




HTTP属于老话题了,在项目中我们经常需要往服务端发POST或者GET请求,但是对于HTTP的了解不应只局限于此。千里之行,始于足下。越想走的远,基本原理就应该了解的透彻全面一些,仅仅停留在使用ASIHttpRequest或者AFNetWorking传个参数发个请求的程度上是不够的。这篇文章就是带你全方面回顾一下HTTP。
通过本文你能收获哪些内容:
-
完整HTTP请求与响应包含的必要元素
-
HTTP不同版本之间的差异
-
HTTP、Socket、TCP的区别(易混)
一、HTTP协议
HTTP本质上是一种协议,全称是Hypertext Transfer Protocol,即超文本传输协议。从名字上可以看出该协议用于规定客户端与服务端之间的传输规则,所传输的内容不局限于文本(其实可以传输任意类型的数据)。

图1.1传输示意图.png
二、HTTP请求与响应的内容
当我们往服务端发送一条HTTP请求时都发送了哪些东西过去呢?
先看一个POST请求的示例图:
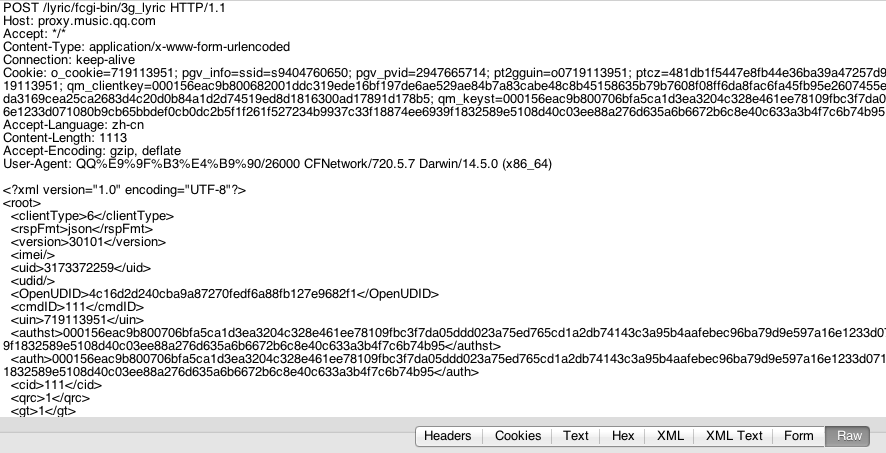
图2.1 HTTP_POST请求示例.png
注:本文使用Paw来模拟发送HTTP请求,使用Charles抓包,Charles选中"Request"以及"Raw"选项就可以看到请求的全部内容
以上示例图中其实已经包含了一个HTTP请求所必备的几大要素:请求行、请求头(headerField)、请求体(body);同理,响应也有状态行、响应头、实体内容。接下来我们逐个展开。
1、请求行
请求行包含请求方法(Method)、请求统一资源标识符(URI)、HTTP版本号,如图2.1第一行所示:
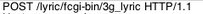
图2.2 请求行.png
-
请求方法就是我们所熟悉的POST、GET、HEAD、PUT等
-
URI就是URL中排除掉Host剩下的部分,也就是资源在服务器本地上的路径
-
HTTP版本号,目前主流的版本是1.1(1999年开始采用),最新的版本是2.0(2015年5月发布)。不同版本之间差异下面会再展开
2、请求头
请求头主要存放对客户端想给服务端的附加信息,下图框框的部分就是请求头:
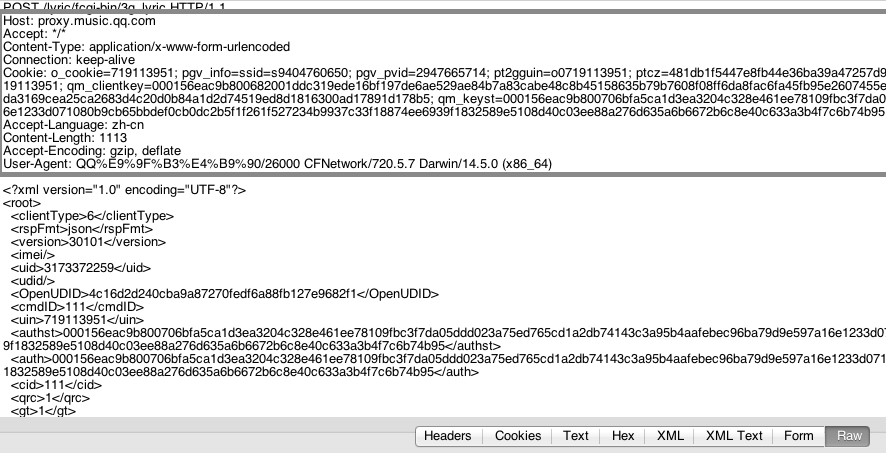
图2.3 请求头.png
HTTP请求在iOS中用NSURLRequest与NSMutableRequest表示;HTTP响应用NSHTTPURLResponse表示。
-
Host: 目标服务器的网络地址
-
Accept: 让服务端知道客户端所能接收的数据类型,如text/html */*
-
Content-Type: body中的数据类型,如application/json; charset=UTF-8,详细看这里
-
Accept-Language: 客户端的语言环境,如zh-cn
-
Accept-Encoding: 客户端支持的数据压缩格式,如gzip
-
User-Agent: 客户端的软件环境,我们可以更改该字段为自己客户端的名字,比如QQ music v1.11,比如浏览器Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/600.8.9 (KHTML, like Gecko) Maxthon/4.5.2
-
Connection: keep-alive,该字段是从HTTP 1.1才开始有的,用来告诉服务端这是一个持久连接,“请服务端不要在发出响应后立即断开TCP连接”。关于该字段的更多解释将在后面的HTTP版本简介中展开。
-
Content-Length: body的长度,如果body为空则该字段值为0。该字段一般在POST请求中才会有。
POST请求的body请求体也有可能是空的,因此POST中Content-Length也有可能为0
-
Cookie: 记录者用户信息的保存在本地的用户数据,如果有会被自动附上
值得一提的是,在iOS中当你发送一个任意请求时,不管你愿不愿意,NSURLRequest都会自动帮你记录你所访问的URL上设置的cookie。在iOS中用NSHTTPCookieStorage表示,是一个单例。通过
|
1
2
3
4
|
NSHTTPCookieStorage *cookieJar = [NSHTTPCookieStorage sharedHTTPCookieStorage];
for
(NSHTTPCookie *cookie
in
[cookieJar cookies]) {
NSLog(@
"%@"
, cookie);
}
|
可以获取目前被自动保存的所有cookie。对cookie的操作感兴趣的请移步iOS中http请求使用cookie这篇文章。
以上就是我们日常开发中比较经常遇到的请求头,其实还有其他的field,但篇幅所限无法一一列出,想了解所有请求头请看这里请求头响应头列表。那在iOS中如何设置添加这些field呢?可以使用-[NSMutableURLRequest addValue: forHTTPHeaderField:]方法,获取当前请求已经设置的field可以用-[NSURLRequest allHTTPHeaderFields]。也就是我们可以通过以上接口定制我们所需要的请求头,但是有些field是不能改的,我们看一下iOS的描述:
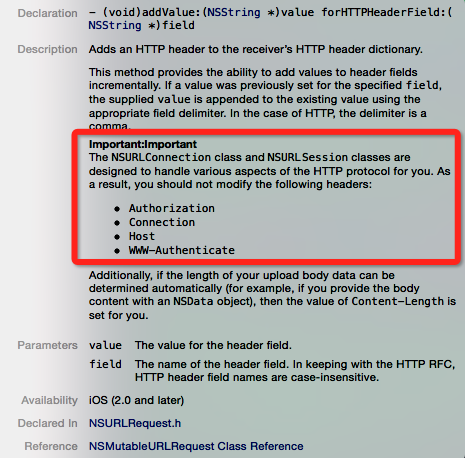
图2.4 iOS请求头接口描述.png
从文档中我们可以看到,在iOS中不应当对Authorization Connection Host WWW-Authenticate这几个header field做更改。
3、请求体
真正需要发给服务端的数据,在使用POST-multipart上传请求中请求体就是上传文件的二进制NSData类型数据;在GET请求中请求体为空;在普通的POST请求中请求体就是一些表单数据。在iOS中一般用NSURLRequest与NSMutableURLRequest的HTTPBody属性表示,添加body用-[NSMutableURLRequest setHTTPBody:]。
4、响应状态行
状态行是服务端返回给客户端的状态信息,包含HTTP版本号、状态码、状态码对应的英文名称。
以下就是典型的正确状态行:
|
1
|
HTTP/1.1 200 OK
|
这个部分需要讲的是错误码。事实上HTTP请求错误码可以根据错误码从左往右第一个数字大致分为以下几类:
1XX:信息提示。不代表成功或者失败,表示临时响应,比如100表示继续,101表示切换协议
2XX: 成功
3XX: 重定向
4XX:客户端错误,很有可能是客户端发生问题,如亲切可爱的404表示未找到文件,说明你的URI是有问题的,服务器机子上该目录是没有该文件的;414URI太长
5XX: 服务器错误,比如504网关超时
错误码是不用去记的,出错了再查对应的错误码含义就行。但是知道上面的分类有助于第一时间做出大体的判断,起码你能清楚是服务端还是客户端的原因。
5、响应头与响应实体
这部分与请求部分差异不大,响应头的字field会有稍许不同,响应头中的header field同样移步请求头响应头列表。
三、HTTP版本简介
这里我把HTTP版本简单分为三类:1.1之前,1.1,2.0,针对这三类做个主要差异的介绍:
HTTP 1.1之前
-
不支持持久连接。一旦服务器对客户端发出响应就立即断开TCP连接
-
无请求头跟响应头
-
客户端的前后请求是同步的。下一个请求必须等上一个请求从服务端拿到响应后才能发出,有点类似多线程的同步机制。
HTTP 1.1(主流版本)
与1.1之前的版本相比,做了以下性能上的提升
-
增加请求头跟响应头
-
支持持久连接。客户端通过请求头中指定Connection为keep-alive告知服务端不要在完成响应后立即释放连接。HTTP是基于TCP的,在HTTP 1.1中一次TCP连接可以处理多次HTTP请求
-
客户端不同请求之间是异步的。下一个请求不必等到上一个请求回来后再发出,而可以连续发出请求,有点类似多线程的异步处理。
HTTP 2.0
本着向下兼容的原则,1.1版本有的特性2.0都具备,也使用相同的API。但是2.0将只用于https网址。由于2.0的普及还需要比较长的一段时间,这里不展开,更多新特性请参考这篇文章。
我们重点关注一下当前1.1版本所做几点改变。支持持久连接有什么好处呢?HTTP是基于TCP连接的,如果连接被频繁地启动然后断开就会花费很多资源在TCP三次握手以及四次挥手上,效率低下。以请求一个网页为例,我们知道,一个html网页上的图片资源并不是直接嵌入在网页上,而只是提供url,图片仍需要额外发HTTP 请求去下载。一个网页从请求到最终加载到本地往往需要经过过个HTTP请求。在1.1版本之前请求一个网页就需要发生多次"握手-挥手"的过程,每次连接之间相互独立;而1.1及之后的版本最少只需要一次就够。
再来就是请求异步,其好处参考多线程异步处理,在此不展开。
以上特性可以用图2.3表示:
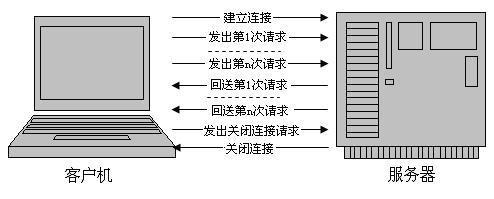
图3.1 异步请求.jpg
我们可以看到:1、N次请求其实只建立了1次TCP连接,2、N次请求连续异步发出。
四、HTTP、Socket、TCP的区别
这三个概念经常被谈到,也是比较容易被混掉的概念。在回顾之前我们先看一下这三者在TCP/IP协议族中的位置关系:
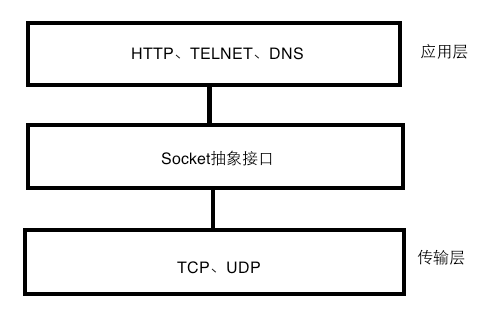
图4.1 层次关系.png
HTTP是应用层的协议,更靠近用户端;TCP是传输层的协议;而socket是从传输层上抽象出来的一个抽象层,本质是接口。所以本质上三种还是很好区分的。尽管如此,有时候你可能会懵逼,HTTP连接、TCP连接、socket连接有什么区别?好吧,如果上面的图解释的还是不够清楚的话,我们继续往下看。
1、TCP连接与HTTP连接的区别
上文提过,HTTP是基于TCP的,客户端往服务端发送一个HTTP请求时第一步就是要建立与服务端的TCP连接,也就是先三次握手,“你好,你好,你好”。从HTTP 1.1开始支持持久连接,也就是一次TCP连接可以发送多次的HTTP请求。
小总结:HTTP基于TCP
1.1:Tcp属于传输层协议,http属于应用层协议。
1.2:HTTP连接中,只有客户端发起请求后服务端才会响应,服务端是无法主动向客户端发消息的。而Socket连接中,通信双方发送消息并没有先后的限制,通信双方中的任何一方可以随时向另一方发送消息。
1.3:http是无状态的,tcp是有状态的,udp也是无状态的。(状态:记录包是否送达的状态)
2、TCP连接与Socket连接的区别
在图4.1中我们提到,socket层只是在TCP/UDP传输层上做的一个抽象接口层,因此一个socket连接可以基于连接,也有可能基于UDP。基于TCP协议的socket连接同样需要通过三次握手建立连接,是可靠的;基于UDP协议的socket连接不需要建立连接的过程,不过对方能不能收到都会发送过去,是不可靠的,大多数的即时通讯IM都是后者。
小总结:Socket也基于TCP
3、HTTP连接与Socket连接的区别
区分这两个概念是比较有意义的,毕竟TCP看不见摸不着,HTTP与Socket是实实在在能用到的。
-
HTTP是1.1之前是短连接,Socket(基于TCP协议的)是长连接。尽管HTTP1.1开始支持持久连接,但仍无法保证始终连接。而Socket连接一旦建立TCP三次握手,除非一方主动断开,否则连接状态一直保持。
-
HTTP连接服务端无法主动发消息,Socket连接双方请求的发送先后限制。这点就比较重要了,因为它将决定二者分别适合应用在什么场景下。HTTP采用“请求-响应”机制,在客户端还没发送消息给服务端前,服务端无法推送消息给客户端。必须满足客户端发送消息在前,服务端回复在后。Socket连接双方类似peer2peer的关系,一方随时可以向另一方喊话。
4、问题来了:什么时候该用HTTP,什么时候该用socket
这个问题的提出是很自然而然的。当你接到一个与另一方的网络通讯需求,自然会考虑用HTTP还是用Socket。
-
用HTTP的情况:双方不需要时刻保持连接在线,比如客户端资源的获取、文件上传等。
-
用Socket的情况:大部分即时通讯应用(QQ、微信)、聊天室、苹果APNs等
在iOS中,发HTTP请求一般用原生的NSURLConnection、NSURLSession或者开源的AFNetWorking(推荐)、ASIHttpRequest(已停止更新)。连接Socket连接我用的比较多是robbiehanson大神的CocoaAsyncSocket(XMPPFramework也是出自他手)。
===========================================================================================
一、什么是长连接
1. HTTP协议与TCP/IP协议的关系
HTTP的长连接和短连接本质上是TCP长连接和短连接。HTTP属于应用层协议,在传输层使用TCP协议,在网络层使用IP协议。 IP协议主要解决网络路由和寻址问题,TCP协议主要解决如何在IP层之上可靠地传递数据包,使得网络上接收端收到发送端所发出的所有包,并且顺序与发送顺序一致。TCP协议是可靠的、面向连接的。
2. 如何理解HTTP协议是无状态的
HTTP协议是无状态的,指的是协议对于事务处理没有记忆能力,服务器不知道客户端是什么状态。也就是说,打开一个服务器上的网页和上一次打开这个服务器上的网页之间没有任何联系。HTTP是一个无状态的面向连接的协议,无状态不代表HTTP不能保持TCP连接,更不能代表HTTP使用的是UDP协议(无连接)。
3. 什么是长连接、短连接?
在HTTP/1.0中默认使用短连接。也就是说,客户端和服务器每进行一次HTTP操作,就建立一次连接,任务结束就中断连接。当客户端浏览器访问的某个HTML或其他类型的Web页中包含有其他的Web资源(如JavaScript文件、图像文件、CSS文件等),每遇到这样一个Web资源,浏览器就会重新建立一个HTTP会话。
而从HTTP/1.1起,默认使用长连接,用以保持连接特性。使用长连接的HTTP协议,会在响应头加入这行代码:
Connection:keep-alive
在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,客户端再次访问这个服务器时,会继续使用这一条已经建立的连接。Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间。实现长连接需要客户端和服务端都支持长连接。
HTTP协议的长连接和短连接,实质上是TCP协议的长连接和短连接。
二、长连接的过期时间
三、长连接的数据传输完成识别
四、并发连接数的数量限制
五、容易混淆的概念——TCP的keep alive和HTTP的Keep-alive
WINHTTP_OPTION_WEB_SOCKET_KEEPALIVE_INTERVAL
Sets the interval, in milliseconds, to send a keep-alive packet over the connection. The default interval is 30000 (30 seconds). The minimum interval is 15000 (15 seconds). Using WinHttpSetOption to set a value lower than 15000 will return with ERROR_INVALID_PARAMETER.
CURLOPT_TCP_KEEPALIVEPass a long. If set to 1, TCP keepalive probes will be sent. The delay and frequency of these probes can be controlled by the CURLOPT_TCP_KEEPIDLE and CURLOPT_TCP_KEEPINTVL options, provided the operating system supports them. Set to 0 (default behavior) to disable keepalive probes (Added in 7.25.0).CURLOPT_TCP_KEEPIDLEPass a long. Sets the delay, in seconds, that the operating system will wait while the connection is idle before sending keepalive probes. Not all operating systems support this option. (Added in 7.25.0)CURLOPT_TCP_KEEPINTVLPass a long. Sets the interval, in seconds, that the operating system will wait between sending keepalive probes. Not all operating systems support this option. (Added in 7.25.0)

六、HTTP 流水线技术
七、学习资料
=========================================================================================
http的KeepAlive详解
KeepAlive既熟悉又陌生,踩过坑的同学都知道痛。一线运维工程师踩坑之后对于KeepAlive的总结,你不应该错过!
最近工作中遇到一个问题,想把它记录下来,场景是这样的:
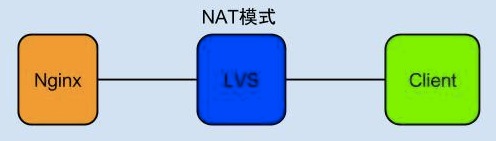
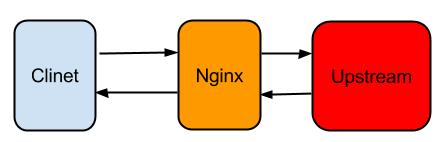
从上图可以看出,用户通过Client访问的是LVS的VIP, VIP后端挂载的RealServer是Nginx服务器。 Client可以是浏览器也可以是一个客户端程序。一般情况下,这种架构不会出现问题,但是如果Client端把请求发送给Nginx,Nginx的后端需要一段时间才能返回结果,超过1分30秒就会有问题,使用LVS作为负载均衡设备看到的现象就是1分30秒之后, Client和Nginx链接被断开,没有数据返回。
原因是LVS默认保持TCP的Session为90s,超过90s没有TCP报文在链接上传输,LVS就会给两端发送RESET报文断开链接。LVS这么做的原因相信大家都知道一二,我所知道的原因主要有两点:
1. 节省负载均衡设备资源,每一个TCP/UDP的链接都会在负载均衡设备上创建一个Session的结构, 链接如果一直不断开,这种Session结构信息最终会消耗掉所有的资源,所以必须释放掉。
2.另外释放掉能保护后端的资源,如果攻击者通过空链接,链接到Nginx上,如果Nginx没有做合适 的保护,Nginx会因为链接数过多而无法提供服务。
这种问题不只是在LVS上有,之前在商用负载均衡设备F5上遇到过同样的问题,F5的session断开方式和LVS有点区别,F5不会主动发送RESET给链接的两端,session消失之后,当链接中一方再次发送报文时会接收到F5的RESET, 之后的现象是再次发送报文的一端TCP链接状态已经断开,而另外一端却还是ESTABLISH状态。
知道是负载均衡设备原因之后,第一反应就是通过开启KeepAlive来解决。到此这个问题应该是结束了,但是我发现过一段时间总又有人提起KeepAlive的问题,甚至发现由于KeepAlive的理解不正确浪费了很多资源,原本能使用LVS的应用放在了公网下沉区,或者换成了商用F5设备(F5设备的Session断开时间要长一点,默认应该是5分钟)。
所以我决定把我知道的KeepAlive知识点写篇博客分享出来。
为什么要有KeepAlive?
在谈KeepAlive之前,我们先来了解下简单TCP知识(知识很简单,高手直接忽略)。首先要明确的是在TCP层是没有“请求”一说的,经常听到在TCP层发送一个请求,这种说法是错误的。
TCP是一种通信的方式,“请求”一词是事务上的概念,HTTP协议是一种事务协议,如果说发送一个HTTP请求,这种说法就没有问题。也经常听到面试官反馈有些面试运维的同学,基本的TCP三次握手的概念不清楚,面试官问TCP是如何建立链接,面试者上来就说,假如我是客户端我发送一个请求给服务端,服务端发送一个请求给我。。。
这种一听就知道对TCP基本概念不清楚。下面是我通过wireshark抓取的一个TCP建立握手的过程。(命令行基本上用TCPdump,后面我们还会用这张图说明问题):

现在我看只要看前3行,这就是TCP三次握手的完整建立过程,第一个报文SYN从发起方发出,第二个报文SYN,ACK是从被连接方发出,第三个报文ACK确认对方的SYN,ACK已经收到,如下图:
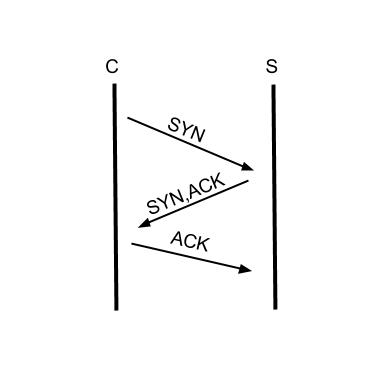
但是数据实际上并没有传输,请求是有数据的,第四个报文才是数据传输开始的过程,细心的读者应该能够发现wireshark把第四个报文解析成HTTP协议,HTTP协议的GET方法和URI也解析出来,所以说TCP层是没有请求的概念,HTTP协议是事务性协议才有请求的概念,TCP报文承载HTTP协议的请求(Request)和响应(Response)。
现在才是开始说明为什么要有KeepAlive。链接建立之后,如果应用程序或者上层协议一直不发送数据,或者隔很长时间才发送一次数据,当链接很久没有数据报文传输时如何去确定对方还在线,到底是掉线了还是确实没有数据传输,链接还需不需要保持,这种情况在TCP协议设计中是需要考虑到的。
TCP协议通过一种巧妙的方式去解决这个问题,当超过一段时间之后,TCP自动发送一个数据为空的报文给对方,如果对方回应了这个报文,说明对方还在线,链接可以继续保持,如果对方没有报文返回,并且重试了多次之后则认为链接丢失,没有必要保持链接。
如何开启KeepAlive?
KeepAlive并不是默认开启的,在Linux系统上没有一个全局的选项去开启TCP的KeepAlive。需要开启KeepAlive的应用必须在TCP的socket中单独开启。Linux Kernel有三个选项影响到KeepAlive的行为:
1.net.ipv4.tcpkeepaliveintvl = 75
2.net.ipv4.tcpkeepaliveprobes = 9
3.net.ipv4.tcpkeepalivetime = 7200
tcpkeepalivetime的单位是秒,表示TCP链接在多少秒之后没有数据报文传输启动探测报文; tcpkeepaliveintvl单位是也秒,表示前一个探测报文和后一个探测报文之间的时间间隔,tcpkeepaliveprobes表示探测的次数。
TCP socket也有三个选项和内核对应,通过setsockopt系统调用针对单独的socket进行设置:
TCPKEEPCNT: 覆盖 tcpkeepaliveprobes
TCPKEEPIDLE: 覆盖 tcpkeepalivetime
TCPKEEPINTVL: 覆盖 tcpkeepalive_intvl
举个例子,以我的系统默认设置为例,kernel默认设置的tcpkeepalivetime是7200s, 如果我在应用程序中针对socket开启了KeepAlive,然后设置的TCP_KEEPIDLE为60,那么TCP协议栈在发现TCP链接空闲了60s没有数据传输的时候就会发送第一个探测报文。
TCP KeepAlive和HTTP的Keep-Alive是一样的吗?
估计很多人乍看下这个问题才发现其实经常说的KeepAlive不是这么回事,实际上在没有特指是TCP还是HTTP层的KeepAlive,不能混为一谈。TCP的KeepAlive和HTTP的Keep-Alive是完全不同的概念。
TCP层的KeepAlive上面已经解释过了。 HTTP层的Keep-Alive是什么概念呢? 在讲述TCP链接建立的时候,我画了一张三次握手的示意图,TCP在建立链接之后, HTTP协议使用TCP传输HTTP协议的请求(Request)和响应(Response)数据,一次完整的HTTP事务如下图:
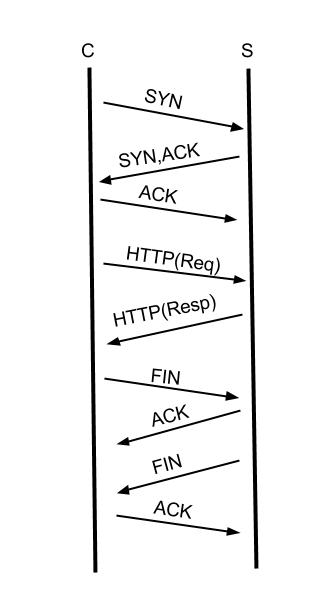
各位看官请注意,这张图我简化了HTTP(Req)和HTTP(Resp),实际上的请求和响应需要多个TCP报文。
从图中可以发现一个完整的HTTP事务,有链接的建立,请求的发送,响应接收,断开链接这四个过程,早期通过HTTP协议传输的数据以文本为主,一个请求可能就把所有要返回的数据取到,但是,现在要展现一张完整的页面需要很多个请求才能完成,如图片,JS,CSS等,如果每一个HTTP请求都需要新建并断开一个TCP,这个开销是完全没有必要的。
开启HTTP Keep-Alive之后,能复用已有的TCP链接,当前一个请求已经响应完毕,服务器端没有立即关闭TCP链接,而是等待一段时间接收浏览器端可能发送过来的第二个请求,通常浏览器在第一个请求返回之后会立即发送第二个请求,如果某一时刻只能有一个链接,同一个TCP链接处理的请求越多,开启KeepAlive能节省的TCP建立和关闭的消耗就越多。
当然通常会启用多个链接去从服务器器上请求资源,但是开启了Keep-Alive之后,仍然能加快资源的加载速度。HTTP/1.1之后默认开启Keep-Alive, 在HTTP的头域中增加Connection选项。当设置为Connection:keep-alive表示开启,设置为Connection:close表示关闭。实际上HTTP的KeepAlive写法是Keep-Alive,跟TCP的KeepAlive写法上也有不同。所以TCP KeepAlive和HTTP的Keep-Alive不是同一回事情。
Nginx的TCP KeepAlive如何设置?
开篇提到我最近遇到的问题,Client发送一个请求到Nginx服务端,服务端需要经过一段时间的计算才会返回, 时间超过了LVS Session保持的90s,在服务端使用Tcpdump抓包,本地通过wireshark分析显示的结果如第二副图所示,第5条报文和最后一条报文之间的时间戳大概差了90s。
在确定是LVS的Session保持时间到期的问题之后,我开始在寻找Nginx的TCP KeepAlive如何设置,最先找到的选项是keepalivetimeout,从同事那里得知keepalivetimeout的用法是当keepalivetimeout的值为0时表示关闭keepalive,当keepalivetimeout的值为一个正整数值时表示链接保持多少秒,于是把keepalivetimeout设置成75s,但是实际的测试结果表明并不生效。
显然keepalivetimeout不能解决TCP层面的KeepAlive问题,实际上Nginx涉及到keepalive的选项还不少,Nginx通常的使用方式如下:
从TCP层面Nginx不仅要和Client关心KeepAlive,而且还要和Upstream关心KeepAlive, 同时从HTTP协议层面,Nginx需要和Client关心Keep-Alive,如果Upstream使用的HTTP协议,还要关心和Upstream的Keep-Alive,总而言之,还比较复杂。
所以搞清楚TCP层的KeepAlive和HTTP的Keep-Alive之后,就不会对于Nginx的KeepAlive设置错。我当时解决这个问题时候不确定Nginx有配置TCP keepAlive的选项,于是我打开Ngnix的源代码,在源代码里面搜索TCP_KEEPIDLE,相关的代码如下:
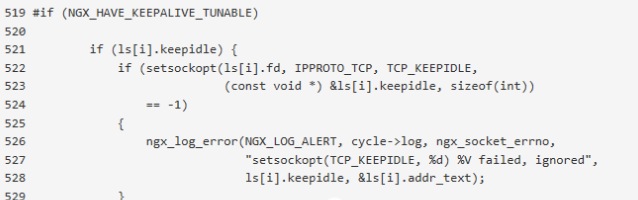
从代码的上下文我发现TCP KeepAlive可以配置,所以我接着查找通过哪个选项配置,最后发现listen指令的so_keepalive选项能对TCP socket进行KeepAlive的配置。

以上三个参数只能使用一个,不能同时使用, 比如sokeepalive=on, sokeepalive=off或者sokeepalive=30s::(表示等待30s没有数据报文发送探测报文)。通过设置listen 80,sokeepalive=60s::之后成功解决Nginx在LVS保持长链接的问题,避免了使用其他高成本的方案。在商用负载设备上如果遇到类似的问题同样也可以通过这种方式解决。
原文链接https://blog.youkuaiyun.com/zlxfogger/article/details/44919995

















 5115
5115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









