






 本文详细介绍TensorFlow中数据处理的核心机制,从Dataset到Iterator的四步走过程,包括数据的读取、转换、批处理和迭代访问。适用于非Eager模式和Eager模式,涵盖数据预处理、批处理、重复、混洗等关键操作。
本文详细介绍TensorFlow中数据处理的核心机制,从Dataset到Iterator的四步走过程,包括数据的读取、转换、批处理和迭代访问。适用于非Eager模式和Eager模式,涵盖数据预处理、批处理、重复、混洗等关键操作。


前言:在tensorflow中,训练数据常常需要经过随机打乱、分成一个一个的batch来进行训练,当然有很多的方式可以完成,比如我们可以通过传统的python方法构建迭代器,我们也可以使用其它的一些方法,但是tensorflow本身提供了强大的data pipeline处理机制,本文就来详细说明一下。本文的核心是:从Dataset到Iterator的“四步走”过程。
我们知道,在TensorFlow中可以使用feed-dict的方式输入数据信息,但是这种方法的速度是最慢的,在实际应用中应该尽量避免这种方法。而使用输入管道就可以保证GPU在工作时无需等待新的数据输入,这才是正确的方法
一、tf.data包概述
1.1 Dataset API的导入
1.2 基本概念:Dataset与Iterator
1.3 元素(element)与组件(component)
1.4 Iterator类
二、Dataset类的详解
2.1 Dataset类的属性
2.2 Dataset类的方法
(1)dataset.batch()方法
(2)dataset.repeat()函数
(3)dataset.shuffle()函数
2.3 Dataset类的两个高级方法
(1)dataset.map()方法
一、tf.data包概述
Dataset API是TensorFlow 1.3版本中引入的一个新的模块,主要服务于数据读取,构建输入数据的pipeline。
此前,在TensorFlow中读取数据一般有两种方法:
- 使用placeholder读内存中的数据
- 使用queue读硬盘中的数据(关于这种方式,可以参考我之前的一篇文章:十图详解tensorflow数据读取机制)
在tensorflow1.4版本之后,出现了标准的Dataset API,使用它来完成可以更加高效。Dataset API同时支持从内存和硬盘的读取,相比之前的两种方法在语法上更加简洁易懂。此外,如果想要用到TensorFlow新出的Eager模式,就必须要使用Dataset API来读取数据。
本文就来为大家详细地介绍一下Dataset API的使用方法(包括在非Eager模式和Eager模式下两种情况)。
1.1 Dataset API的导入
在TensorFlow 1.3中,Dataset API是放在contrib包中的:
tf.contrib.data.Dataset而在TensorFlow 1.4中,Dataset API已经从contrib包中移除,变成了核心API的一员:
tf.data.Dataset下面的示例代码将以TensorFlow 1.4版本为例,如果使用TensorFlow 1.3的话,需要进行简单的修改(即加上contrib)。
1.2 基本概念:Dataset与Iterator
让我们从基础的类来了解Dataset API。参考Google官方给出的Dataset API中的类图:
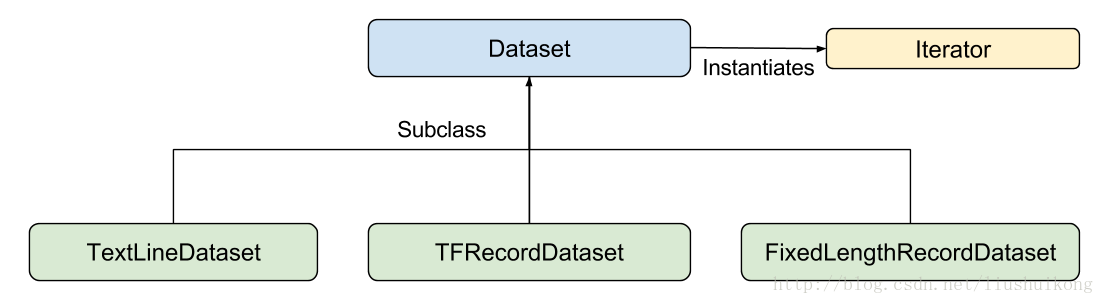
在初学时,我们只需要关注两个最重要的基础类:Dataset和Iterator。
总结:Dataset可以看作是相同类型“元素”的有序列表。在实际使用时,单个“元素”可以单独的一个数,也可以是向量,也可以是numpy数组、字符串、图片,甚至是tuple、list或者dict等。
1.3 元素(element)与组件(component)
首先明确两个非常重要的概念,元素与组件。
一个数据集包含多个元素element,每个元素的结构都相同——即dataset是由元素element构成;
一个元素包含一个或多个组件component,组件其实就是 tf.Tensor 对象(numpy数组、图像等等);
注意:为了方便大家理解,本文基于tensorflow1.13版本,以mnist手写字数据作为例子来说明。
# Fetch and format the mnist data
(x_train, y_train), (x_test, y_test)= tf.keras.datasets.mnist.load_data()
x_train=np.expand_dims(x_train,axis=3) #拓展图片数组的channel
x_test=np.expand_dims(x_test,axis=3)
dataset = tf.data.Dataset.from_tensor_slices((x_train,y_train))
'''
这就 构造了一个 dataset对象
这里的基本元素就是一个元组(x_train,y_train)
'''1.4 Iterator类
需要注意的是,Dataset只是对数据的一个包装,如果我们要获取数据,则需要将Dataset对象进一步转化成Iterator对象,然后通过迭代取得数据元素。
(1)非eager模式下的迭代操作——通过在session会话里面实现
如何将这个dataset中的元素取出呢?方法是从Dataset中实力化一个Iterator,然后对Iterator进行迭代。
# Fetch and format the mnist data
(x_train, y_train), (x_test, y_test)= tf.keras.datasets.mnist.load_data()
x_train=np.expand_dims(x_train,axis=3) #拓展图片数组的channel
x_test=np.expand_dims(x_test,axis=3)
dataset = tf.data.Dataset.from_tensor_slices((x_train,y_train)) #创建dataset对象
dataset=dataset.batch(32) #其实就是将数据包装成每一个batch有32个样本,如果不包装,则每一次迭代只会返回一组样本,包装之后每一次迭代返回32组样本
iterator = dataset.make_one_shot_iterator() # 通过dataset实例化Iterator对象
x,y = iterator.get_next() # 这里只迭代一次
with tf.Session() as sess:
train_x,train_y=sess.run([x,y])
print(train_x,train_y)
'''
这里的train_x是(32,28,28,1)
这里的train_y是(32,)
'''
(2)eager模式下的迭代
tf.enable_eager_execution() # 开启eager模式
(x_train, y_train), (x_test, y_test)= tf.keras.datasets.mnist.load_data()
x_train=np.expand_dims(x_train,axis=3) #拓展图片数组的channel
x_test=np.expand_dims(x_test,axis=3)
dataset = tf.data.Dataset.from_tensor_slices((x_train,y_train))
dataset=dataset.batch(32)
iterator = dataset.__iter__()
x,y = iterator.get_next()
print(x) #(32,28,28,1)
print(y) #(32,)上面是在tensorflow1.13版本,在tensorflow2.0版本中,也可以这样使用,不用开头那句tf.enable_eager_execution() 即可
总结:
(1)在非eager模式下:通过iterator = dataset.make_one_shot_iterator() 来实现dataset到Iterator的包装;
(2)在eager模式下:通过iterator = dataset.__iter__() 来实现dataset到Iterator的包装,其实在eager模式之下,dataset自己本身就是一个iterator,就可以直接通过for访问,不再需要构造iterator了;
语句iterator = dataset.make_one_shot_iterator()从dataset中实例化了一个Iterator,这个Iterator是一个“one shot iterator”,即只能从头到尾读取一次。one_element = iterator.get_next()表示从iterator里取出一个元素。如果一个dataset中元素被读取完了,再尝试sess.run(one_element)的话,就会抛出tf.errors.OutOfRangeError异常,这个行为与使用队列方式读取数据的行为是一致的。在实际程序中,可以在外界捕捉这个异常以判断数据是否读取完,请参考下面的代码:
with tf.Session() as sess:
try:
while True: #一直迭代,直到最后结束
print(sess.run([x,y]))
except tf.errors.OutOfRangeError: # 触发异常
print("end!")上面的过程演示了使用Dataset和Iterator的大致流程,当然它们的功能远远不止于此,下面再一一说明。在这里先做一个简单的总结:
(一)第一步:创建Dataset对象(两种创建方式)
(1)从内存中创建
tf.data.Dataset.from_tensor_slices(): 从tensor切片读取
tf.data.Dataset.from_tensor(): 从tensor读取
tf.data.Dataset.from_sparse_tensor_slices(): 从稀疏sparse tensor切边读取
tf.data.Dataset.from_generator(): 从生成器读取
(2)从文件中读取(这里不展开说,后面再详细介绍)
- tf.data.TextLineDataset():这个函数的输入是一个文件的列表,输出是一个dataset。dataset中的每一个元素就对应了文件中的一行。可以使用这个函数来读入CSV文件。
- tf.data.FixedLengthRecordDataset():这个函数的输入是一个文件的列表和一个record_bytes,之后dataset的每一个元素就是文件中固定字节数record_bytes的内容。通常用来读取以二进制形式保存的文件,如CIFAR10数据集就是这种形式。
- tf.data.TFRecordDataset():顾名思义,这个函数是用来读TFRecord文件的,dataset中的每一个元素就是一个TFExample。
(二)第二步:对创建的Dataset对象进行相关的处理
这里就包括对每一组样本进行变换、是否需要混洗、每一次分成多少个batch_size、重复多少次等等一系列的操作
(三)第三步:通过Dataset构建Iterartor对象
iterator = dataset.make_one_shot_iterator() : 创建单次迭代器(本次讨论的重点)
iterator = dataset.make_initializable_iterator() :创建可初始化的迭代器
iterator = tf.data.Iterator.from_structure() :创建可重新初始化的迭代器
创建feedable(可反馈式)的迭代器 :
(四)第四步:通过迭代器的get_next()方法迭代访问
注意事项:不管是tensorflow2.0之前的版本还是TensorFlow 2.0,数据加载都是采用tf.data,不过在eager模式下,tf.data.Dataset这个类将成为一个Python迭代器,我们可以直接取值:
dataset = tf.data.Dataset.range(10)
for i, elem in enumerate(dataset):
print(elem) # prints 0, 1, ..., 9这里我们只是展示了一个简单的例子,但是足以说明tf.data在TensorFlow 2.0下的变化,tf.data其它使用技巧和TensorFlow 1.x是一致的。
二、Dataset类的详解
2.1 Dataset类的属性
Properties:#Dataset类的属性,这几个属性在tensorflow2.0已经移除了
output_classes
output_shapes
output_typesdataset = tf.data.Dataset.from_tensor_slices((x_train,y_train))
print(dataset.output_classes)
print(dataset.output_types)
print(dataset.output_shapes)
'''运行结果为:
(<class 'tensorflow.python.framework.ops.Tensor'>, <class 'tensorflow.python.framework.ops.Tensor'>)
(tf.uint8, tf.uint8)
(TensorShape([Dimension(28), Dimension(28), Dimension(1)]), TensorShape([]))
'''在1.3中,说明了dataset、element、component三者之间的关系。在这里,
元素就是(x_train,y_train),他是一个元组;
组件就是x_train和y_train
其中,每一个组件又包含多个元素组成,比如这里x_train的形状是(samples,28,28,1),所以这个组件由(28,28,1)的tensor组成,y_train的形状是(samples,)所以它的每一个元素是一个标量。
(1)dataset.output_classes属性
返回每一个组件的组成元素的类型,这里组成x_train和y_train的都是Tensor;
(2)dataset.output_types属性
返回每一个组件的组成元素最终的的数据类型,这里组成x_train和y_train的都是都是整数;
(3)dataset.output_shapes属性
返回每一个组件的组成元素的的形状,这里组成x_train的是(28,28,1)和组成y_train的是一个标量,所以没有形状;
总结:其实可以将dataset看成一个有顺序的列表,里面的不管是元素还是组件,其实本质上是集合之间的层层嵌套。
2.2 Dataset类的方法
Dataset类的方法很多,这里先看一个方法的概述
def __init__(self):
def __iter__(self):
def __repr__(self):
def make_one_shot_iterator(self):
# 这是三个属性,前面已经介绍过了
#------------------------------------------
@abc.abstractproperty
def output_classes(self):
@abc.abstractproperty
def output_shapes(self):
@abc.abstractproperty
def output_types(self):
#------------------------------------------
# 这是三个从内存创建dataset对象的方法,from_sparse_tensor_slices()已经废除了
#------------------------------------------
@staticmethod
def from_tensors(tensors):
@staticmethod
def from_tensor_slices(tensors):
@staticmethod
def from_generator(generator, output_types, output_shapes=None, args=None):
#------------------------------------------
@staticmethod
@deprecation.deprecated(None, "Use `tf.data.Dataset.from_tensor_slices()`.")
def from_sparse_tensor_slices(sparse_tensor):
@staticmethod
def range(*args):
@staticmethod
def zip(datasets):
def concatenate(self, dataset):
def prefetch(self, buffer_size):
def _enumerate(self, start=0):
@staticmethod
def list_files(file_pattern, shuffle=None, seed=None):
# 这是用得最多的一些方法
#------------------------------------------
def repeat(self, count=None):
def shuffle(self, buffer_size, seed=None, reshuffle_each_iteration=None):
def cache(self, filename=""):
def take(self, count):
def skip(self, count):
def batch(self, batch_size, drop_remainder=False):
def map(self, map_func, num_parallel_calls=None):
def apply(self, transformation_func):
def reduce(self, initial_state, reduce_func):
#------------------------------------------
def shard(self, num_shards, index):
def padded_batch(self,batch_size,padded_shapes,padding_values=None,
drop_remainder=False):
def flat_map(self, map_func):
def interleave(self,cycle_length,block_length=1,num_parallel_calls=None):
def filter(self, predicate):
def window(self, size, shift=None, stride=1, drop_remainder=False):
def with_options(self, options):下面通过一个简单的例子来说明其中的一些方法的用途,因为方法太多了,这里就不再一一说明了,为了方便演示,本文的例子很简单,只有5组样本,然后没一个样本三个特征x1,x2,x3,一个标签y,先看一下数据如下:
import numpy as np
import tensorflow as tf
x2=np.arange(1,6,1)
x1=x2/10
x3=x2*10
X=np.vstack((x1,x2,x3))
X=np.transpose(X) #(5,3) 即5行3列,5组样本,3个特征
Y=np.random.rand(5,1) #(5,1),即5个标签(1)dataset.batch()方法
下面开始“四步走”
# 下面开始 “四步走” 过程
dataset = tf.data.Dataset.from_tensor_slices((X,Y)) # 第一步:构造dataset对象
#dataset=dataset.repeat()
dataset=dataset.batch(3) # 第二步:每次返回三组样本,相当于使用dataset相关的方法进行处理
xy_iter=dataset.make_one_shot_iterator() # 第三步:通过dataset创建iterator
x,y=xy_iter.get_next() # 第四步:通过iterator进行迭代,每次迭代一个batch_size
sample_count=np.shape(X)[0] # 即5组样本
batch_size=3
epochs=2
with tf.Session() as sess:
for epoch in range(epochs): #训练1个epoch的时候,恰好迭代完,如果这里的epoch大于1,则会在迭代完成之后报错
# while(True): # 会在迭代完成之后,报错,道标迭代结束
for i in range(math.ceil(sample_count/batch_size)): # 对每一个epoch进行迭代
x_,y_=sess.run([x,y])
print(x_)
print(y_)
print("=================================================")
'''运行结果为:
[[ 0.1 1. 10. ]
[ 0.2 2. 20. ]
[ 0.3 3. 30. ]]
[[0.89335087]
[0.35816996]
[0.55701785]]
=================================================
[[ 0.4 4. 40. ]
[ 0.5 5. 50. ]]
[[0.01605755]
[0.95078158]]
=================================================
'''上面的情况演示了dataset.batch()的作用,这里有一个问题,其实整个数据集我只遍历了一遍,一般在深度学习时候,我们将一个完整的迭代成为一个epoch,比如我有5个epoch,则需要将数据从头至尾迭代5次,这就是repeat函数的作用了。
(2)dataset.repeat()函数
下面来看一下dataset.repeat()的作用。
# 下面开始 “四步走” 过程
dataset = tf.data.Dataset.from_tensor_slices((X,Y)) # 第一步:构造dataset对象
dataset=dataset.repeat() # 第二步:每次返回三组样本,相当于使用dataset相关的方法进行处理
dataset=dataset.batch(3)
xy_iter=dataset.make_one_shot_iterator() # 第三步:通过dataset创建iterator
x,y=xy_iter.get_next() # 第四步:通过iterator进行迭代,每次迭代一个batch_size
sample_count=np.shape(X)[0] # 即5组样本
batch_size=3
epochs=2
with tf.Session() as sess:
for epoch in range(epochs): #训练1个epoch的时候,恰好迭代完,如果这里的epoch大于1,则会在迭代完成之后报错
for i in range(math.ceil(sample_count/batch_size)): # 对每一个epoch进行迭代
x_,y_=sess.run([x,y])
print(x_)
print(y_)
print("=================================================")这里的输出结果会每次输出三组样本,然后一直迭代不会停止,停止的次数取决于我们训练的epochs数目,这是非常常见的一种方式。
而很多时候我们需要对样本进行随机打乱操作,这时候就需要用到shuffle函数了,如下:
(3)dataset.shuffle()函数
# 下面开始 “四步走” 过程
dataset = tf.data.Dataset.from_tensor_slices((X,Y)) # 第一步:构造dataset对象
dataset=dataset.shuffle(100) # 第二步:每次返回三组样本,相当于使用dataset相关的方法进行处理
dataset=dataset.repeat()
dataset=dataset.batch(3)
xy_iter=dataset.make_one_shot_iterator() # 第三步:通过dataset创建iterator
x,y=xy_iter.get_next() # 第四步:通过iterator进行迭代,每次迭代一个batch_size
sample_count=np.shape(X)[0] # 即5组样本
batch_size=3
epochs=2
with tf.Session() as sess:
for epoch in range(epochs): #训练1个epoch的时候,恰好迭代完,如果这里的epoch大于1,则会在迭代完成之后报错
for i in range(math.ceil(sample_count/batch_size)): # 对每一个epoch进行迭代
x_,y_=sess.run([x,y])
print(x_)
print(y_)
print("=================================================")上面的这三个函数就是我们在使用dataset的时候最常见、用的最多的三个了,下面总结如下:
(1)dataset.batch(batch_size)函数:每次迭代的时候返回batch_size个样本,这是我们训练的常见操作;
(2)dataset.repeat(count)函数:这个函数可以接受一个数字作为参数,表示一共重复多少次,这个数字和我们在训练的时候的epochs是一致的,我们也可以不指定具体的重复次数,这样就会一直迭代下去,直到我们所有的epochs结束;
(3)dataset.shuffle(buffer_size)函数:使用shuffle()方法将Dataset随机洗牌,默认是在数据集中对每一个epoch洗牌,即每完成一个epoch之后就随机混洗一次,这种处理可以避免过拟合。我们也可以设置buffer_size参数,下一个元素将从这个固定大小的缓存中按照均匀分布抽取,一般随意设置即可。
2.3 Dataset类的两个高级方法
(1)dataset.map()方法
这里需要注意,map()方法是针对dataset的组成元素而言的,也就是说,对每一个元素进行操作处理(参见前面的,什么是dataset的元素element,什么是组成元素的组件component)
在本例中,由于
dataset = tf.data.Dataset.from_tensor_slices((X,Y))所以基本的元素element就是(X,Y)了。所以map映射的函数需要接受这两个参数作为参数,比如我要给每一个X特征的特征值进行平方,然后Y的值不变化,可以像下面这样处理。
def x_square(x,y):
'''
这里的x,y是针对一个样本而言的,但需要注意的是:
x的形状应该是(3,),而y的形状是(1,)的
'''
x=tf.pow(x,2)
return x,y# 下面开始 “四步走” 过程
dataset = tf.data.Dataset.from_tensor_slices((X,Y)) # 第一步:构造dataset对象
dataset=dataset.map(x_square) # 第二步:每次返回三组样本,相当于使用dataset相关的方法进行处理
dataset=dataset.shuffle(100)
dataset=dataset.repeat()
dataset=dataset.batch(3)
xy_iter=dataset.make_one_shot_iterator() # 第三步:通过dataset创建iterator
x,y=xy_iter.get_next() # 第四步:通过iterator进行迭代,每次迭代一个batch_size
sample_count=np.shape(X)[0] # 即5组样本
batch_size=3
epochs=2
with tf.Session() as sess:
for epoch in range(epochs): #训练1个epoch的时候,恰好迭代完,如果这里的epoch大于1,则会在迭代完成之后报错
for i in range(math.ceil(sample_count/batch_size)): # 对每一个epoch进行迭代
x_,y_=sess.run([x,y])
print(x_)
print(y_)
print("=================================================")现在我们发现X的每一个特征的值都进行了平方,再看一个更常用的例子:
# 解析每一个路径
def _parse_function(filename, label):
image_string = tf.read_file(filename)
image_decoded = tf.image.decode_image(image_string)
image_resized = tf.image.resize_images(image_decoded, [28, 28])
return image_resized, label
# 每一张图片的路径
filenames = tf.constant(["/var/data/image1.jpg", "/var/data/image2.jpg", ...])
# 每一张图片所对应的标签
labels = tf.constant([0, 37, ...])
dataset = tf.data.Dataset.from_tensor_slices((filenames, labels))
dataset = dataset.map(_parse_function) #对每一个路径进行解析map()函数总结:
函数原型如下:
def map(self, map_func, num_parallel_calls=None):第二个参数num_parallel_calls:是一个可选参数,他代表同时并行处理几个元素(注意这里元素element的含义),如果不设置它,则表示每一个元素逐个处理。

















 645
645

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









