




 本文介绍了PHP的QueryList库在爬虫开发中的应用,通过实例展示了如何利用该库抓取网页内容,包括HTML元素的选择、数据提取和处理等基本操作。
本文介绍了PHP的QueryList库在爬虫开发中的应用,通过实例展示了如何利用该库抓取网页内容,包括HTML元素的选择、数据提取和处理等基本操作。
<?php
require 'QueryList/phpQuery.php';
require 'QueryList/QueryList.php';
use QL\QueryList;
$url = 'http://www.netbian.com/baidu';
$rules = array(
'sensus_img'=> array('.list ul li>a>img','src'),
'sensus_img_text'=> array('.list ul li>b>a','text'),
'update_time'=> array('.list ul li p','text')
);
$data = QueryList::Query($url,$rules)->data;
$time = date('Y-m-d');
if(!is_dir($time)){
mkdir($time);
}
foreach ($data as $key => $value) {
if(isset($value['sensus_img']) && $value['sensus_img']){
$img_ext = substr($value['sensus_img'], strrpos($value['sensus_img'], '.'));//图片后缀
if(isset($value['sensus_img_text']) && $value['sensus_img_text']){
//phpquery在抓取目标页面代码时,未能获取到meta中的编码信息时一律转换为ISO-8859-1编码,于是先将抓来的中文由utf-8转换为ISO-8859-1 如下mb_convert_encoding($value['sensus_img_text'],'ISO-8859-1','utf-8') ,然后输出中文时就发现他们变成了比较熟悉的gbk乱码形式,然后再从gbk转换成utf-8即可,mb_convert_encoding($value['sensus_img_text'],'utf-8','GBK'),前后转了两次解决了中文乱码问题
$value['sensus_img_text'] = mb_convert_encoding($value['sensus_img_text'],'ISO-8859-1','utf-8');
$value['sensus_img_text'] = mb_convert_encoding($value['sensus_img_text'],'utf-8','GBK');
$value['update_time'] = mb_convert_encoding($value['update_time'],'ISO-8859-1','utf-8');
$value['update_time'] = mb_convert_encoding($value['update_time'],'utf-8','GBK');
//解决file_get_contents和file_put_contents的乱码问题,其根源在操作系统上,系统编码的问题,于是对文件名进行转码.文件用的是utf-8编码,但是系统默认为gbk转换成gbk即可解决
$value['sensus_img_text'] = mb_convert_encoding($value['sensus_img_text'],'gbk','utf-8');
file_put_contents('./'.$time.'/'.$value['sensus_img_text'].$img_ext, file_get_contents($value['sensus_img']));
}
}
}
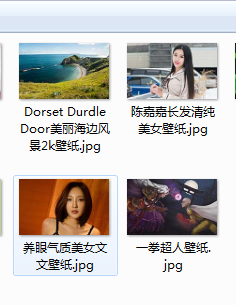
截图:


















 860
860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









