




 本文介绍了一种使用Hadoop处理大数据集的方法,通过将847MB的原始数据分割成多个split,利用MapReduce进行并行处理,实现了高效的数据分析。在Map阶段,使用TreeMap存储每个split中的最大K个数及其出现频率;在Reduce阶段,汇总各中间文件的数据,输出最终的数值及频率。
本文介绍了一种使用Hadoop处理大数据集的方法,通过将847MB的原始数据分割成多个split,利用MapReduce进行并行处理,实现了高效的数据分析。在Map阶段,使用TreeMap存储每个split中的最大K个数及其出现频率;在Reduce阶段,汇总各中间文件的数据,输出最终的数值及频率。
原始数据
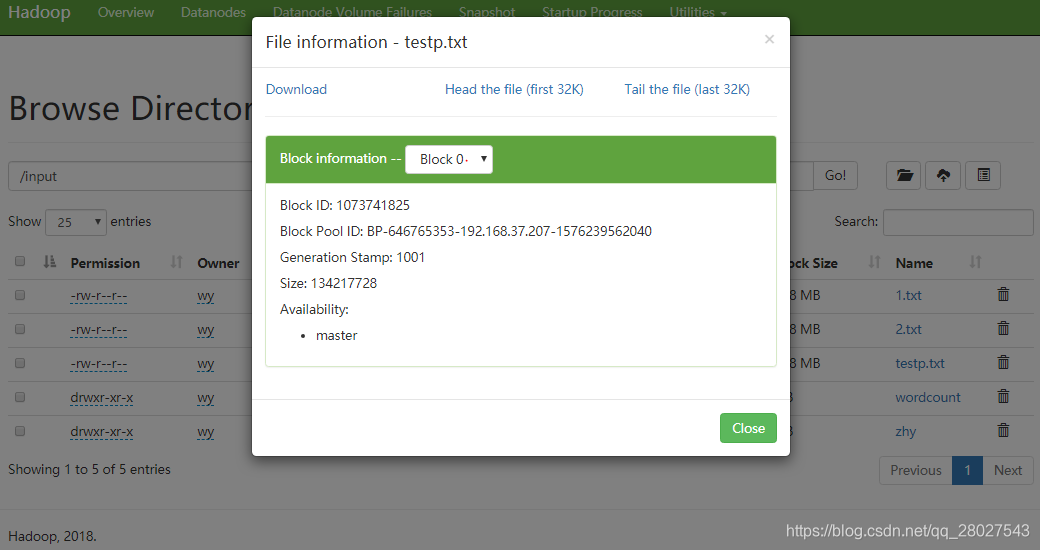
- 分为8个block存储,847 MB
- 数据格式:每个数字是[0,1亿)区域内的随机数(存储的byte长度也不一样,比如:随机数1只用一个byte存储字符1 ; 随机数200 则需要3个字符存储),之间用空格分开。

InputFormat设置
根据数据格式设计分割方式:根据cpu最多并行12线程,应该分割为12个split,开启12个mapTask同时读数据。每条record之间使用空格“ ”f分割。
- 使用 (data Len)/12 的fileSize来切分,设置参数。
private static int mapTaskNum=8;
//设置分割文件大小和分隔符
long splitLen = len / mapTaskNum+1;
conf.set("mapreduce.input.fileinputformat.split.minsize", splitLen+"");
conf.set("textinputformat.record.delimiter", " ");
Map()函数逻辑
- 使用TreeMap数据结构来存储每一个split的最大K个数,和出现的次数,每次添加检测tree数量当超过K个的时候去除最小的值。
- 处理完split时,输出Tree内的值和出现次数到中间文件。
//record不需要分割
Integer integer = Integer.valueOf(line);
if (tree.containsKey(integer)) {
tree.put(integer,tree.get(integer)+1);
}
else {
tree.put(integer,1);
}
if (tree.size() > topK) {
tree.remove(tree.firstKey());
}
@Override
protected void cleanup(Mapper<LongWritable, Text, IntWritable, IntWritable>.Context context)
throws java.io.IOException, InterruptedException {
for(Integer integer:tree.keySet()){
context.write(new IntWritable(integer),new IntWritable(tree.get(integer)));
}
};
Reduce()函数逻辑
- 同样构建TreeMap记录每个中间文件,还要将每个数的出现次数叠加之前的出现次数。
- 输出TreeMap的所有数值和出现次数
@Override
protected void reduce(IntWritable key, java.lang.Iterable<IntWritable> values,Context context)
throws IOException, InterruptedException {
int sum=0;
for(IntWritable value:values){
sum=sum+value.get();
}
tree.put(key.get(),sum);
if (tree.size()>MaxK){
tree.remove(tree.firstKey());
}
}
@Override
protected void cleanup(Reducer<IntWritable, IntWritable, IntWritable, Text>.Context context)
throws java.io.IOException, InterruptedException {
int i=1;
for(Integer integer:tree.descendingKeySet()){
//context.write(new IntWritable(integer),new IntWritable(tree.get(integer)));
//context.write(new IntWritable(integer),new IntWritable(i++));
String s = i+" , count("+tree.get(integer)+")";
context.write(new IntWritable(integer),new Text(s));
i++;
}
};
实际运行情况:
- 分为8个和12个MapTask任务处理:
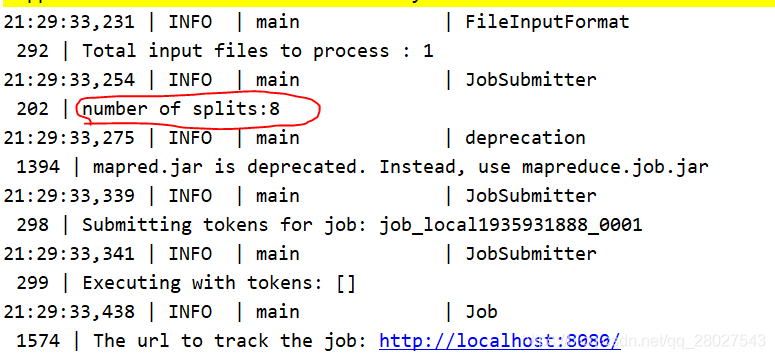
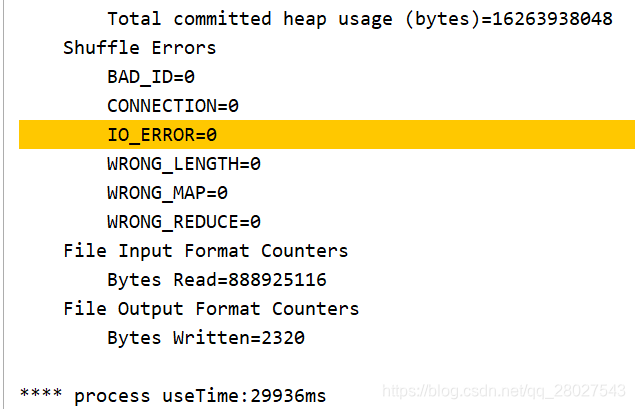
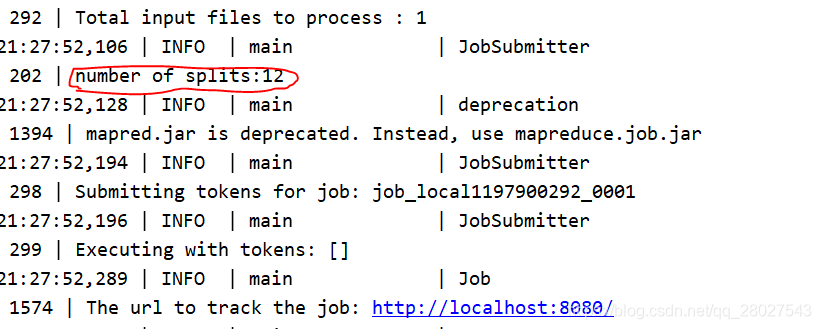
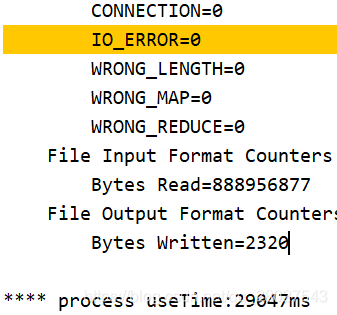
得到的结果完全一致:
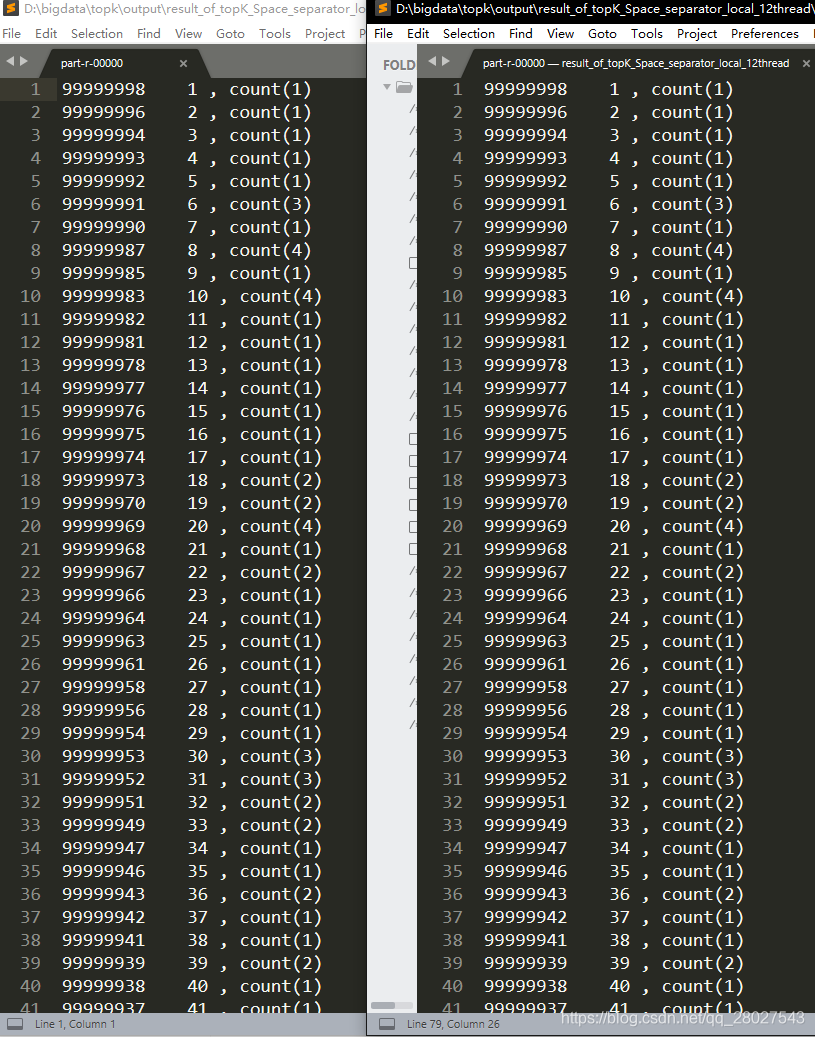

















 3411
3411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









