









 本文记录了一次Redis集群出现故障导致网站无法正常访问的问题,并详细分析了故障原因及解决过程。
本文记录了一次Redis集群出现故障导致网站无法正常访问的问题,并详细分析了故障原因及解决过程。
某天在开启了Redis集群之后,发现网站没法正常访问了,发现Nginx-lua 中的 Redis 丢失连接 …
集群下线
问题表现
通过查看 openrestry log 发现 lua脚本报错 :
2018/06/12 17:48:20 [error] 23272#0: *75665 lua entry thread aborted: runtime error: /usr/local/openresty/nginx/lua/access_by_redis.lua:67: attempt to compare boolean with number
stack traceback:
coroutine 0:
/usr/local/openresty/nginx/lua/access_by_redis.lua: in function </usr/local/openresty/nginx/lua/access_by_redis.lua:1>, client: 66.249.65.116, server: www.leon0204.com, request: "GET /wechat-858.html HTTP/1.1", host: "www.leon0204.com"
从而 Nginx 返回 500,测试 Redis set 发现是集群处于下线状态导致的 :
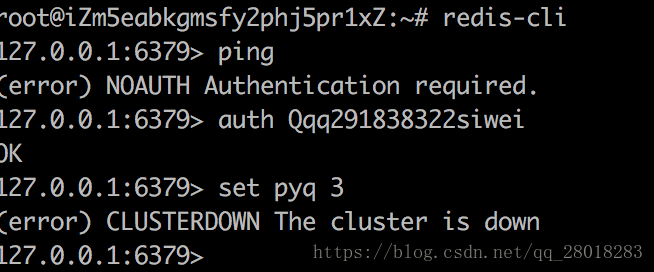
原因分析
那么,这次 redis 集群宕机的原因是什么呢?
-
开启集群
假设A服务器上有127.0.0.1:6379和127.0.0.1:6370两个 Redis 节点。在 节点 6379 的redis.conf中开启cluster-enabled yes,那么节点 6379 就处于一个只包含自己的集群中。 -
构建集群
向127.0.0.1:6379发送命令:
CLUSTER MEET 127.0.0.1:6370
就把 6370 节点 拉到了 6379 所在的集群中。 -
槽指派
Redis集群通过分片的方式来保存数据库的所有键值对:整个数据库被分成16384个 Slot ,数据库键空间的所有键被分配到这16384个槽中的一个,每个node 处理0~16384个槽。当16384个槽有任意1个没有被处理,集群处于fail下线状态,否则处于上线状态。
猜想是有一些槽没有被分配处理,进行分配槽
分配槽
查看集群状态:
127.0.0.1:6379> CLUSTER INFO
cluster_state:fail
cluster_slots_assigned:7
cluster_slots_ok:7
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:1
cluster_size:1
cluster_current_epoch:0
cluster_my_epoch:0
cluster_stats_messages_sent:0
cluster_stats_messages_received:0
可以看到集群是下线状态,有 7 个 Slot 已经被分配,由于有 slots没有分配干净,所以集群处于 fail 下线状态,下面进行分配 slots :
root@iZm5eabkgmsfy2phj5pr1xZ:~# redis-cli -h 127.0.0.1 -p 6379 -a 密码 cluster addslots {0..5000}
(error) ERR Slot `0` is already busy
root@iZm5eabkgmsfy2phj5pr1xZ:~# redis-cli -h 127.0.0.1 -p 6379 -a 密码 cluster addslots 5
OK
...
...
root@iZm5eabkgmsfy2phj5pr1xZ:~# redis-cli -h 127.0.0.1 -p 6379 -a 密码 cluster addslots {8400..12000}
(error) ERR Slot `11955` is already busy
root@iZm5eabkgmsfy2phj5pr1xZ:~# redis-cli -h 127.0.0.1 -p 6379 -a 密码 cluster addslots {8400..11954}
OK
root@iZm5eabkgmsfy2phj5pr1xZ:~# redis-cli -h 127.0.0.1 -p 6379 -a 密码 cluster addslots {13001..16383}
OK
先来看看分配完成集群的状态,和slot_assigned的数目:
127.0.0.1:6379> CLUSTER NODES
151ce5ca0524b02c7af07402dcb40f5d678f7bb1 :6379 myself,master - 0 0 0 connected 0-16383
127.0.0.1:6379> CLUSTER INFO
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:1
cluster_size:1
cluster_current_epoch:0
cluster_my_epoch:0
cluster_stats_messages_sent:0
cluster_stats_messages_received:0
# 可以正确的 set 了
127.0.0.1:6379> set leon leon0204
OK
127.0.0.1:6379>
可以看到此时 slots 已经分配了 16384 个,本机 作为master 集群上线。也可以正常的使用。
slots 分配过程中遇到的断点
可以看到这里不断有一些slots : 1151 1389 1909 5798 6918 8399 11955 显示已经被分配了,这是为什么呢,是不是我把 6379 加入集群之后,已经默认给我分配了这些 槽?所以再我再次分配时,冲突了?
刚刚我分配 0,16383 个槽给 当前node节点时,提示槽X已经busy 的 有
1151 1389 1909 5798 6918 8399 11955
我们知道,当集群被建立之后,集群的整个数据库就会被分配到 16383 个槽中,类似于分片的概念 。那么验证下这些 key 的 slots 节点,就可以验证上面的冲突。
#所有key
127.0.0.1:6379> KEYS *
1) "pyq"
2) "user:183.234.61.216:freq"
3) "leon0204"
4) "name"
5) "funet"
6) "goodsId"
7) "test"
我们查看 这些key 被分配的槽号
127.0.0.1:6379> CLUSTER KEYSLOT "pyq"
(integer) 1151
127.0.0.1:6379> CLUSTER KEYSLOT "user:183.234.61.216:freq"
(integer) 1909
127.0.0.1:6379> CLUSTER KEYSLOT "leon0204"
(integer) 11955
127.0.0.1:6379> CLUSTER KEYSLOT "name"
(integer) 5798
127.0.0.1:6379> CLUSTER KEYSLOT "funet"
(integer) 8399
127.0.0.1:6379> CLUSTER KEYSLOT "goodsId"
(integer) 1389
127.0.0.1:6379> CLUSTER KEYSLOT "test"
(integer) 6918
总结
正好和上面的 addslots 过程中,冲突的 slots 吻合 ,7个key 对应7 个 随机散落的 slot,造成了分配过程中遇到的冲突。
slots没有分配完成,造成了集群的failed ,问题解决。

















 8298
8298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









