z j T , w i T , d j T ) ) ) = ∑ j ∑ i ′ = 1 ∣ K j T ∣ P k i ′ j T ln P ( z j T = k i ′ j T ) + ∑ i , j ∑ i ′ = 1 ∣ K j T ∣ P k i ′ j T ln P ( o i j T ∣ z j T = k i ′ j T , w i T , d j T ) , (12) \begin{aligned} Q(D^\mathrm{T},D_{old}^\mathrm{T}) &=E(\ln(P(O^\mathrm{T},Z^\mathrm{T}|W^\mathrm{T'},D_{old}^\mathrm{T})))\\ &=E(\ln(\prod_j(P(z_j^\mathrm{T})\prod_i P(o_{ij}^\mathrm{T}|z_j^\mathrm{T},w_i^\mathrm{T},d_j^\mathrm{T})))\\ &=\sum_j\sum_{i'=1}^{|K_j^\mathrm{T}|}P^{k_{i'j}^\mathrm{T}}\ln P(z_j^\mathrm{T}=k_{i'j}^\mathrm{T})+\sum_{i,j}\sum_{i'=1}^{|K_j^\mathrm{T}|}P^{k_{i'j}^\mathrm{T}}\ln P(o_{ij}^\mathrm{T}|z_j^\mathrm{T}=k_{i'j}^\mathrm{T},w_i^\mathrm{T},d_j^\mathrm{T}), \end{aligned}\tag{12} Q(DT,DoldT)=E(ln(P(OT,ZT∣WT′,DoldT)))=E(ln(j∏(P(zjT)i∏P(oijT∣zjT,wiT,djT)))=j∑i′=1∑∣KjT∣Pki′jTlnP(zjT=ki′jT)+i,j∑i′=1∑∣KjT∣Pki′jTlnP(oijT∣zjT=ki′jT,wiT,djT),(12)
其中 p k i ′ j T p^{k_{i'j}^\mathrm{T}} pki′jT和 k i ′ j T k_{i'j}^\mathrm{T} ki′jT可以用E-步骤中已经估计的 D o l d T D_{old}^\mathrm{T} DoldT得到。
为了最大化 Q ( D T , D o l d T ) Q(D^\mathrm{T},D_{old}^\mathrm{T}) Q(DT,DoldT),我们可以区分 Q Q Q来获得梯度:
∂ Q ∂ d j T = ∑ i ∑ i ′ = 1 ∣ K j T ∣ P k i ′ j T δ ( o i j T , k i ′ j T ) − σ ( o i j T ) 1 − σ ( o i j T ) w i T ln a i j T , (13) \frac{\partial Q}{\partial d_j^\mathrm{T}}=\sum_i\sum_{i'=1}^{|K_j^\mathrm{T}|}P^{k_{i'j}^\mathrm{T}}\frac{\delta(o_{ij}^\mathrm{T},k_{i'j}^\mathrm{T})-\sigma(o_{ij}^\mathrm{T})}{1-\sigma(o_{ij}^\mathrm{T})}w_i^\mathrm{T}\ln a_{ij}^\mathrm{T},\tag{13} ∂djT∂Q=i∑i′=1∑∣KjT∣Pki′jT1−σ(oijT)δ(oijT,ki′jT)−σ(oijT)wiTlnaijT,(13)
其中,符号 σ \sigma σ、 δ \delta δ和 a i j T a_{ij}^\mathrm{T} aijT在第4.1节中进行了讨论。与[46]相似,我们使用 D o l d T D_{old}^\mathrm{T} DoldT通过梯度上升更新新的 D T D^\mathrm{T} DT,在当前步骤中局部最大化 Q Q Q。然后,我们迭代地应用E-步骤和M-步骤来获得 D T D^\mathrm{T} DT,并使似然最大化。
4.3 Context-Inf(上下文推理):捕获上下文关联
本小节介绍一个上下文感知推理模型 C o n t e x t − I n f \mathrm{Context-Inf} Context−Inf,它用HMM模型对子任务之间的上下文关联进行建模。接下来,我们给出我们的推理模型来估计参数,其过程也类似于[46]。
4.3.1 CST中的上下文关联
在本小节中,我们给出了两个子任务的候选结果之间上下文关联的定义。例如,对于手写识别,上下文关联可以通过2-gram语言模型获得。我们构造了一个上下文图,其中节点是子任务的候选结果,边是每对的上下文关联。图4显示了一个 C O V \mathrm{COV} COV的示例,所有 C O V \mathrm{COV} COV都显示在表2中。然后,引入 f ( k i ′ j ′ T ∣ k i j T ) f(k_{i'j'}^\mathrm{T}|k_{ij}^\mathrm{T}) f(ki′j′T∣kijT)来量化 k i j T k_{ij}^\mathrm{T} kijT和 k i ′ j ′ T k_{i'j'}^\mathrm{T} ki′j′T之间的上下文关联:
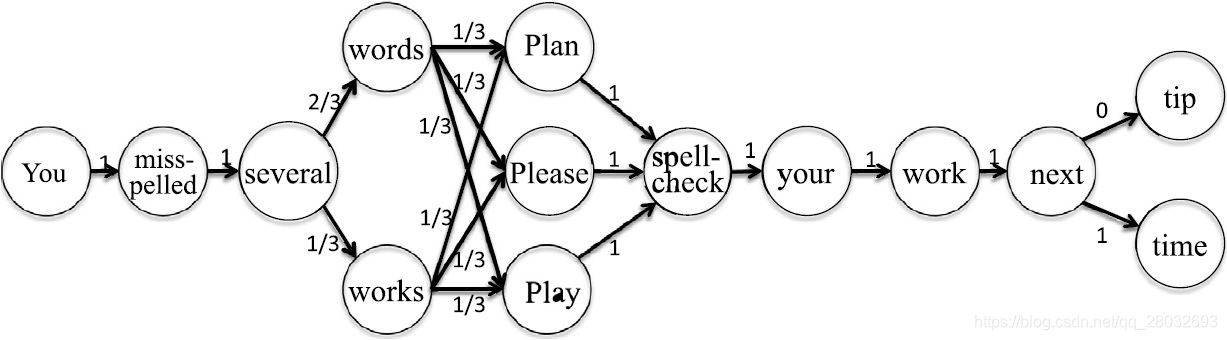
图4. 上下文关联的示例
f ( k i ′ j ′ T ∣ k i j T ) = w e i g h t ( k i j T , k i ′ j ′ T ) ∑ l = 1 n w e i g h t ( k i j T , k l j ′ T ) , (14) f(k_{i'j'}^\mathrm{T}|k_{ij}^\mathrm{T})=\frac{weight(k_{ij}^\mathrm{T},k_{i'j'}^\mathrm{T})}{\sum_{l=1}^n weight(k_{ij}^\mathrm{T},k_{lj'}^\mathrm{T})},\tag{14} f(ki′j′T∣kijT)=∑l=1nweight(kijT,klj′T)weight(kijT,ki′j′T),(14)
其中 j ≠ j ′ j\neq j' j=j′,权重 w e i g h t ( k i j T , k i ′ j ′ T ) weight(k_{ij}^\mathrm{T},k_{i'j'}^\mathrm{T}) weight(kijT,ki′j′T)表示子任务 j j j的候选结果 k i j T k_{ij}^\mathrm{T} kijT与另一个子任务 j ′ j' j′的 k i ′ j ′ T k_{i'j'}^\mathrm{T} ki′j′T之间的上下文关联度,可从外部知识库中获得。例如,我们可以量化手写识别每对子任务的两个候选结果之间的上下文关联,如下所示:
f ( k i ′ j ′ T ∣ k i j T ) = { N ( k i j T , k i ′ j ′ T ) ∑ l = 0 n N ( k i j T , k l j ′ T ) j ′ = j + 1 0 j ′ ≠ j + 1 . (15) f(k_{i'j'}^\mathrm{T}|k_{ij}^\mathrm{T})= \left\{\begin{matrix} \frac{N(k_{ij}^\mathrm{T},k_{i'j'}^\mathrm{T})}{\sum_{l=0}^n N(k_{ij}^\mathrm{T},k_{lj'}^\mathrm{T})}&j'=j+1\\ 0&j'\neq j+1 \end{matrix}\right..\tag{15} f(ki′j′T∣kijT)={∑l=0nN(kijT,klj′T)N(kijT,ki′j′T)0j′=j+1j′=j+1.(15)
其中 N ( k i j T , k l j ′ T ) N(k_{ij}^\mathrm{T},k_{lj'}^\mathrm{T}) N(kijT,klj′T)表示两个词在文本语料库中共现的频率,如英国国家语料库、谷歌n-gram语料库。
为了便于在结果推理中使用,我们将输出矩阵的上下文图的邻接矩阵指定为 C T C^\mathrm{T} CT,一个表示 C S T \mathrm{CST} CST中所有上下文关联的上下文矩阵。
4.3.2 上下文感知推理模型
我们描述上下文信息来推理 C S T \mathrm{CST} CST最可能的 C O V \mathrm{COV} COV(没有真值标签),考虑上下文关联。
给定候选结果集 { K j T ∣ 0 ≤ j ≤ m } \{ K_j^\mathrm{T}|0\leq j\leq m\} {KjT∣0≤j≤m}从工人的输出矩阵 O T O^\mathrm{T} OT中获得。 C S T \mathrm{CST} CST的上下文矩阵 C T = { f ( k i j T ∣ k i ′ j ′ T ) } C^\mathrm{T}=\{f(k_{ij}^\mathrm{T}|k_{i'j'}^\mathrm{T})\} CT={f(kijT∣ki′j′T)}可由公式(14)计算。子任务的推理结果取决于三个因素:难度、工人的准确度和每对答案之间的上下文相关性。我们使用图5所示的隐马尔可夫模型[15] λ = ( A , B , π ) \lambda=(\mathcal{A},\mathcal{B},\pi) λ=(A,B,π)来捕获 T \mathrm{T} T子任务之间的上下文相关性,并将每个 k i j T k_{ij}^\mathrm{T} kijT作为HMM的隐态; π T = { π i T = E ( z 1 T = k i 1 T ) } \pi^\mathrm{T}=\{ \pi_i^\mathrm{T}= E(z_1^\mathrm{T}=k_{i1}^\mathrm{T})\} πT={πiT=E(z1T=ki1T)}是 k i 1 T k_{i1}^\mathrm{T} ki1T作为 C S T T \mathrm{CST\ T} CST T中第一个子任务的答案的先验概率; A T = C T \mathcal{A}^\mathrm{T}=C^\mathrm{T} AT=CT是HMM的状态转换概率矩阵; B T = { b k i j T ( O ∗ j T ) } \mathcal{B}^\mathrm{T}=\{ b_{k_{ij}^\mathrm{T}}(O_{*j}^\mathrm{T})\} BT={bkijT(O∗jT)}是HMM的输出概率矩阵, b k i j T ( O ∗ j T ) b_{k_{ij}^\mathrm{T}}(O_{*j}^\mathrm{T}) bkijT(O∗jT)描述观测 O ∗ j T O_{*j}^\mathrm{T} O∗jT与隐态 k i j T k_{ij}^\mathrm{T} kijT之间的关系,定义如下:
b k i j T ( O ∗ j T ) = P ( O ∗ j T ∣ z j T = k i j T , W j T , d j T ) = P ( W j T , O ∗ j T ∣ z j T = k i j T , d j T ) P ( W j T ∣ z j T = k i j T , d j T ) = P ( W j T ∣ O ∗ j T , z j T = k i j T , d j T ) P ( O ∗ j T ∣ z j T = k i j T , d j T ) P ( W j T ∣ z j T = k i j T , d j T ) = ∏ w i ′ ∈ W j T P ( w i ′ T ∣ O ∗ j T , z j T = k i j T , d j T ) ∏ w i ′ ∈ W j T P ( o i j T ∣ z j T = k i j T , d j T ) ∏ w i ′ ∈ W j T P ( w i ′ T ∣ z j T = k i j T , d j T ) = ∏ w i ′ ∈ W j T P ( o i ′ j T ∣ z j T = k i j T , w i ′ T , d j T ) . (16) \begin{aligned} b_{k_{ij}^\mathrm{T}}(O_{*j}^\mathrm{T}) &=P(O_{*j}^\mathrm{T}|z_j^\mathrm{T}=k_{ij}^\mathrm{T},W_j^\mathrm{T},d_j^\mathrm{T})\\ &=\frac{P(W_j^\mathrm{T},O_{*j}^\mathrm{T}|z_j^\mathrm{T}=k_{ij}^\mathrm{T},d_j^\mathrm{T})}{P(W_j^\mathrm{T}|z_j^\mathrm{T}=k_{ij}^\mathrm{T},d_j^\mathrm{T})}\\ &=\frac{P(W_j^\mathrm{T}|O_{*j}^\mathrm{T},z_j^\mathrm{T}=k_{ij}^\mathrm{T},d_j^\mathrm{T})P(O_{*j}^\mathrm{T}|z_j^\mathrm{T}=k_{ij}^\mathrm{T},d_j^\mathrm{T})}{P(W_j^\mathrm{T}|z_j^\mathrm{T}=k_{ij}^\mathrm{T},d_j^\mathrm{T})}\\ &=\frac{\prod_{w_{i'}\in W_j^\mathrm{T}}P(w_{i'}^\mathrm{T}|O_{*j}^\mathrm{T},z_j^\mathrm{T}=k_{ij}^\mathrm{T},d_j^\mathrm{T})\prod_{w_{i'}\in W_j^\mathrm{T}}P(o_{ij}^\mathrm{T}|z_j^\mathrm{T}=k_{ij}^\mathrm{T},d_j^\mathrm{T})}{\prod_{w_{i'}\in W_j^\mathrm{T}}P(w_{i'}^\mathrm{T}|z_j^\mathrm{T}=k_{ij}^\mathrm{T},d_j^\mathrm{T})}\\ &=\prod_{w_{i'}\in W_j^\mathrm{T}}P(o_{i'j}^\mathrm{T}|z_j^\mathrm{T}=k_{ij}^\mathrm{T},w_{i'}^\mathrm{T},d_j^\mathrm{T}). \end{aligned}\tag{16} bkijT(O∗jT)=P(O∗jT∣zjT=kijT,WjT,djT)=P(WjT∣zjT=kijT,djT)P(WjT,O∗jT∣zjT=kijT,djT)=P(WjT∣zjT=kijT,djT)P(WjT∣O∗jT,zjT=kijT,djT)P(O∗jT∣zjT=kijT,djT)=∏wi′∈WjTP(wi′T∣zjT=kijT,djT)∏wi′∈WjTP(wi′T∣O∗jT,zjT=kijT,djT)∏wi′∈WjTP(oijT∣zjT=kijT,djT)=wi′∈WjT∏P(oi′jT∣zjT=kijT,wi′T,djT).(16)
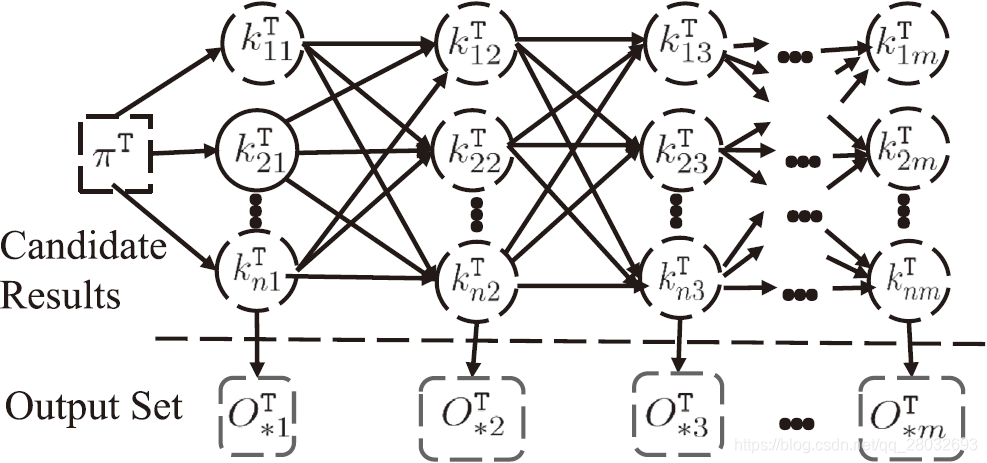
图5. HMM用于结果推理
这里,如 P ( W j T ∣ O ∗ j T , z j T = k i j T , d j T ) P ( O ∗ j T ∣ z j T = k i j T , d j T ) = P ( W j T , O ∗ j T ∣ z j T = k i j T , d j T ) P(W_j^\mathrm{T}|O_{*j}^\mathrm{T},z_j^\mathrm{T}=k_{ij}^\mathrm{T},d_j^\mathrm{T})P(O_{*j}^\mathrm{T}|z_j^\mathrm{T}=k_{ij}^\mathrm{T},d_j^\mathrm{T})=P(W_j^\mathrm{T},O_{*j}^\mathrm{T}|z_j^\mathrm{T}=k_{ij}^\mathrm{T},d_j^\mathrm{T}) P(WjT∣O∗jT,zjT=kijT,djT)P(O∗jT∣zjT=kijT,djT)=P(WjT,O∗jT∣zjT=kijT,djT),第三步可以从第二步推理出来。由于在上下文信息中假定工人彼此独立,第四步可以直接获得。
为了简单起见,我们假设子任务的候选输出遵循 K j T K_j^\mathrm{T} KjT中的统一分布,即 p ( z j T ) = 1 ∣ K j T ∣ p(z_j^\mathrm{T})=\frac{1}{|K_j^\mathrm{T}|} p(zjT)=∣KjT∣1。注意,候选输出的其他分布也可以同样应用。
对于没有真值标签的 C S T \mathrm{CST} CST,可以用公式(14)计算状态转移矩阵 A \mathcal{A} A,用公式(16)给出输出概率,并设置两个参数 D T D^\mathrm{T} DT和 W T W^\mathrm{T} WT,从而将 I C O V \mathrm{ICOV} ICOV问题转化为在隐马尔可夫模型 λ T \lambda^\mathrm{T} λT中搜索最可能的隐态序列的问题。换句话说,给定 O O O和 λ \lambda λ,目标是找到解释 O O O的最佳状态序列 C O V \mathrm{COV} COV,其目的是使 P ( c T ∣ λ T , O T ) P(c_\mathrm{T}|\lambda^\mathrm{T},O^\mathrm{T}) P(cT∣λT,OT)最大化。这是与HMM相关的基本问题之一[35]。因此,我们有:
c T ′ = arg max c T ∈ C T P ( c T ∣ λ T , O T ) = arg max c T ∈ C T P ( O T , c T ∣ λ T ) P ( O T ∣ λ T ) = arg max c T ∈ C T P ( O T , c T ∣ λ T ) ∑ c T ∈ C P ( O T , c T ∣ λ T ) = arg max c T ∈ C T P ( O T , c T ∣ λ T ) = arg max c T ∈ C T π o i 1 T ∏ k i j T ∈ c T b k i j T ( O ∗ j T ) f ( k i j + 1 T ∣ k i j T ) . (17) \begin{aligned} c'_\mathrm{T} &={\arg\max}_{c_\mathrm{T}\in\mathcal{C}^\mathrm{T}}P(c_\mathrm{T}|\lambda^\mathrm{T},O^\mathrm{T})\\ &={\arg\max}_{c_\mathrm{T}\in\mathcal{C}^\mathrm{T}}\frac{P(O^\mathrm{T},c_\mathrm{T}|\lambda^\mathrm{T})}{P(O^\mathrm{T}|\lambda^\mathrm{T})}\\ &={\arg\max}_{c_\mathrm{T}\in\mathcal{C}^\mathrm{T}}\frac{P(O^\mathrm{T},c_\mathrm{T}|\lambda^\mathrm{T})}{\sum_{c_\mathrm{T}\in C}P(O^\mathrm{T},c_\mathrm{T}|\lambda^\mathrm{T})}\\ &={\arg\max}_{c_\mathrm{T}\in\mathcal{C}^\mathrm{T}}P(O^\mathrm{T},c_\mathrm{T}|\lambda^\mathrm{T})\\ &={\arg\max}_{c_\mathrm{T}\in\mathcal{C}^\mathrm{T}}\pi_{o_{i1}^\mathrm{T}}\prod_{k_{ij}^\mathrm{T}\in c_\mathrm{T}}b_{k_{ij}^\mathrm{T}}(O_{*j}^\mathrm{T})f(k_{ij+1}^\mathrm{T}|k_{ij}^\mathrm{T}). \end{aligned}\tag{17} cT′=argmaxcT∈CTP(cT∣λT,OT)=argmaxcT∈CTP(OT∣λT)P(OT,cT∣λT)=argmaxcT∈CT∑cT∈CP(OT,cT∣λT)P(OT,cT∣λT)=argmaxcT∈CTP(OT,cT∣λT)=argmaxcT∈CTπoi1TkijT∈cT∏bkijT(O∗jT)f(kij+1T∣kijT).(17)
如果提供了参数集 D T D^\mathrm{T} DT和 W T W^\mathrm{T} WT,我们可以用维特比算法(Viterbi Algorithm)[5,36]计算 c T ′ c'_\mathrm{T} cT′来确定HMM的最可能隐藏状态序列。但是, λ T \lambda^\mathrm{T} λT有两个未知的参数集 W T W^\mathrm{T} WT和 D T D^\mathrm{T} DT,我们将在下一小节中描述如何学习参数。
4.3.3 参数学习
在本节中,我们讨论了 C o n t e x t − I n f \mathrm{Context-Inf} Context−Inf的参数学习(即 C S T \mathrm{CST} CST的HMM模型),目的是找到 λ ′ = arg max λ p ( O ∣ λ ′ ) \lambda'={\arg\max}_\lambda p(O|\lambda') λ′=argmaxλp(O∣λ′)。这里 λ T = ( A T , B T , π T ) \lambda^\mathrm{T}=(\mathcal{A}^\mathrm{T},\mathcal{B}^\mathrm{T},\pi^\mathrm{T}) λT=(AT,BT,πT)。从外部知识库中直接得到 ( A T (\mathcal{A}^\mathrm{T} (AT,通过计算工人的答案得到 π T \pi^\mathrm{T} πT,用 b k i j T ( O ∗ j T ) b_{k_{ij}^\mathrm{T}}(O_{*j}^\mathrm{T}) bkijT(O∗jT)得到 B \mathcal{B} B, b k i j T ( O ∗ j T ) b_{k_{ij}^\mathrm{T}}(O_{*j}^\mathrm{T}) bkijT(O∗jT)包含两个参数集 ( D , W ) (D,W) (D,W)。对于参数集 W W W,我们将使用最大似然估计和黄金测试任务。参数集 D D D可以通过使用EM来学习HMM[36]的参数,这类似于我们前面提到的 B a y e s − I n f \mathrm{Bayes-Inf} Bayes−Inf中的参数学习和文献[46]中的EM算法。
(1). 黄金测试任务参数学习
本小节介绍了如何使用黄金测试的最大似然估计(MLE)算法估计准确度参数 W W W。
对于测试任务 T ′ \mathrm{T'} T′,上下文矩阵 C T ′ C^\mathrm{T'} CT′、真值标签 Z T ′ Z^\mathrm{T'} ZT′和观测变量 O ∗ j T ′ O_{*j}^\mathrm{T'} O∗jT′都是已知的。与4.3.2节类似,我们使用隐马尔可夫模型 λ T ′ = ( A T ′ , B T ′ , π T ′ ) \lambda^\mathrm{T'}=(\mathcal{A}^\mathrm{T'},\mathcal{B}^\mathrm{T'},\pi^\mathrm{T'}) λT′=(AT′,BT′,πT′)来捕获测试任务 T \mathrm{T} T子任务之间的上下文相关性,其中HMM λ T ′ \lambda^\mathrm{T'} λT′的最可能隐藏状态序列是 Z T Z^\mathrm{T} ZT, A T ′ = C T \mathcal{A}^\mathrm{T'}=C^\mathrm{T} AT′=CT和 B T ′ = b z j T ′ ( O ∗ j T ′ ) \mathcal{B}^\mathrm{T'}=b_{z_j^\mathrm{T'}}(O_{*j}^\mathrm{T'}) BT′=bzjT′(O∗jT′),其中 b z j T ′ ( O ∗ j T ′ ) b_{z_j^\mathrm{T'}}(O_{*j}^\mathrm{T'}) bzjT′(O∗jT′)由公式(16)定义,有两个未知参数集 W T ′ W^\mathrm{T'} WT′和 D T ′ D^\mathrm{T'} DT′。为了学习参数 W T ′ W^\mathrm{T'} WT′, D T ′ D^\mathrm{T'} DT′,我们给出了测试任务 T ′ \mathrm{T'} T′的似然函数 l T ′ l_\mathrm{T'} lT′:
l T ′ ( W T ′ , D T ′ ) = ln P ( C T ′ , Z T ′ ∣ λ T ′ ) = ln ( π z 1 T ′ ∏ j = 1 m f ( z j + 1 T ′ ∣ z j T ′ ) b z j T ′ ( O ∗ j T ′ ) ) = ln π z 1 T ′ + ∑ j = 1 m ln f ( z j + 1 T ′ ∣ z j T ′ ) + ∑ j = 1 m ln b z j T ′ ( O ∗ j T ′ ) . (18) \begin{aligned} l_\mathrm{T'}(W^\mathrm{T'},D^\mathrm{T'}) &=\ln P(C^\mathrm{T'},Z^\mathrm{T'}|\lambda^\mathrm{T'})\\ &=\ln(\pi_{z_1}^\mathrm{T'}\prod_{j=1}^m f(z_{j+1}^\mathrm{T'}|z_j^\mathrm{T'})b_{z_j^\mathrm{T'}}(O_{*j}^\mathrm{T'}))\\ &=\ln\pi_{z_1}^\mathrm{T'}+\sum_{j=1}^m\ln f(z_{j+1}^\mathrm{T'}|z_j^\mathrm{T'})+\sum_{j=1}^m\ln b_{z_j^\mathrm{T'}}(O_{*j}^\mathrm{T'}). \end{aligned}\tag{18} lT′(WT′,DT′)=lnP(CT′,ZT′∣λT′)=ln(πz1T′j=1∏mf(zj+1T′∣zjT′)bzjT′(O∗jT′))=lnπz1T′+j=1∑mlnf(zj+1T′∣zjT′)+j=1∑mlnbzjT′(O∗jT′).(18)
利用公式(18),我们希望最大化 l T ′ l_\mathrm{T'} lT′。因为第一项和第二项是常数,所以似然函数 l T ′ l_\mathrm{T'} lT′的最大值取决于第三项。第三项与输出函数 b z j T ′ ( O ∗ j T ′ ) b_{z_j^\mathrm{T'}}(O_{*j}^\mathrm{T'}) bzjT′(O∗jT′)相关,独立于黄金测试任务中的子任务。因此,输出函数的参数学习与 B a y e s − I n f \mathrm{Bayes-Inf} Bayes−Inf的参数学习是相同的。
(2). 用EM算法进行推理
对于没有真值标签的 C S T \mathrm{CST} CST,类似于 B a y e s − I n f \mathrm{Bayes-Inf} Bayes−Inf,我们可以通过测试任务得到参数值 W T = W T ′ W^\mathrm{T}=W^\mathrm{T'} WT=WT′。 C o n t e x t − I n f \mathrm{Context-Inf} Context−Inf包含一个需要学习的参数集 D T = { d j T } D^\mathrm{T}=\{d_j^\mathrm{T}\} DT={djT}。
在HMM[5]的学习过程之前,我们首先回顾了前面的过程。我们定义
α j ( k i j ) = P ( O ∗ 1 , . . . , O ∗ j , k i j ∣ λ ) , \alpha_j(k_{ij})=P(O_{*1},...,O_{*j},k_{ij}|\lambda), αj(kij)=P(O∗1,...,O∗j,kij∣λ),
这是看到部分序列 O ∗ 1 , . . . , O ∗ j O_{*1},...,O_{*j} O∗1,...,O∗j的概率,在时间 j j j处结束于状态 i i i。我们可以有效地将 α i ( t ) \alpha_i(t) αi(t)递归定义为:
- α j ( k i 1 ) = π i T b k i j T ( O ∗ j T ) \alpha_j(k_{i1})=\pi_i^\mathrm{T}b_{k_{ij}^\mathrm{T}}(O_{*j}^\mathrm{T}) αj(ki1)=πiTbkijT(O∗jT)
- α j ( k i j T ) = [ ∑ i ′ = 1 ∣ K j − 1 T ∣ α j ( f ( k i j T ∣ k i ′ j − 1 T ) ) ] b k i j T ( O ∗ i T ) \alpha_j(k_{ij}^\mathrm{T})=[\sum_{i'=1}^{|K_{j-1}^\mathrm{T}|}\alpha_j(f(k_{ij}^\mathrm{T}|k_{i'j-1}^\mathrm{T}))]b_{k_{ij}^\mathrm{T}}(O_{*i}^\mathrm{T}) αj(kijT)=[∑i′=1∣Kj−1T∣αj(f(kijT∣ki′j−1T))]bkijT(O∗iT)
- P ( O ∣ λ ) = ∑ j = 1 N α j ( T ) P(O|\lambda)=\sum_{j=1}^N\alpha_j(T) P(O∣λ)=∑j=1Nαj(T)
反向过程类似: β j ( t ) = P ( O ∗ t + 1 , . . . , O ∗ T ∣ k i t , λ ) \beta_j(t)=P(O_{*t+1},...,O_{*T}|k_{it},\lambda) βj(t)=P(O∗t+1,...,O∗T∣kit,λ),这是看到部分序列 O ∗ t + 1 , . . . , O ∗ T O_{*t+1},...,O_{*T} O∗t+1,...,O∗T的概率,并在时间 t t t从状态 i i i开始。我们可以有效地将 β j ( t ) \beta_j(t) βj(t)递归定义为:
- β j ( k i 1 ) = 1 \beta_j(k_{i1})=1 βj(ki1)=1
- β j ( k i j T ) = ∑ i ′ = 1 ∣ K j + 1 T ∣ f ( k i ′ j + 1 T ∣ k i j T ) β i j ( k i ′ j + 1 T ) b k i j T ( O ∗ j T ) \beta_j(k_{ij}^\mathrm{T})=\sum_{i'=1}^{|K_{j+1}^\mathrm{T}|}f(k_{i'j+1}^\mathrm{T}|k_{ij}^\mathrm{T})\beta_{ij}(k_{i'j+1}^\mathrm{T})b_{k_{ij}^\mathrm{T}}(O_{*j}^\mathrm{T}) βj(kijT)=∑i′=1∣Kj+1T∣f(ki′j+1T∣kijT)βij(ki′j+1T)bkijT(O∗jT)
- P ( O ∣ λ ) = ∑ j = 1 N β j ( 1 ) π i b j ( O ∗ 1 ) P(O|\lambda)=\sum_{j=1}^N\beta_j(1)\pi_i b_j(O_{*1}) P(O∣λ)=∑j=1Nβj(1)πibj(O∗1)
基于HMM中描述的马尔可夫性质的条件独立性,我们将概率 p k i j T p^{k_{ij}^\mathrm{T}} pkijT定义为:
P k i j T = P ( O T , k i j T ∣ λ T ) = P ( O ∗ 1 , . . . , O ∗ j , k i j T ∣ λ T ) P ( O ∗ j + 1 , . . . , O ∗ m ∣ k i j T , λ T ) = α j ( k i j T ) β j ( k i j T ) , (19) \begin{aligned} P^{k_{ij}^\mathrm{T}} &=P(O^\mathrm{T},k_{ij}^\mathrm{T}|\lambda^\mathrm{T})\\ &=P(O_{*1},...,O_{*j},k_{ij}^\mathrm{T}|\lambda^\mathrm{T})P(O_{*j+1},...,O_{*m}|k_{ij}^\mathrm{T},\lambda^\mathrm{T})\\ &=\alpha_j(k_{ij}^\mathrm{T})\beta_j(k_{ij}^\mathrm{T}), \end{aligned}\tag{19} PkijT=P(OT,kijT∣λT)=P(O∗1,...,O∗j,kijT∣λT)P(O∗j+1,...,O∗m∣kijT,λT)=αj(kijT)βj(kijT),(19)
E-步骤: 让 c T = < k i 1 1 T , . . . , k i j j T , . . . , k i m m T > c^\mathrm{T}=<k_{i_11}^\mathrm{T},...,k_{i_jj}^\mathrm{T},...,k_{i_mm}^\mathrm{T}> cT=<ki11T,...,kijjT,...,kimmT>是 C S T \mathrm{CST} CST的 C O V \mathrm{COV} COV。 C T C_\mathrm{T} CT是 C S T \mathrm{CST} CST正确答案的后验概率可以得到:
P ( O T , c T ∣ λ o l d T ) = π k i l 1 T ∏ j = 0 m f ( k i j j T ∣ k i j − 1 j − 1 T ) b k i j j T ( O ∗ j T ) , (20) P(O^\mathrm{T},c^\mathrm{T}|\lambda_{old}^\mathrm{T})=\pi_{k_{i_l1}^\mathrm{T}}\prod_{j=0}^mf(k_{i_jj}^\mathrm{T}|k_{{i_{j-1}}j-1}^\mathrm{T})b_{k_{i_jj}^\mathrm{T}}(O_{*j}^\mathrm{T}),\tag{20} P(OT,cT∣λoldT)=πkil1Tj=0∏mf(kijjT∣kij−1j−1T)bkijjT(O∗jT),(20)
M-步骤:
设
C
T
\mathcal{C}^\mathrm{T}
CT为所有可能的
C
O
V
\mathrm{COV}
COV的集合,对数似然函数
Q
Q
Q定义如下:
Q ( λ T , λ o l d T ) = ∑ c T ∈ C T ln P ( O T , c T ∣ λ T ) p ( O T , c T ∣ λ o l d T ) = ∑ c T ∈ C T ln π k i 1 1 T P ( O T , c T ∣ λ o l d T ) + ∑ c T ∈ C T ( ∑ j = 1 m ln ( f ( k i j j T ∣ k i j − 1 j − 1 T ) ) ) P ( O T , c T ∣ λ o l d T ) + ∑ c T ∈ C T ( ∑ j = 1 m ln ( b k i j j T ( O ∗ j T ) ) ) P ( O T , c T ∣ λ o l d T ) . (21) \begin{aligned} Q(\lambda^\mathrm{T},\lambda_{old}^\mathrm{T}) &=\sum_{c_\mathrm{T}\in\mathcal{C}^\mathrm{T}}\ln P(O^\mathrm{T},c_\mathrm{T}|\lambda^\mathrm{T})p(O^\mathrm{T},c_\mathrm{T}|\lambda_{old}^\mathrm{T})\\ & \begin{aligned} =&\sum_{c_\mathrm{T}\in\mathcal{C}^\mathrm{T}}\ln \pi_{k_{i_11}^\mathrm{T}}P(O^\mathrm{T},c_\mathrm{T}|\lambda_{old}^\mathrm{T})\\ &+\sum_{c_\mathrm{T}\in\mathcal{C}^\mathrm{T}}(\sum_{j=1}^m\ln(f(k_{i_jj}^\mathrm{T}|k_{{i_{j-1}}j-1}^\mathrm{T})))P(O^\mathrm{T},c_\mathrm{T}|\lambda_{old}^\mathrm{T})\\ &+\sum_{c_\mathrm{T}\in\mathcal{C}^\mathrm{T}}(\sum_{j=1}^m\ln(b_{k_{i_jj}^\mathrm{T}}(O_{*j}^\mathrm{T})))P(O^\mathrm{T},c_\mathrm{T}|\lambda_{old}^\mathrm{T}). \end{aligned} \end{aligned}\tag{21} Q(λT,λoldT)=cT∈CT∑lnP(OT,cT∣λT)p(OT,cT∣λoldT)=cT∈CT∑lnπki11TP(OT,cT∣λoldT)+cT∈CT∑(j=1∑mln(f(kijjT∣kij−1j−1T)))P(OT,cT∣λoldT)+cT∈CT∑(j=1∑mln(bkijjT(O∗jT)))P(OT,cT∣λoldT).(21)
因此,我们可以区分 Q Q Q来得到梯度:
∂ Q ∂ d j T = ∑ i j = 0 ∣ K j T ∣ P k i j j T ∑ i = 1 n δ ( o i j T , k i j j T ) − σ ( k i j j T ) 1 − σ ( k i j j T ) w i T ln ( a i j j T ) , (22) \frac{\partial Q}{\partial d_j^\mathrm{T}}=\sum_{i_j=0}^{|K_j^\mathrm{T}|}P^{k_{i_jj}^\mathrm{T}}\sum_{i=1}^n\frac{\delta(o_{ij}^\mathrm{T},k_{i_jj}^\mathrm{T})-\sigma(k_{i_jj}^\mathrm{T})}{1-\sigma(k_{i_jj}^\mathrm{T})}w_i^\mathrm{T}\ln(a_{i_jj}^\mathrm{T}),\tag{22} ∂djT∂Q=ij=0∑∣KjT∣PkijjTi=1∑n1−σ(kijjT)δ(oijT,kijjT)−σ(kijjT)wiTln(aijjT),(22)
其中 P k i j j T P^{k_{i_jj}^\mathrm{T}} PkijjT是根据最后一个E-步骤估计的参数值 λ o l d \lambda^{old} λold推理得出的。这里,与 B a y e s − I n f \mathrm{Bayes-Inf} Bayes−Inf类似,我们使用 D o l d T ∈ λ o l d D_{old}^\mathrm{T}\in\lambda^{old} DoldT∈λold通过梯度上升更新新的 D T ∈ λ D^\mathrm{T}\in\lambda DT∈λ,从而在当前步骤中局部最大化 Q Q Q。然后采用E-步骤和M-步骤迭代法,通过最大化 Q Q Q来计算 D T D^\mathrm{T} DT。
5 POMDP迭代决策
本节研究 I D P \mathrm{IDP} IDP问题以确定是否终止迭代过程。迭代改进方法如图2所示。当前轮次中的工人将被显示上一轮的结果,并要求对其进行改进。这个过程具有马尔可夫的性质。形式上,让 q c ∈ [ 0 , 1 ] q_c \in[0,1] qc∈[0,1]和 q c + 1 ∈ [ 0 , 1 ] q_{c+1}\in[0,1] qc+1∈[0,1]分别表示 c T ′ c'_\mathrm{T} cT′和 c T c_\mathrm{T} cT的质量,我们知道工人有 1 − q c + 1 1−q_{c+1} 1−qc+1选择 c T ′ c'_\mathrm{T} cT′的概率。由于 ( q c , q c + 1 ) (q_c,q_{c+1}) (qc,qc+1)只是部分可观测的,而当前迭代的结果只依赖于先前的迭代,因此我们可以将此问题表述为部分可观测的马尔可夫决策问题(Partially Observable Markov Decision Problem, P O M D P \mathrm{POMDP} POMDP)。
定义5(CST的POMDP)。 C S T \mathrm{CST} CST的 P O M D P \mathrm{POMDP} POMDP是一个六元组 ⟨ S , Λ , R , T , O , P ⟩ \langle\mathcal{S},\Lambda,\mathcal{R},\mathcal{T},\mathcal{O},\mathcal{P}\rangle ⟨S,Λ,R,T,O,P⟩,其中
- S = { ⟨ q c + 1 , q c ⟩ } \mathcal{S}=\{ \langle q_{c+1},q_c\rangle\} S={⟨qc+1,qc⟩}是一组有限的离散状态, q c + 1 q_{c+1} qc+1和 q c q_c qc分别是 c T ′ c'_\mathrm{T} cT′和 c T c_\mathrm{T} cT的质量;
- Λ = { \Lambda=\{ Λ={创建新的众包任务,提交推理输出 } \} }是动作集;
- R = R 0 + R S \mathcal{R}=\mathcal{R}_0+\mathcal{R}_S R=R0+RS是奖励函数, R 0 \mathcal{R}_0 R0是为工人参与而向其支付的固定金额, R S \mathcal{R}_S RS是基于工人贡献质量 q q q的动态奖励;
- T \mathcal{T} T: S × O × S → [ 0 , 1 ] \mathcal{S}\times\mathcal{O}\times\mathcal{S}\rightarrow[0,1] S×O×S→[0,1]为转换函数,具体如下:
- O = { c T ′ , c T } \mathcal{O}=\{ c'_\mathrm{T},c_\mathrm{T}\} O={cT′,cT}是一组有限的观察结果, c T ′ c'_\mathrm{T} cT′和 c T c_\mathrm{T} cT在我们的 C o n t e x t − I n f \mathrm{Context-Inf} Context−Inf模型中定义;
- P \mathcal{P} P: S × O → [ 0 , 1 ] \mathcal{S}\times\mathcal{O}\rightarrow[0,1] S×O→[0,1]是观测函数。
转换函数。 当一个新的推理结果生成并且当前状态 ( q c , q c + 1 ) (q_c,q_{c+1}) (qc,qc+1)未知时,就会调用问题中的状态转换。 c T c_\mathrm{T} cT的质量取决于对所有的工人 ( 1 , 2 , . . . , n ) (1,2,...,n) (1,2,...,n)。由于每个工人都是独立的,每个工人都可以改进 C O V \mathrm{COV} COV,推理结果遵循条件分布 f ( q c + 1 ∣ q c , i ) f(q_{c+1}|q_c,i) f(qc+1∣qc,i),我们可以计算转换函数,即 f ( q c + 1 ∣ q c , i 1 = 1 , i 2 = 2 , . . . , i n = n ) f(q_{c+1}|q_c,i_1=1,i_2=2,...,i_n=n) f(qc+1∣qc,i1=1,i2=2,...,in=n),
f ( q c + 1 ∣ q c , i 1 , i 2 , . . . , i n ) = ∑ i = 1 n γ i ⋅ f ( q c + 1 ∣ q c , i ) , (23) f(q_{c+1}|q_c,i_1,i_2,...,i_n)=\sum_{i=1}^n\gamma_i·f(q_{c+1}|q_c,i),\tag{23} f(qc+1∣qc,i1,i2,...,in)=i=1∑nγi⋅f(qc+1∣qc,i),(23)
其中 γ i \gamma_i γi是转换函数混合条件分布的参数, ∑ i = 1 n γ i = 1 \sum_{i=1}^n\gamma_i=1 ∑i=1nγi=1-。我们可以计算 γ i = 1 w i ∑ i ′ = 1 n 1 w i ′ \gamma_i=\frac{\frac{1}{w_i}}{\sum_{i'=1}^n\frac{1}{w_{i'}}} γi=∑i′=1nwi′1wi1,其中 w i w_i wi由EM算法计算(见第4节)。
置信度更新。 在我们的模型中,基于子任务的难度和工人的准确度,可以改变对先前聚合结果质量的置信度。如果输出质量已经很高,而且所有子任务都不容易改进,那么我们应该增加 c T ′ c'_\mathrm{T} cT′的质量估计。同样,如果大多数工人都同意当前的结果 c T c_\mathrm{T} cT而不是上一步的结果 c T ′ c'_\mathrm{T} cT′,那么很可能我们可以显著提高 c T ′ c'_\mathrm{T} cT′,并且质量应该反映出这些知识。为了更新其对每个改进步骤质量的了解, C o n t e x t − I n f \mathrm{Context-Inf} Context−Inf首先使用子任务的质量估计来估计子任务的难度,并且可以给出改进的难度 d i c d_i^c dic。对于所有子任务,我们可以给出向量 ⟨ d 1 c , d 2 c , . . . , d m c ⟩ \langle d_1^c,d_2^c,...,d_m^c\rangle ⟨d1c,d2c,...,dmc⟩,计算 C S T \mathrm{CST} CST的难度如下:
d T c = ∏ j m d j c . (24) d_T^c=\prod_j^m d_j^c.\tag{24} dTc=j∏mdjc.(24)
观测函数。虽然我们不确定新的聚合结果是否优于旧的结果。我们给出了同样的场景:我们为员工提供 C S T \mathrm{CST} CST和候选人答案,并要求员工选择最佳结果。我们根据 C o n t e x t − I n f \mathrm{Context-Inf} Context−Inf评估每个 C O V \mathrm{COV} COV的质量。在结果推理中,当前聚合结果的 C O V c T \mathrm{COV}\ c_\mathrm{T} COV cT和先前聚合结果的 C O V c T ′ \mathrm{COV}\ c'_\mathrm{T} COV cT′的全局评估指标 P r ( c T ) = p ( O , c T ∣ λ ) Pr(c_\mathrm{T})=p(O,c_\mathrm{T}|\lambda) Pr(cT)=p(O,cT∣λ),我们可以计算观测函数:
P r ( q c + 1 > q c ∣ c T , c T ′ ) = P r ( c T ) P r ( c T ′ ) + P r ( c T ) . (25) Pr(q_{c+1}>q_c|c_\mathrm{T},c'_\mathrm{T})=\frac{Pr(c_\mathrm{T})}{Pr(c'_\mathrm{T})+Pr(c_\mathrm{T})}.\tag{25} Pr(qc+1>qc∣cT,cT′)=Pr(cT′)+Pr(cT)Pr(cT).(25)
定义5描述了处理CST的控制模型,我们的目标是获得更好的效用,所以我们定义了效用估计。
效用估计。 然后我们讨论如何估计众包任务的效用。在这一点上,我们已经收到k工人的n个输出。基于我们的 C o n t e x t − I n f \mathrm{Context-Inf} Context−Inf模型,我们可以得到装配结果及其质量 q c q_c qc。设 Δ ( q ) = q c − q c − 1 \Delta(q)=q_c-q_{c-1} Δ(q)=qc−qc−1, R s = μ S ( q c ) = e Δ q − 1 e − 1 \mathcal{R}_s=\mu_\mathcal{S}(q_c)=\frac{e^{\Delta q}-1}{e-1} Rs=μS(qc)=e−1eΔq−1表示当前迭代的效用。如果是 Δ q = 0 \Delta q=0 Δq=0, μ S ( Δ q ) = 0 \mu_\mathcal{S}(\Delta q)=0 μS(Δq)=0;否则是(如果是 Δ q = 1 \Delta q=1 Δq=1), μ S ( Δ q ) = R s \mu_\mathcal{S}(\Delta q)=\mathcal{R}_s μS(Δq)=Rs,它表示工人在第一次迭代中完全和准确地完成任务的概率。那么我们的效用估计方程如下:
V ( S ) = − R 0 ∗ k + μ S ( Δ q ) . (26) \mathcal{V(S)}=-\mathcal{R}_0*k+\mu_\mathcal{S}(\Delta q).\tag{26} V(S)=−R0∗k+μS(Δq).(26)
考虑到当前状态 S \mathcal{S} S和下一个状态 S ′ \mathcal{S}' S′,如果 S ′ > S \mathcal{S}'>\mathcal{S} S′>S,我们转到 S ′ \mathcal{S}' S′;否则我们保持当前状态 S \mathcal{S} S。
利用定义5和效用估计函数(公式(26)),我们可以迭代地利用众包提高CST过程的质量。当成本达到请求者提供的奖励预算,或者随着迭代次数的增加质量不能进一步提高时,迭代过程将终止。注意,与现有方法不同,我们的模型具有较少的状态数,从而降低了决策复杂性。
6 实验评估
我们在两组具有代表性的 C S T \mathrm{CST} CST上进行了大量的实际实验,并与最先进的方法进行了比较。在本节中,我们将介绍我们的模型和算法的评估结果。
6.1. 实验评估
在我们的实验中,我们选择了两组任务:手写识别和音频转录。它们都包含了 C S T \mathrm{CST} CST的典型特征,其中每个任务都由一组子任务组成,子任务之间的上下文关联对于从人群中获得高质量的结果至关重要。所有的任务都发表在CrowdFlower上。我们将在后面详细描述每一组任务的众包流程。
评估从三个方面进行:
- 任务分割策略如何影响结果质量;
- 上下文关联对结果推断的重要性;
- 迭代众包如何提高结果质量。
对于第二次评估,运行以下四种推理方法进行比较:
- Task-Inf: 这种推理方法是任务导向方法(即多投票)的一种实现,并在文献[40]中提出。
- SAM: 这是我们在[17]中提出的方法,在这里我们考虑了 C S T \mathrm{CST} CST的内部结构以及工人在一个子任务中的表现对其他子任务结果推断的影响。我们已经在[17]中证明了SAM优于现有方法[9,40,46]。
- Bayes-Inf: 这是第4.2节中描述的面向子任务方法的实现。
- Context-Inf: 这是第4.2节中描述的面向子任务方法的实现。
我们实现了上述四种方法的相应迭代版本,分别表示为 i T a s k − I n f \mathrm{iTask-Inf} iTask−Inf、 i S A M \mathrm{iSAM} iSAM、 i B a y e s − I n f \mathrm{iBayes-Inf} iBayes−Inf和 i C o n t e x t − I n f \mathrm{iContext-Inf} iContext−Inf,并运行它们进行第三次评估。
对于这两组任务,我们使用谷歌n-gram Viewer计算子任务之间的上下文关联。为了简单起见,我们使用2-gram根据等式(15)计算上下文相关。
为了获得 C S T T \mathrm{CST\ T} CST T中子任务 j j j的两个候选结果的: k i j T k_{ij}^\mathrm{T} kijT和 k i ′ j T k_{i'j}^\mathrm{T} ki′jT相似度,我们直接计算了手写识别任务中两个单词(字符串)的外观相似度。对于音频识别任务,我们使用两个单词(字符串)对应的语音符号的外观来计算它们的相似度。最后,我们得到了下面的公式来计算公式(3)中使用的两个候选输出的相似度:
s i m ( k i j T , k i ′ j T ) = ∑ i = 1 N s i N . (27) sim(k_{ij}^\mathrm{T},k_{i'j}^\mathrm{T})=\frac{\sum_{i=1}^Ns_i}{N}.\tag{27} sim(kijT,ki′jT)=N∑i=1Nsi.(27)
这里, N N N表示字符串的长度, s i s_i si表示两个字符的外观相似性,由OpenCV软件计算。
6.2 手写识别结果
6.2.1 数据集和准备工作
对于手写识别任务,向工人展示两张包含手写文本的图像,并要求他们转录文本。数据集是从IAM数据库[30,31]获取的。我们从500位不同作者提供的1500幅包含手写文本的图片中随机选取30幅。每幅图像有5-11行文本,其中最大包含8个句子。我们将手写文本分成句子,然后总共得到130个句子。我们把每一句话都看作是在CrowdFlower上发表的一项任务。每一页包含10个任务,每个任务的成本为4美分,由5名来自CrowdFlower的3级质量工人处理。完成任务的最后期限设置为1天。
6.2.2 任务分割策略
正如我们所讨论的,很难定义 C S T \mathrm{CST} CST的一般任务分割策略。因此,我们通过观察字迹识别任务随任务粒度变化的结果质量,对这一问题进行了实证研究。在本实验中,我们使用五幅图像,每幅包含8个句子,来生成不同粒度的众包任务。我们设计了8个策略,通过改变 C S T \mathrm{CST} CST中包含的最大句子数。例如,策略5定义了2个 C S T \mathrm{CST} CST:一个有5个句子,另一个有3个句子。对于每个策略,我们将相应的 C S T \mathrm{CST} CST发布到CrowdFlower,并使用 C o n t e x t − I n f \mathrm{Context-Inf} Context−Inf进行结果推理。如图6(a)所示,当一个任务中有更多的句子时,平均结果质量从65%下降到近40%,这证实了我们的推测,工作量的增加会影响整体工人的准确性。因此,在下面的实验中,我们将 C S T \mathrm{CST} CST定义为只识别一个句子。
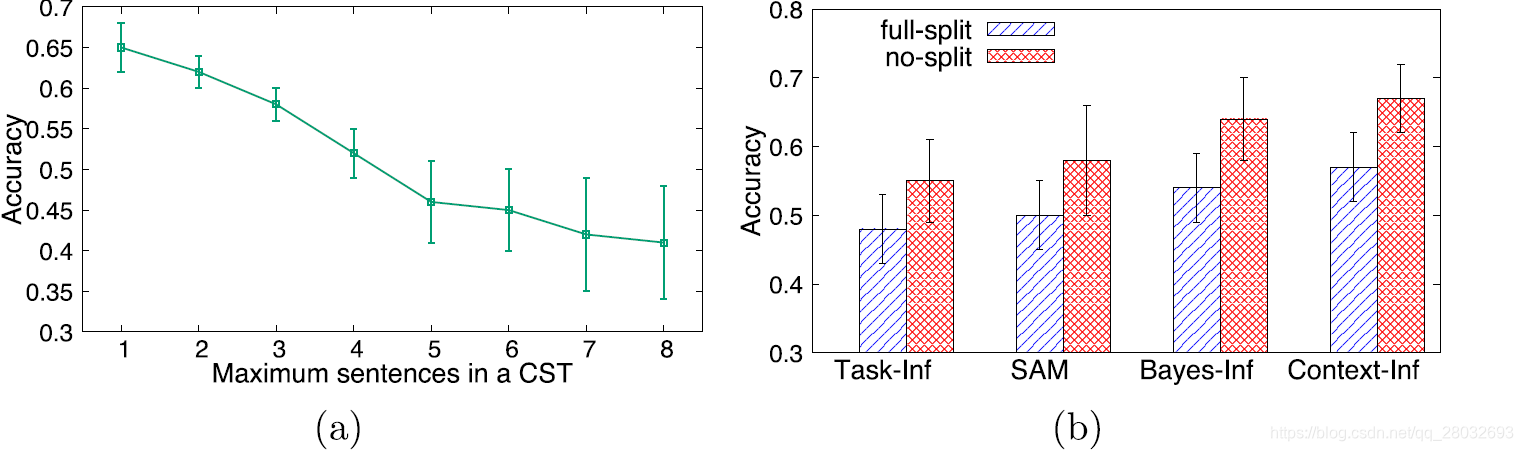
图6. 任务分割的评估;(a)不同任务分割策略的结果;(b)上下文关联的重要性
我们还进行了一项实验,以验证上下文相关是影响众包结果质量的一个重要因素。我们随机选取4张图片,共有19个句子由标点符号决定。我们比较了两种任务分割策略:无分割和完全分割。前者将每个句子作为任务发布,而后者将每个句子作为任务拆分为单独的单词。完全分割后,任务是识别图像中的一个词,所有任务都以随机顺序发布,这使得句子的上下文关联丢失。如图6(b)所示,与 C o n t e x t − I n f \mathrm{Context-Inf} Context−Inf、 B a y e s − I n f \mathrm{Bayes-Inf} Bayes−Inf、 S A M \mathrm{SAM} SAM和 T a s k − I n f \mathrm{Task-Inf} Task−Inf的完全拆分相比,没有任何拆分的精确度分别提高17.54%、18.52%、16%和14.6%。
6.2.3 结果推理的有效性
接下来,我们评估了这四种推理方法在30张图像中的所有任务的性能,共有130个 C S T \mathrm{CST} CST被分为6组。结果5组有20个任务,1组有30个任务。为了消除低质量工人,我们将每组任务与5个黄金任务分别混合。如果一个工人未能对5项黄金任务提供至少一个正确答案,她将被忽略。为了确保结果质量,每项任务需要得到5个答案。
图7(a)说明了用四种比较方法得到的每个任务的结果精度,图7(b)显示了每个图像的结果。我们可以看到 T a s k − I n f \mathrm{Task-Inf} Task−Inf执行得最差,因为它既不考虑影响结果质量的因素,也不考虑子任务之间的上下文关联。相比之下, C o n t e x t − I n f \mathrm{Context-Inf} Context−Inf优于其他三种方法,因为它将上下文关联合并到 B a y e s − I n f \mathrm{Bayes-Inf} Bayes−Inf使用的概率模型中。 S A M \mathrm{SAM} SAM表现优于 C o n t e x t − I n f \mathrm{Context-Inf} Context−Inf的原因是 S A M \mathrm{SAM} SAM可以通过考虑员工的表现更好地评估员工的能力。图7©显示了这四种方法的性能,显示 C o n t e x t − I n f \mathrm{Context-Inf} Context−Inf比 B a y e s − I n f \mathrm{Bayes-Inf} Bayes−Inf、 S A M \mathrm{SAM} SAM和 T a s k − I n f \mathrm{Task-Inf} Task−Inf分别强7.76%、12.62%和43.01%。
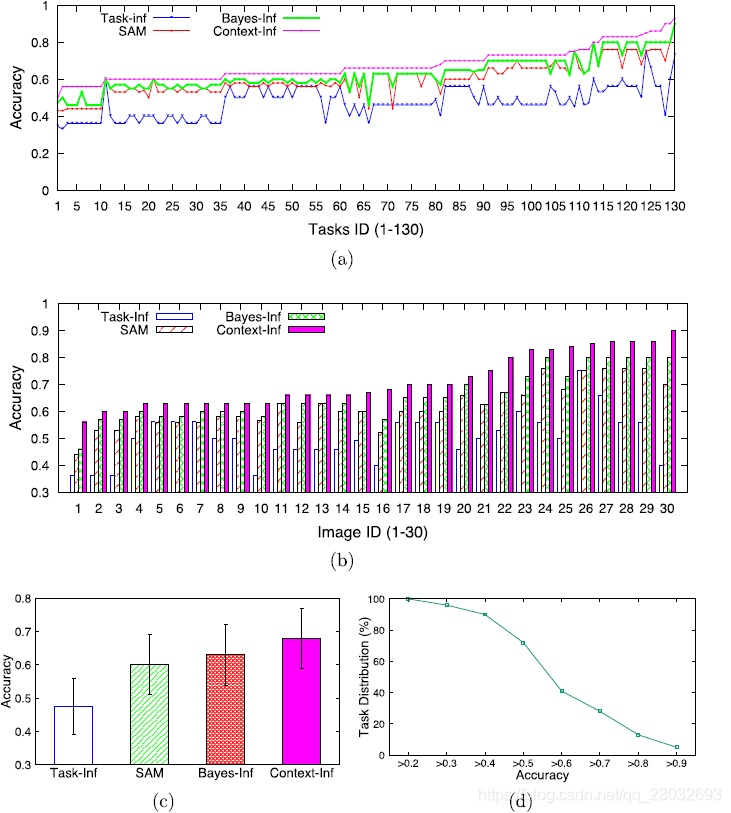
图7. 结果与结果推理;(a)所有130个任务的结果;(b)按每个图像的结果统计;(c )四种方法的总体结果;(d)处理精度的概率分布
6.2.4 迭代众包结果
图7(d)使用 C o n t e x t − I n f \mathrm{Context-Inf} Context−Inf绘制了不同结果精度值下的任务分布。我们可以看到,超过80%的任务精度低于0.75,这意味着任务需要多轮处理。
图8描绘了 i T a s k − I n f \mathrm{iTask-Inf} iTask−Inf、 i S A M \mathrm{iSAM} iSAM、 i B a y e s − I n f \mathrm{iBayes-Inf} iBayes−Inf和 i C o n t e x t − I n f \mathrm{iContext-Inf} iContext−Inf的实验结果。由于任务特征的不同,每个任务的迭代过程与其他任务的迭代过程有很大的不同。难度较高的任务比难度较低的任务需要更多迭代才能收敛。因此,我们首先随机选择一个 C S T \mathrm{CST} CST和一个具有3个 C S T \mathrm{CST} CST的图像来显示迭代处理的有效性,结果分别如图8(a)和(b)所示。我们可以观察到,众包的迭代次数越多,每个方法的结果质量就越好,经过一定次数的迭代,结果质量就不能再进一步提高。我们的方法( i C o n t e x t − I n f \mathrm{iContext-Inf} iContext−Inf)比其他三种方法在迭代次数较少的情况下获得更好的质量。由于更多的迭代意味着更多的成本,我们认为以性能成本比 P C R = q T l T PCR=\frac{q_\mathrm{T}}{l_\mathrm{T}} PCR=lTqT来衡量一种方法的有效性是公平的,其中 q T q_T qT表示 C S T \mathrm{CST} CST输出的准确性, l T l_\mathrm{T} lT表示迭代次数。图8©绘制了四种迭代方法在所有130个任务中的 P C R PCR PCR。我们的 i C o n t e x t − I n f \mathrm{iContext-Inf} iContext−Inf仍然优于其他四个。图8(d)给出了四种迭代方法的性能 i C o n t e x t − I n f \mathrm{iContext-Inf} iContext−Inf的精度分别比 i B a y e s − I n f \mathrm{iBayes-Inf} iBayes−Inf、 i S A M \mathrm{iSAM} iSAM和 i T a s k − I n f \mathrm{iTask-Inf} iTask−Inf高6%、8.39%和13.51%。然后,我们分别用肯德尔相关系数(Kendall Correlation Coefficients)和伦道夫系数(Randolph’s Coefficients)进行了统计检验,以显示结果的统计意义。对于130个任务, i C o n t e x t − I n f \mathrm{iContext-Inf} iContext−Inf和其他三种方法(即 i T a s k − I n f \mathrm{iTask-Inf} iTask−Inf、 i S A M \mathrm{iSAM} iSAM和 i B a y e s − I n f \mathrm{iBayes-Inf} iBayes−Inf)之间的肯德尔相关系数分别为0.528、0.5358和0.5765, i C o n t e x t − I n f \mathrm{iContext-Inf} iContext−Inf和其他三种方法(即 i T a s k − I n f \mathrm{iTask-Inf} iTask−Inf、 i S A M \mathrm{iSAM} iSAM和 i B a y e s − I n f \mathrm{iBayes-Inf} iBayes−Inf)之间的伦道夫系数分别为0.7683、0.8613和D分别为0.8986,这意味着 i C o n t e x t − I n f \mathrm{iContext-Inf} iContext−Inf始终优于这三种比较方法。
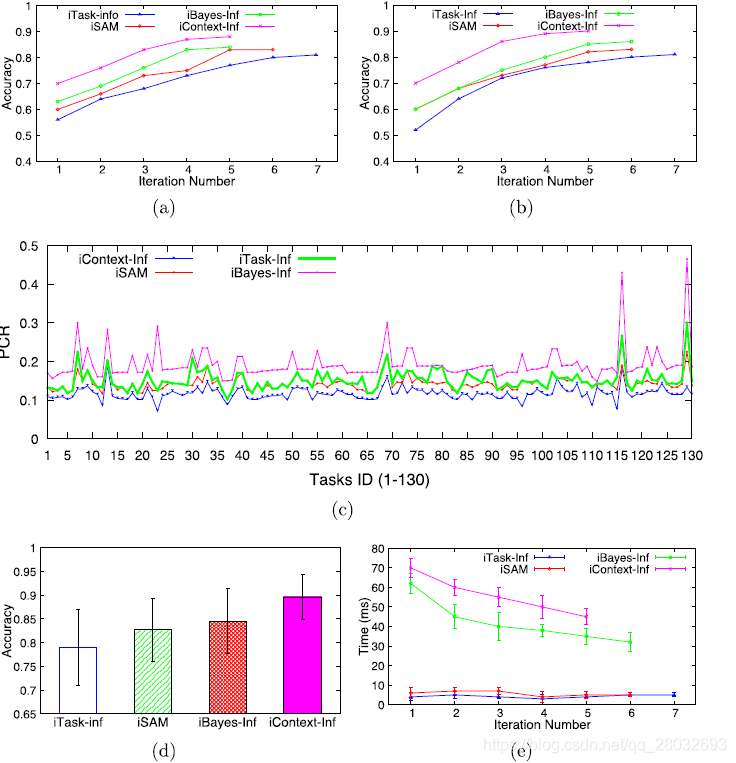
图8. 结果推断的有效性:(a)CST结果质量的迭代改进;(b)具有3个CST的图像结果质量的迭代改进;(c )迭代众包的性能成本比;(d)迭代众包的总体性能;(e)迭代众包的执行时间
图8(e)给出了四种迭代方法的执行时间。随着迭代次数的增加,要处理的子任务更少,因此所有推理方法的执行时间都缩短了。由于上下文关联计算,我们的方法在所有方法中的时间开销最大。然而,经过的时间仍在一秒钟内,这在实际应用中是可以接受的。即使花费更多的时间,我们的方法仍然可行,因为任务推断是离线执行的。
6.3 音频转录实验
6.3.1 数据集和准备工作
数据集是从CMU_ARCTIC数据库中获得的,该数据库由卡内基梅隆大学语言技术研究所构建,用于单元选择语音合成研究。我们选择了一个名为cmu-us-bdl-arctic的数据库,该数据库包含了一个特定风格的发言者发出的1200句话,共有1132个音频片段。每个剪辑包含一个句子,我们从数据库中随机选择35个剪辑,其中5个被认为是黄金测试任务。
与手写识别任务的实验设置类似,本实验每页包含10个任务,每个任务花费4美分,由5名质量等级为3的CrowdFlower工人处理。与音频剪辑相对应的子任务不能像手写任务那样直接获得,我们用OpenCV实现了这一点。当然,单词或成语之间会有停顿,这些停顿与接近零音量的部分相对应。在OpenCV中,我们分析了视频剪辑的波形,并将接近零音量的部分作为分割音频剪辑的分隔符。与手写识别实验相似,我们排除了那些无法对5个测试任务提供至少一个正确答案的工人。每项任务直到都收到5个有效答案被认为是完成的。
6.3.2 结果
图9(a)显示了这四种方法在30个任务中的结果质量。我们可以观察到与手写识别任务相似的比较结果,即 C o n t e x t − I n f \mathrm{Context-Inf} Context−Inf优于其他三个任务。根据图9(b)所示的总体结果,我们的 C o n t e x t − I n f \mathrm{Context-Inf} Context−Inf分别比 B a y e s − I n f \mathrm{Bayes-Inf} Bayes−Inf、 S A M \mathrm{SAM} SAM和 T a s k − I n f \mathrm{Task-Inf} Task−Inf好5.88%、11.11%和15.39%。毫不奇怪,如图9©所示, C o n t e x t − I n f \mathrm{Context-Inf} Context−Inf在这四种方法中花费的时间最多。但是,与我们对手写识别任务的分析类似,由于任务推理是离线进行的,因此有必要用额外的时间成本获得更好的结果质量。最重要的是,推理时间很短,例如只有50毫秒,这是可以接受的。
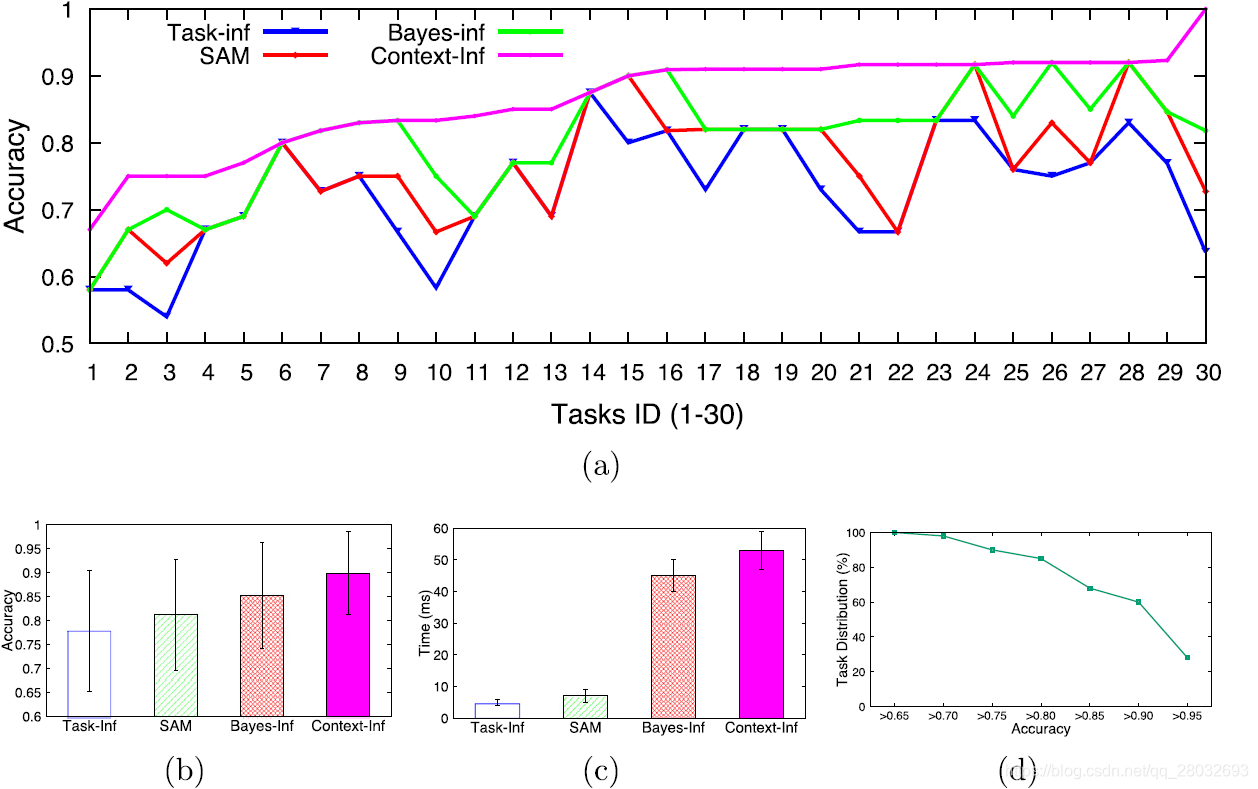
图9. 音频转录处理的结果;(2)按音频转录任务细分的结果;(b)四种方法的总体结果;(c )四种方法的执行时间;(d)具有处理精度的任务的概率分布
同时,我们给出了具有结果质量的任务的概率分布,如图9(d)所示。与手写识别任务不同,超过80%的音频转录任务的精度高达0.82。当我们继续用更多的迭代将任务众包起来时,大多数任务的结果质量不能得到很大的提高。原因是它已经达到了工人集体智慧的极限。
7 相关工作
上下文信息[6,11]是一种进化、结构化和共享的信息空间,旨在为特定目的服务,在许多不同领域的应用中发挥着重要作用。为了更好地处理任务,提出了许多考虑上下文相关的框架和模型(如[11,12,20,39])。同样,在众包上下文中,信息主要涉及时间相关性、语义相关性、空间相关性[32]和结构化相关性。有各种各样的众包任务是上下文敏感的,例如手写识别[30]、音频描述[3]和针对人口贩运的微博[42]。然而,利用上下文信息来提高众包质量的工作很少。下面,我们从任务特征和结果推断两个方面对现有众包研究的现状进行了总结。
就结构特点而言,现有工作跨越了广泛的任务范围,可分为两大阵营:原子任务和复合任务。原子任务是指那些不能从工人那里分为子任务的任务,例如图像标记[22]、同行评分[8]和情绪分析。复合任务通常由多个原子任务组成。此外,我们将复合任务分为两个子类别:上下文敏感任务和上下文无关任务。在上下文无关的任务中,组件子任务是独立的,这意味着将其拆分为子任务或不影响质量。典型的上下文无关任务包括群组计数、群组投票和任何类型的原子任务分组。对于上下文敏感的任务,子任务之间存在着密切的关联,任务的拆分会丢失上下文关联,严重影响任务的质量。尽管大量的任务都属于这一范畴,如文本识别[26]、翻译[47]、计划[45]和音频转录[34],但据我们所知,这并不是在结果推理中模拟上下文关联的工作。
为了进一步改进多数投票策略,有两个研究与众包任务的具体类型有关。对于孤立的任务,一些文献[18,38,48]提出了基于任务导向模型的结果推理方法(即,要求不同的工人执行相同的任务,直到对结果达成共识),以处理不准确并将成本降到最低;而对于复杂的任务,一些工作提出了基于子任务的其他推理方法。面向子任务的模型使用多阶段策略来处理任务[7,43]。CDAS[28]使用了质量敏感的回答模式。Askit[1]利用了熵样技术。Qasca研究了质量感知推理方法[52]。文献[14,16,29,50]的作者关注的是以提高结果准确性为目标的工人能力和任务主题的细粒度公式化。具体来说,为了提高推断结果的质量,Faitcrowd[29]给出了一种考虑到任务主题的更细粒度的源可靠性公式。为了提高结果的准确性,文献[14]提出了一种综合考虑源可靠性(即工人能力)和任务主题的通用细粒度方法。我们的初步工作[16]给出了一种概率方法,通过考虑备选答案之间的相似性来推断高质量的结果。文献[50]利用任务主题和工人可靠性,以外部知识库来模拟工人绩效。与这些系统相比,我们的方法考虑了任务中的上下文关联,取得了更好的结果质量。此外,为了获得工人的准确度或剔除低准确度的工人,也有许多算法通过资格考试和黄金考试来控制工人的质量,以获得匿名工人的准确度或通过考试剔除不良工人[23,38]。
与这些研究不同,我们关注的是上下文相关任务的结果推理。由于任务导向方法高估了员工处理复杂任务的能力,而子任务导向方法忽略了CST的上下文,因此无法获得高质量的结果。因此,我们提出了一种基于上下文感知的推理算法,该算法使用HMM模型来捕获任务中的上下文关联。此外,我们还提出了基于 P O M D P \mathrm{POMDP} POMDP的迭代工作流程来改进众包的任务处理。
8 结论
本文研究了环境敏感任务的质量控制问题。我们对这类任务进行了识别,并提出了一种新的推理算法( C o n t e x t − I n f \mathrm{Context-Inf} Context−Inf),该算法结合了HMM模型来捕获结果推理的上下文相关性。利用上下文信息,利用隐马尔可夫模型进行子任务级聚合得到结果。我们还提出了一个面向众包迭代处理的 P O M D P \mathrm{POMDP} POMDP模型。实际实验证明了该方法的优越性。
致谢
This work was supported partly by Natioanl Basic Research Program of China (2015CB358700, 2014CB340304), and NSFC program ( 61421003 ) and the State Key Laboratory of Software Development Environment under Grant No. SKLSDE-2017ZX- 14.
参考文献
[1] Y. Amsterdamer , D. Deutch , T. Milo , V. Tannen , On provenance minimization, ACM Trans. Database Syst. 37 (4) (2012) 30:1–30:36 .
[2] M. Avlonitis , I. Karydis , S. Sioutas , Early prediction in collective intelligence on video users activity, Inf. Sci. 298 © (2014) 315–329 .
[3] P.M. Baggenstoss , A modified baum-welch algorithm for hidden markov models with multiple observation spaces, Speech Audio Process., IEEE Trans. 9 (4) (2001) 411–416 .
[4] M.S. Bernstein , G. Little , R.C. Miller , B. Hartmann , M.S. Ackerman , D.R. Karger , D. Crowell , K. Panovich , Soylent: a word processor with a crowd inside, in: UIST2010, ACM, 2010, pp. 313–322 .
[5] J.A. Bilmes, et al., A gentle tutorial of the em algorithm and its application to parameter estimation for gaussian mixture and hidden markov models, ICSI TR-97-021 (1998).
[6] J. Coutaz , J.L. Crowley , S. Dobson , D. Garlan , Context is key, Commun. ACM 48 (3) (2005) 49–53 .
[7] P. Dai , C.H. Lin , Mausam , D.S. Weld , Pomdp-based control of workflows for crowdsourcing, Artif. Intell. 202 (2013) 52–85 .
[8] A. Dasgupta , A. Ghosh , Crowdsourced judgement elicitation with endogenous proficiency, in: WWW2013, ACM, 2013, pp. 319–330 .
[9] A.P. Dawid , A.M. Skene , Maximum likelihood estimation of observer error-rates using the em algorithm, Appl. Stat. (1979) 20–28 .
[10] J. Deng , W. Dong , R. Socher , L.J. Li , K. Li , L. Fei-Fei , Imagenet: a large-scale hierarchical image database, in: CVPR2009, 2009, pp. 248–255 .
[11] A.K. Dey , Understanding and using context, Pers. Ubiquitous Comput. 5 (1) (2001) 4–7 .
[12] A.K. Dey , G.D. Abowd , D. Salber , A conceptual framework and a toolkit for supporting the rapid prototyping of context-aware applications, Hum.-Comput. Interact. 16 (2) (2001) 97–166 .
[13] M. Dredze , P.P. Talukdar , K. Crammer , Sequence learning from data with multiple labels, in: ECML/PKDD, 2009, p. 39 .
[14] Y. Du , H. Xu , Y. Sun , L. Huang , A general fine-grained truth discovery approach for crowdsourced data aggregation, in: DASFAA 2017, 2017, pp. 3–18 .
[15] S.R. Eddy , Hidden markov models, Curr. Opin. Struct. Biol. 6 (3) (1996) 361 .
[16] Y. Fang , H. Sun , P. Chen , T. Deng , Improving the quality of crowdsourced image labeling via label similarity, J. Comput. Sci. Technol. 32 (5) (2017) 877–889 .
[17] Y. Fang , H. Sun , G. Li , R. Zhang , J. Huai , Effective result inference for context-sensitive tasks in crowdsourcing, in: DASFAA2016, 2016, pp. 33–48 .
[18] J. Feng , G. Li , H. Wang , J. Feng , Incremental quality inference in crowdsourcing, in: DASFAA2014, 2014, pp. 453–467 .
[19] H. Garcia-Molina , M. Joglekar , A. Marcus , A. Parameswaran , V.Verroios ,Challengesindatacrowdsourcing,IEEETrans.Knowl.DataEng.(2016) .
[20] T. Gu , H.K. Pung , D.Q. Zhang , A middleware for building context-aware mobile services, in: VTC 2004, 5, 2004, pp. 2656–2660Vol.5 .
[21] T. Han , H. Sun , Y. Song , Y. Fang , X. Liu , Incorporating external knowledge into crowd intelligence for more specific knowledge acquisition, in: IJCAI 2016„2016, pp. 1541–1547 .
[22] X. Hu, Y. Shan, G. Kesidis, S. Sarkar, R. Dhar, S. Fdida, Multiperiod subscription pricing for cellular wireless entrants (2016) 326–330.
[23] P.G. Ipeirotis , E. Gabrilovich , Quizz: targeted crowdsourcing with a billion (potential) users, in: WWW2014, 2014, pp. 143–154 .
[24] B. Lakshminarayanan, Y.W. Teh, Inferring ground truth from multi-annotator ordinal data: a probabilistic approach, arXiv: 1305.0015 (2013).
[25] G. Li , J. Wang , Y. Zheng , M.J. Franklin , Crowdsourced data management: a survey, IEEE Trans. Knowl. Data Eng. 28 (9) (2016) 2296–2319 .
[26] G. Little , L.B. Chilton , M. Goldman , R.C. Miller , Turkit: tools for iterative tasks on mechanical turk, in: Proceedings of the ACM SIGKDD Workshop on Human Computation, ACM, 2009, pp. 29–30 .
[27] Q. Liu , J. Peng , A.T. Ihler , Variational inference for crowdsourcing, in: NIPS, Curran Associates, Inc, 2012, pp. 692–700 .
[28] X. Liu , M. Lu , B.C. Ooi , Y. Shen , S. Wu , M. Zhang , CDAS: A crowdsourcing data analytics system, PVLDB 5 (10) (2012) 1040–1051 .
[29] F. Ma , Y. Li , Q. Li , M. Qiu , J. Gao , S. Zhi , L. Su , B. Zhao , H. Ji , J. Han , Faitcrowd: Fine grained truth discovery for crowdsourced data aggregation, in: SIGKDD2015, 2015, pp. 745–754 .
[30] U.V. Marti , H. Bunke , A full english sentence database for off-line handwriting recognition, in: Document Analysis and Recognition, 1999. ICDAR ’99. Proceedings of the Fifth International Conference on, 1999, pp. 705–708 .
[31] U.-V. Marti , H. Bunke ,The iam-database: an english sentence database for offline handwriting recognition, Int. J. Doc. Anal. Recogn. 5 (1) (2002) 39–46 .
[32] V.G. Motti , J. Vanderdonckt , A computational framework for context-aware adaptation of user interfaces, in: IEEE Seventh International Conference on Research Challenges in Information Science, 2013, pp. 1–12 .
[33] Y. Normandin , Maximum Mutual Information Estimation of Hidden Markov Models, Springer US, 1996 .
[34] G. Parent , M. Eskenazi , Toward better crowdsourced transcription: transcription of a year of the let’s go bus information system data, SLT, 2010 .
[35] L.R. Rabiner , A tutorial on hidden markov models and selected applications in speech recognition, Proc. IEEE 77 (2) (1989) 257–286 .
[36] L.R. Rabiner , Readings in Speech Recognition, Morgan Kaufmann Publishers Inc., 1990 .
[37] R.A. Robb , Biomedical Imaging, Visualization, and Analysis, John Wiley & Sons, Inc., 1999 .
[38] M. Salek , Y. Bachrach , P.Key ,Hotspotting–aprobabilisticgraphicalmodelforimageobjectlocalizationthroughcrowdsourcing,AAAI2013,2013 .
[39] W. Shen , J. Han , J. Wang , A probabilistic model for linking named entities in web text with heterogeneous information networks, in: SIGMOD2014, 2014, pp. 1199–1210 .
[40] V.S. Sheng , F. Provost , P.G. Ipeirotis , Get another label? improving data quality and data mining using multiple, noisy labelers, in: SIGKDD2008, ACM, 2008, pp. 614–622 .
[41] A. Sheshadri , M. Lease , Square: a benchmark for research on computing crowd consensus., in: B. Hartman, E. Horvitz (Eds.), HCOMP, AAAI, 2013 .
[42] K. Starbird , Delivering patients to sacrécoeur: collective intelligence in digital volunteer communities, in: CHI2013, ACM, 2013, pp. 801–810 .
[43] L. Tran-Thanh , T.D. Huynh , A. Rosenfeld , S.D. Ramchurn , N.R. Jennings , Crowdsourcing complex workflows under budget constraints, in: AAAI2015, 2015, pp. 1298–1304 .
[44] L. Von Ahn , B. Maurer , C. McMillen , D. Abraham , M. Blum , recaptcha: human-based character recognition via web security measures, Science 321 (5895) (2008) 1465–1468 .
[45] Y. Wang , J. Jiang , T. Mu ,Context-aware and energy-driven route optimization for fully electric vehicles via crowdsourcing, IEEE Trans. Intell. Transp. Syst. 14 (3) (2013) 1331–1345 .
[46] J. Whitehill , P. Ruvolo , T. Wu , J. Bergsma , J. Movellan , Whose vote should count more: optimal integration of labels from labelers of unknown expertise, in: NIPS2009, 2009, pp. 2035–2043 .
[47] O.F. Zaidan , C. Callison-Burch , Crowdsourcing translation: professional quality from non-professionals, in: HLT ’2011, 2011, pp. 1220–1229 .
[48] J. Zhang , V.S. Sheng , Q. Li , J. Wu , X. Wu , Consensus algorithms for biased labeling in crowdsourcing, Inf. Sci. 382383 (2017) 254–273 .
[49] J. Zhang , X. Wu , V.S. Sheng , Learning from crowdsourced labeled data: a survey, Artif. Intell. Rev. 46 (2016) 1–34 .
[50] Y. Zheng , G. Li , R. Cheng , DOCS: domain-aware crowdsourcing system, PVLDB 10 (4) (2016) 361–372 .
[51] Y. Zheng , G. Li , Y. Li , C. Shan , R. Cheng , Truth inference in crowdsourcing: is the problem solved? PVLDB 10 (5) (2017) 541–552 .
[52] Y. Zheng , J. Wang , G. Li , R. Cheng , J. Feng , QASCA: a quality-aware task assignment system for crowdsourcing applications, in: SIGMOD2015, 2015, pp. 1031–1046 .

















 459
459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









