







 本文介绍了一种基于模型的方法,用于研究大脑听觉皮层如何处理自然音乐中的音调。通过对真实生活声音的fMRI响应进行编码和解码,发现位于颞横回附近的区域对外界声音的音调高度和显著性特别敏感。
本文介绍了一种基于模型的方法,用于研究大脑听觉皮层如何处理自然音乐中的音调。通过对真实生活声音的fMRI响应进行编码和解码,发现位于颞横回附近的区域对外界声音的音调高度和显著性特别敏感。
Study notes on
Cortical processing of pitch: Model-based encoding and decoding of auditory fMRI responses to real-life sounds
Abstract:
音调是一个与声音基频(或者说周期)相关的属性。已经有研究是针对大脑的听觉皮层对合成音乐的音调的处理或者说编解码,但是对自然音乐的音调的研究很少。自然音乐里有复杂谐波成分(信号的频率成分包含有基频及基频的整数倍),大脑对它的加工与对合成音乐加工的机制可能不同。这篇文章首先用一种经典的音高估计算法YIN实现对音乐中音高的估计。接下来,用基于模型的编解码预测fmri并重新解码出音高特征,从而来研究人类听觉皮层对音调的编解码过程。具体来说,将人类对声音的响应函数,建模为"Pitch Height and salience"函数,人类感知音调的height与基频有关,而感知salience则和谐波结构有关。用单体素fmri编码模型找到编码音高的区域(pitch ROI):前外侧颞横回,近邻STG。解码模型也验证了这一区域的多体素解码模型蕴含音高的更多信息。进一步的多变量分析(multivariate analyses)展示了,补充一个多分辨率的频谱图,能对解码效果产生一个小而显著的提升。
总的来说,本文提出了一种基于模型的fmri编解码方法,这种方法以前常被用于测试人类听觉系统中对音乐特征的表示与处理,在本文被拓展到一个感知的属性——音高的表示与处理上。该模型的结果指出外HG、STG区提取和处理了复杂的自然声音中的音高信息,这与过去用合成音乐产生fmri的研究结果一致。在这些区域,与认知相关的音乐表示反映了音高感知中的height和salience的调制结合(modulatory combination??)。
salience: 可以理解为人耳听到一个由多种音调组成的和弦音,某种音调的声音与其他音调相比的显著性, stemming from wiki:pitch salience is the prominence of a given pitch sensation. For example, the root of a major chord in root position has greater pitch salience than other tones in that chord.
multivariate analyses: Multivariate analysis (MVA) is based on the statistical principle of multivariate statistics, which involves observation and analysis of more than one statistical outcome variable at a time.
频谱图:spectro-temporal,应该是对音频信号进行分帧,每帧做FFT得到每一帧的频谱图,连起来构成整个信号的频谱图。横轴时间(帧数),纵轴是频率的若干个分辨率,每个小格子被灰度化。具体操作过程见图1,来自博客。

图1
Introduction部分:
对和声来说,pitch是对基频的感知。如果基频的能量被移除,人仍能产生同样感知,因为pitch由声音的时间包络线周期决定,而不是由能量决定。
音高感知的神经机制:
- 时间的假设:听觉神经通过脉冲序列的间隔时间来编码声音中的周期信息。
- place theory 推测pitch是被harmonic template决定的,这个harmonic template与耳蜗中按位编码(encoded tonotopically)的频谱线索(spectral cue)最匹配。??
- 最近的研究表明时间和定位都对pitch的准确感知重要。
人脑对合成的声音和自然生活中真实存在的声音的感知是不同的。
感知合成声音的脑区的定位
大脑皮层对音调的处理可以通过fmri反映出来。大脑皮层后HG区和PT双侧在处理时变的音调序列和时不变的音调序列时有着激活模式的差异。
音调处理过程的层次性:起始于皮层下结构,对音调的时间线上的规律性最敏感;终于皮层,对音调的变动敏感,从而更多地编码音调变化的信息。
猿猴的音高选择性神经元,分布在初级听觉皮层的前外侧边界旁边的低频区域,对应于人类的颞横回。
在颞横回前外侧双侧的神经活动体现着与音高显著性的共变。
不同研究间存在争议!
感知自然声音
自然声音是更加复杂的,why?自然的声音的音高受到各种因素的影响。音高显著性(也就是音高在人类感知时的强度)受到声音中谐波成分多少的影响。谐波成分多,显著性高。自然声音大多都不是谐波。因此表征自然声音的音高,需要将基频和谐波结构两个维度剥离成height和salience。音调被人类感知分为感知其height和感知其salience。
数据采集
两个实验,实验1:5被试,平均32岁,3男;实验2:5被试,平均27岁,2男。
自然声音包括语音,歌声,动物叫喊,自然场景,乐器,工具声。实验1有168条声音,实验2有288条。音频采样频率16k,1s长。
TA: TA is the time between the first and the last slice within one scan.
TR: The basic time resolution parameter (sampling time) is designated TR; the TR dictates how often a particular brain slice is excited and allowed to lose its magnetization.
TE: The echo time (TE) represents the time from the center of the RF-pulse to the center of the echo.
4种声音表示模型
- pitch model
感知到的音高只是音调的height - weighted pitch model
感知到的音高是height和salience的加权 - tonotopy model
频谱能量图 - timbral brightness model
频谱的质心的高度,与音色的亮度有关
前两种模型中都需要用到基频估计(fundamental frequency estimation)算法,经典的算法是
YIN算法,通过自相关分析估计出基频。
与这一算法相关的一个称之为difference function的公式:
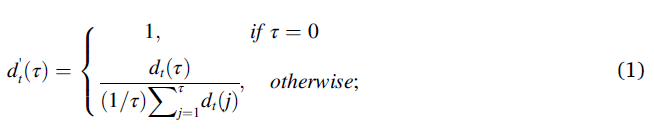
后面会再次提到它。
pitch model在估计出的基频上做了一些处理↓(没有看懂),总之再在时域求平均,得到声音的表示。

而weighted pitch模型则通过公式(1)里的函数,计算出一个反应音高显著性的数值,数值越小表示显著性越差。最后将F0 contour与表示显著性的数值点乘,再在时域求平均得到weighted pitch模型的声音表示。
模型1和2的区别在于后者基于“刺激的谐波结构信息对与音高感知有关的fmri活动有贡献”的假设。
又提出saliency model和saliency-pitch model做对照,让实验更严谨。前者是weighted pitch的特征维度做平均,所以是1维的特征。后者是salience和height的直接组合,所以是128+1=129维的特征。
模型3:
对声音做分帧和短时傅里叶变换STFT,得到的频谱图在频率轴降采样(50-8000Hz取对数,128个区间),时域求平均。
模型4:
计算每个时刻,频谱的质心
S
C
(
t
)
SC(t)
SC(t), 具体过程:
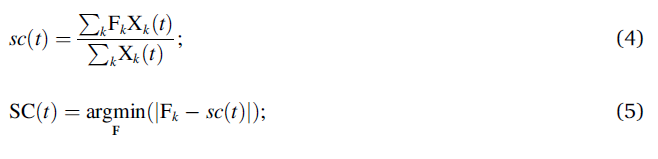
X
k
X_k
Xk是每个谐波的幅值,
F
k
F_k
Fk是每个谐波对应的频率,最后将
S
C
(
t
)
SC(t)
SC(t)在时域求平均。
用一幅图总结四种模型的区别:

单体素编码模型
前面的四个模型都是为了完成从输入的声音信号
X
X
X中提取特征
F
S
F_{S}
FS,
S
S
S表示声音的数量。
y
i
=
[
y
1
i
,
y
2
i
,
⋯
 
,
y
S
i
]
T
y_i=[y_{1i},y_{2i},\cdots,y_{Si}]^T
yi=[y1i,y2i,⋯,ySi]T表示第i个体素对S个声音做出的反应。
对训练集中的数据,
y
S
t
r
a
i
n
,
i
y_{S_{train},i}
yStrain,i通过一个线性映射来计算:
y
S
t
r
a
i
n
,
i
=
F
S
t
r
a
i
n
w
i
+
n
i
y_{S_{train},i}=F_{S_{train}}w_i+n_i
yStrain,i=FStrainwi+ni
权重
w
i
w_i
wi通过岭回归算法来估计,正则项通过交叉验证来决定。测试集,通过公式
y
S
t
e
s
t
,
i
=
F
S
t
e
s
t
w
i
y_{S_{test},i}=F_{S_{test}}w_i
yStest,i=FStestwi预测体素i的反应。
这个过程中,不同刺激下的训练集体素反应要规范化为0均值,单位方差。用训练集的方差和均值对测试集也规范化。
如何评判预测质量?
通过voxel-wise的pearson相关系数的计算。模型间差异性检验,通过一系列检验方法,没怎么看懂,大概应该有涉及符号检验的知识。
Pitch ROI的自定义和多体素解码模型
pitch ROI
不同个体有不同的pitch ROI,它的提出是为了证明被试间结果的一致性。利用训练数据,找出模型拟合有效性最高的那个区域,作为pitch ROI。有效性通过置换检验计算。
多体素解码模型
在pitch ROI上进行从fmri响应到音乐特征的重建。公式:
f
S
t
r
a
i
n
,
k
=
Y
S
t
r
a
i
n
w
k
T
+
b
k
1
+
n
k
f_{S_train,k}=Y_{S_{train}}w_k^T+b_k 1+n_k
fStrain,k=YStrainwkT+bk1+nk
其中
w
k
=
[
w
k
1
,
⋯
 
,
w
k
I
]
w_k=[w_{k1},\cdots,w_{kI}]
wk=[wk1,⋯,wkI]用岭回归估计,正则项用交叉验证决定. k:特征的第k维。I:体素个数。
测试集
f
S
t
e
s
t
,
k
=
Y
S
t
e
s
t
w
k
T
f_{S_{test},k}=Y_{S_{test}}w_k^T
fStest,k=YStestwkT
如何评价解码质量?
对每个声音
s
s
s,计算重构出的特征和原始特征间的pearson相关系数
r
s
r_s
rs.
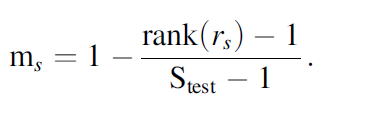
每个被试的最终识别准确率,用
m
s
m_s
ms在不同声音上求平均来获得。??
最后会用t检验来比较Pitch ROI上和互补Pitch ROI上的识别准确率的差异。
音高-谱时调制相结合来进行多体素解码
过去的研究表明,通过基于谱时调制(spectro-temporal modulation)的声音表示模型能够对自然声音的fmri响应进行准确的预测。本文就想设计实验,来探索跟谱时调制相比,前文提出的weighted pitch 模型对解码效果的贡献有多大。
谱时调制 spectro-temporal modulation:
声谱,是一个幅值在时域上变化的信号。频谱,是一个幅值在频域上变化的信号。而频谱图(spectrogram),是频谱+时间线,就是幅值在频域和时域上的变化。所以,针对频谱图的调制,可以有频域和时域两个参数。是2D的滤波器,其中的spectral modulation 通常用 Ω \Omega Ω表示,单位是cyc/oct, temporal modulation 用 ω \omega ω表示,单位Hz。
文章中用的谱时调制,
Ω
=
[
0.5
,
1
,
2
,
4
]
c
y
c
/
o
c
t
\Omega = [0.5, 1, 2, 4] cyc/oct
Ω=[0.5,1,2,4]cyc/oct,
ω
=
[
1
,
3
,
9
,
27
]
H
z
\omega = [1, 3, 9, 27]Hz
ω=[1,3,9,27]Hz.这样可以得到16维的特征。为了与weighted pitch 模型解码的效果(模型提出的特征是128维的)作比较,频谱图里的num of frequency bins设置成8(详细过程参见该论文)
接下来用谱时调制计算出的特征来进行多体素解码,再用weighted pitch 和 谱时调制得到的关联系数做平均,将这两个结果均与weighted pitch 结果对比,t检验来证明是否有差异。
Results
体素预测准度和模型间对比
体素预测准度:weighted pitch model 最高
weighted pitch > pitch > tonotopy model > timbral brightness model
saliency-pitch model > saliency model
分布:weighted pitch, pitch, saliency-pitch model 都比较像
tonotopy model, timbral brightness model比较像
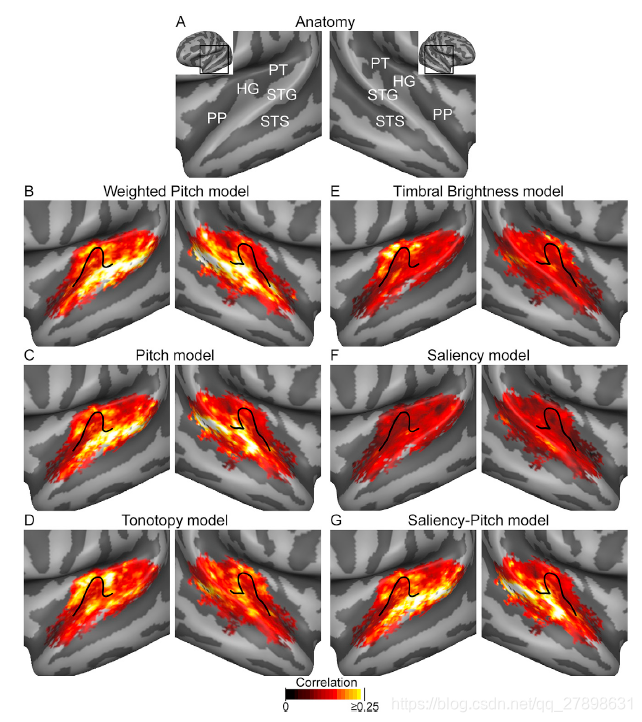
Group-level statistical non-parametric maps comparing the weighted pitch to the competing model:
也就是最优模型与其他模型的对比图,通过对比,可以看到哪些区域weighted pitch表现出了更优的结果。

与pitch、saliency-pitch模型比,weighted pitch在右脑middle STG和posterior STG有差异
与tonotopy和timbral brightness比,weighted pitch在左右脑的lateral HG和adjacent STG有差异
和saliency比,weighted pitch在middle and posterios STG, HG有差异
证明这些也是weighted-pitch表现突出的重要区域。
Pitch ROI的特性
pitch ROI的特性通过下面四幅图体现出来。
图A表明每个被试的pitch ROI存在重合区域(lateral HG and middle STG bilaterally)
图B表明重合区域与高预测率区域一致
图C:用tonotopy model估计的体素的特征频率拓扑图(CF),根据图B,模型在对低频率敏感的体素上重建的效果更好。与过往研究(猿猴的音调敏感神经元多数分布在初级视觉皮层和lateral belt的低频区域)的结果一致。
图D:maps of characteristic spectral modulations (CSM)。过去的研究表明高光谱刻度(?)上的能量分布携带了很多音高信息,然而图D的结果,pitch ROI上的大多数体素都是比较低的光谱调制值,这说明Pitch ROI编码了一种不一样的音高特征。

多体素解码
对多体素解码任务,
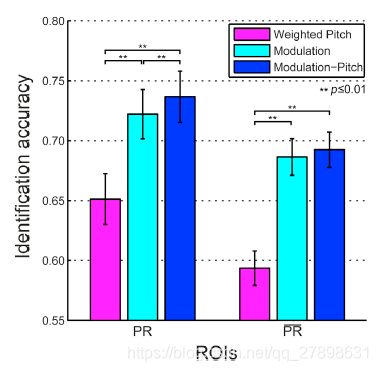
无论是在pitch ROI还是其补集上,谱时调制都比weighted pitch有显著优势。
下图:在pitch ROI或者其补集上,weighted pitch 、谱时调制、两者结合,三种情况下的识别准确率
Discussion
- weighted pitch模型的提出,而且是用real-life sounds做刺激信号
- Pitch ROI的探索:lateral HG, adjacent middle-posterior STG
- weighted pitch是saliency 和height特征的结合,这意味着:Pitch ROI中的神经元群的活动,不仅反映声音的能量,还表征着音调的信息。
- timbral brightness模型表现较差,可能反映了这样的事实:听觉皮层的反映编码时域的变化,而不是音调的spectral centroid的长期统计数据。
- weighted pitch模型比较接近于皮层对自然声音的音调的感知。
- 提取音调特征的算法用了YIN算法,原因:该算法对基频和非周期的谐波有着鲁棒的估计。
- 谱时调制与pitch的结合取得了最好的识别结果,印证了一个假设:听觉系统同时利用声音的音调和多分辨率表示来解析复杂场景的听觉对象。(听觉场景分析相关)
Summary
原文可借鉴的地方:
1.一些重要的神经科学的结论
比如哪些脑区对音调编码贡献最大:lateral HG, adjacent middle-posterior STG。那么在后续我们的工作中,就可以对这些脑区的体素或者导联(EEG,不过空间分辨率过低,实现起来可能效果不好)赋较高的权重。
还有透过weighted pitch模型,可知大脑感知pitch时同时感知了声音的saliency显著性和height音高的特征。然而大脑真正的编码过程可能比weighted pitch模型要负责更多。
2.从声音提取音调特征的算法
YIN算法是一个经典的时域上的基音检测的算法。除此之外,也有许多其他基音检测算法如:频域上HPS(harmonic product spectrum),频谱法等值得尝试并作对比。
3.音调特征编解码算法
采用的基于单体素编码,多体素解码的方法,而且用的岭回归算法求权重。
可以改进的地方:
音调特征编解码算法可以用深度神经网络的方法,由于网络深度的加深,或许可以对体素进行更好的预测。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









