







 本文详细介绍了R-CNN目标检测算法的工作原理,包括Selective Search提出的物体建议候选框,CNN特征提取,SVM分类,IOU评估,非极大值抑制(NMS)以及bounding-box回归等关键步骤。此外,讨论了训练策略,如SVM代替Softmax层,以及预训练迁移学习在防止过拟合中的应用。
本文详细介绍了R-CNN目标检测算法的工作原理,包括Selective Search提出的物体建议候选框,CNN特征提取,SVM分类,IOU评估,非极大值抑制(NMS)以及bounding-box回归等关键步骤。此外,讨论了训练策略,如SVM代替Softmax层,以及预训练迁移学习在防止过拟合中的应用。
一、文章概述
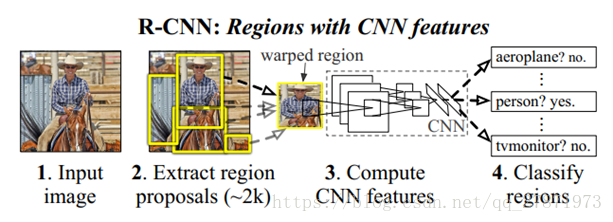
文章思路:对于输入的图片,首先使用Selective Search给出2000个物体建议候选框(Region Proposal),然后使用CNN提取每个Region Proposal中图片的特征向量,采用多个SVM分类器对各个候选框中的物体进行分类(compute score),得到的是一个region-bounding-box及对应的类别,再利用IOU得到具体的框,为了精确bounding-box,再根据pool5 feature做了个bounding-box 回归来提高定位精度。
二、 训练中涉及的主要技巧
- IOU的理解
在目标检测领域,我们使用检测算法对物体进行定位并识别,因为检测算法很难和人工标注的数据完全匹配,就需要一个评价定位精度的指标:IOU。IOU定义了两个bounding box的重叠程度,如下图所示:
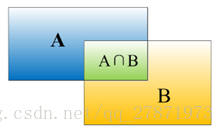
矩形框A、B的一个重合度IOU计算公式为:IOU=(A∩B)/(A∪B)

物体检测需要定位出物体的bounding box,对于上面的图像,我们不仅要给出狗的bounding box ,还要识别出bounding box 里面的物体是狗。假设红色框A是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









