




涉及的docker容器镜像下载地址:
下载链接:https://pan.quark.cn/s/3d9092f67053
前提:部署的机器需要提前安装docker以及docker-compose
背景
一家公司开发的系统,批量部署在多个下级公司,这个公司需要负责监控所有下级公司系统的状态。并且由于业务需求,下级公司仅能访问这家公司服务器的特定端口,不能直接访问influxdb的端口。所以需要加个中间层emqx,也可以选择rabbitmq,kafka。

部署架构图
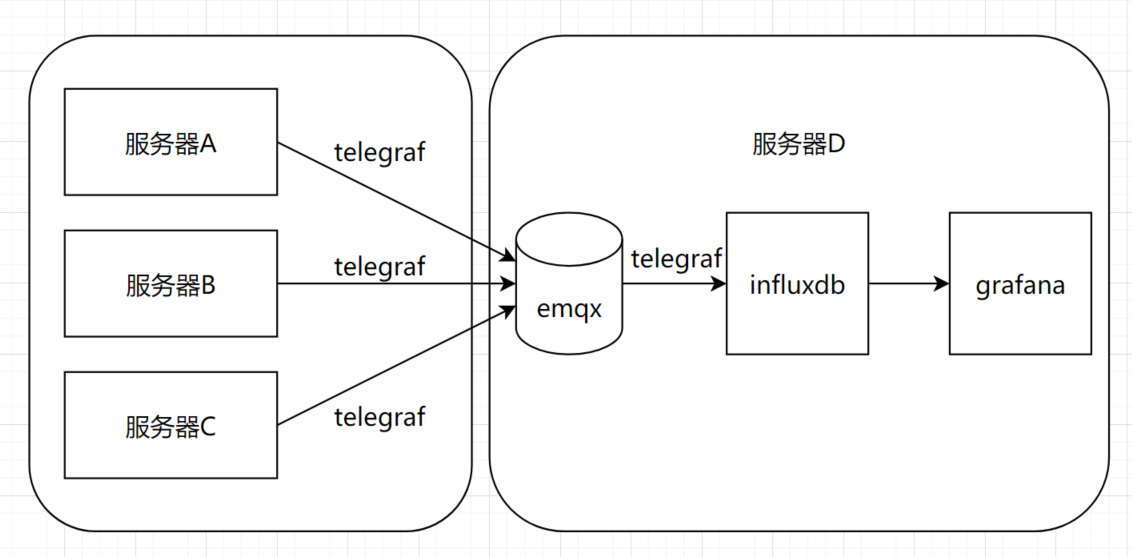
第一版(实现)
一、服务器A部署 - 10.10.10.22
1、创建Telegraf配置目录
mkdir -p ~/telegraf/config
2、编写Telegraf配置
vim ~/telegraf/config/telegraf.conf
[agent]
interval = "10s"
[[inputs.cpu]]
percpu = false
totalcpu = true
[[inputs.mem]]
[[inputs.disk]]
mount_points = ["/"]
[[inputs.net]]
[[outputs.mqtt]]
servers = ["tcp://10.10.10.23:1883"]
topic = "monitoring/data"
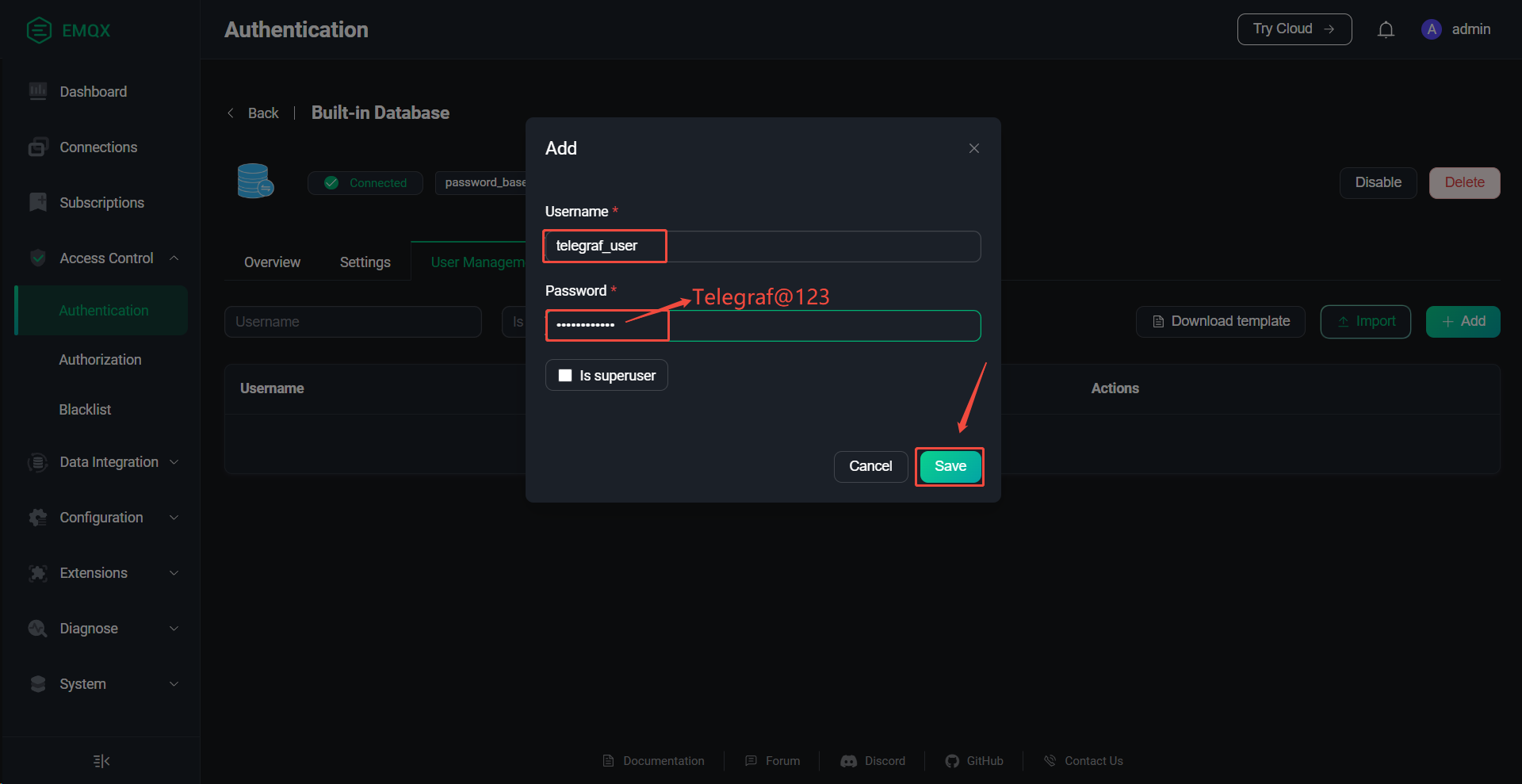
username = "telegraf_user"
password = "Telegraf@123"
data_format = "influx"
二、服务器D部署 - 10.10.10.23
1、创建工作目录
mkdir -p ~/monitoring/{emqx,influxdb,grafana,telegraf}
cd ~/monitoring
2、编写Docker Compose文件
vim docker-compose.yml
version: '3'
services:
# EMQX消息中间件
emqx:
image: emqx/emqx:5.0.8
container_name: emqx
ports:
- "1883:1883" # MQTT协议端口
- "18083:18083" # 控制台端口
environment:
- EMQX_DASHBOARD__DEFAULT_USERNAME=admin
- EMQX_DASHBOARD__DEFAULT_PASSWORD=Admin@123
volumes:
- ./emqx/data:/opt/emqx/data
networks:
- monitoring_net
# 时序数据库
influxdb:
image: influxdb:1.8.10
container_name: influxdb
ports:
- "8086:8086"
volumes:
- ./influxdb/data:/var/lib/influxdb
environment:
- INFLUXDB_DB=monitoring
networks:
- monitoring_net
# 可视化平台
grafana:
image: grafana/grafana:9.5.6
container_name: grafana
ports:
- "3000:3000"
volumes:
- ./grafana/data:/var/lib/grafana
networks:
- monitoring_net
# 数据消费者
telegraf_consumer:
image: telegraf:1.34.4
container_name: telegraf_consumer
volumes:
- ./telegraf/telegraf.conf:/etc/telegraf/telegraf.conf
networks:
- monitoring_net
networks:
monitoring_net:
driver: bridge
3、配置Telegraf消费者
创建配置文件
vim telegraf/telegraf.conf
[agent]
interval = "10s"
flush_interval = "30s"
[[inputs.mqtt_consumer]]
servers = ["tcp://emqx:1883"]
topics = ["monitoring/data"]
username = "telegraf_user"
password = "Telegraf@123"
data_format = "influx"
[[outputs.influxdb]]
urls = ["http://influxdb:8086"]
database = "monitoring"
timeout = "10s"
4、授权目录
chown -R 1000:1000 emqx
chown -R 472:472 grafana
5、启动服务
# 此时telegraf_consumer会启动失败,因为无法连接emqx,暂时不管
docker-compose up -d

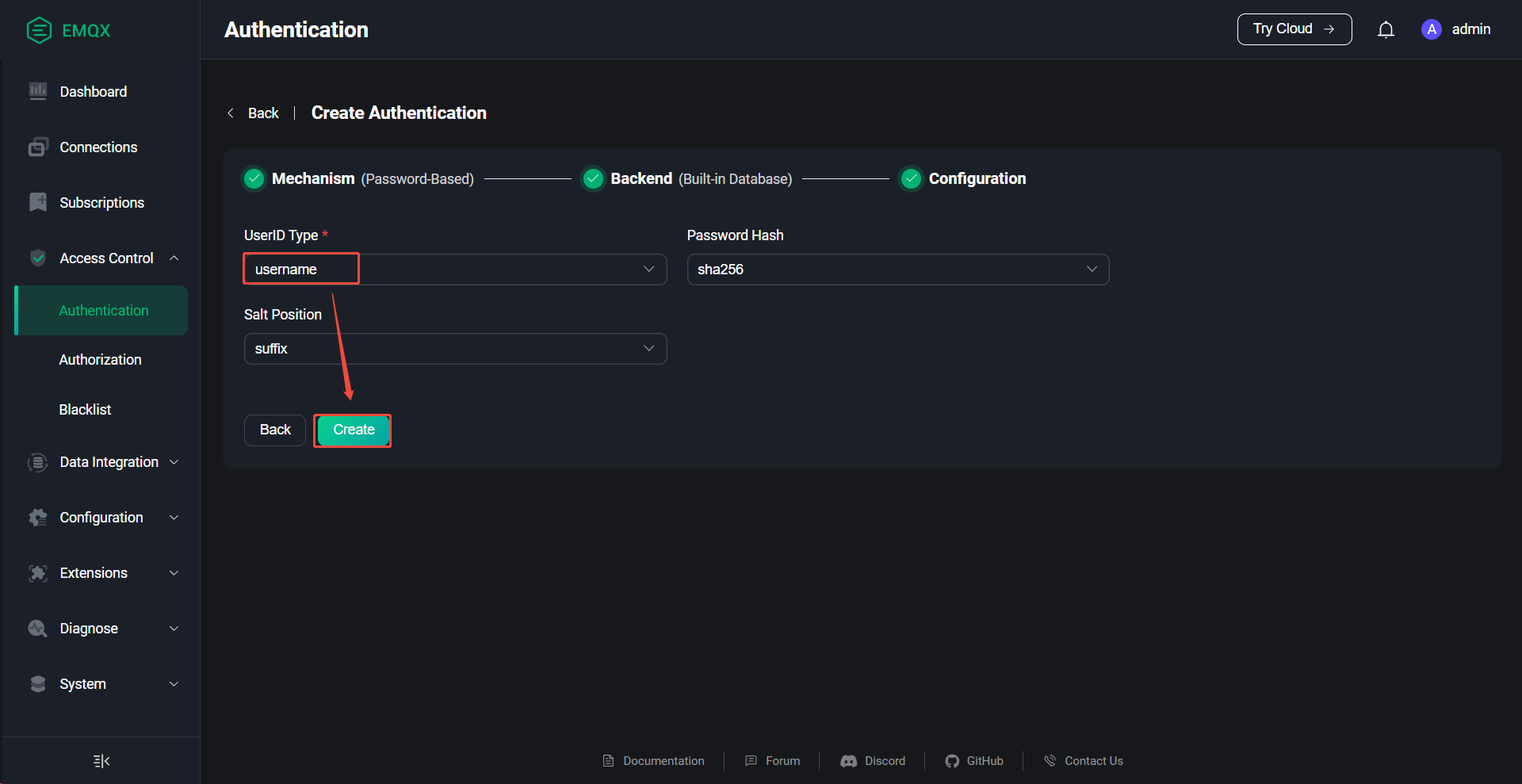
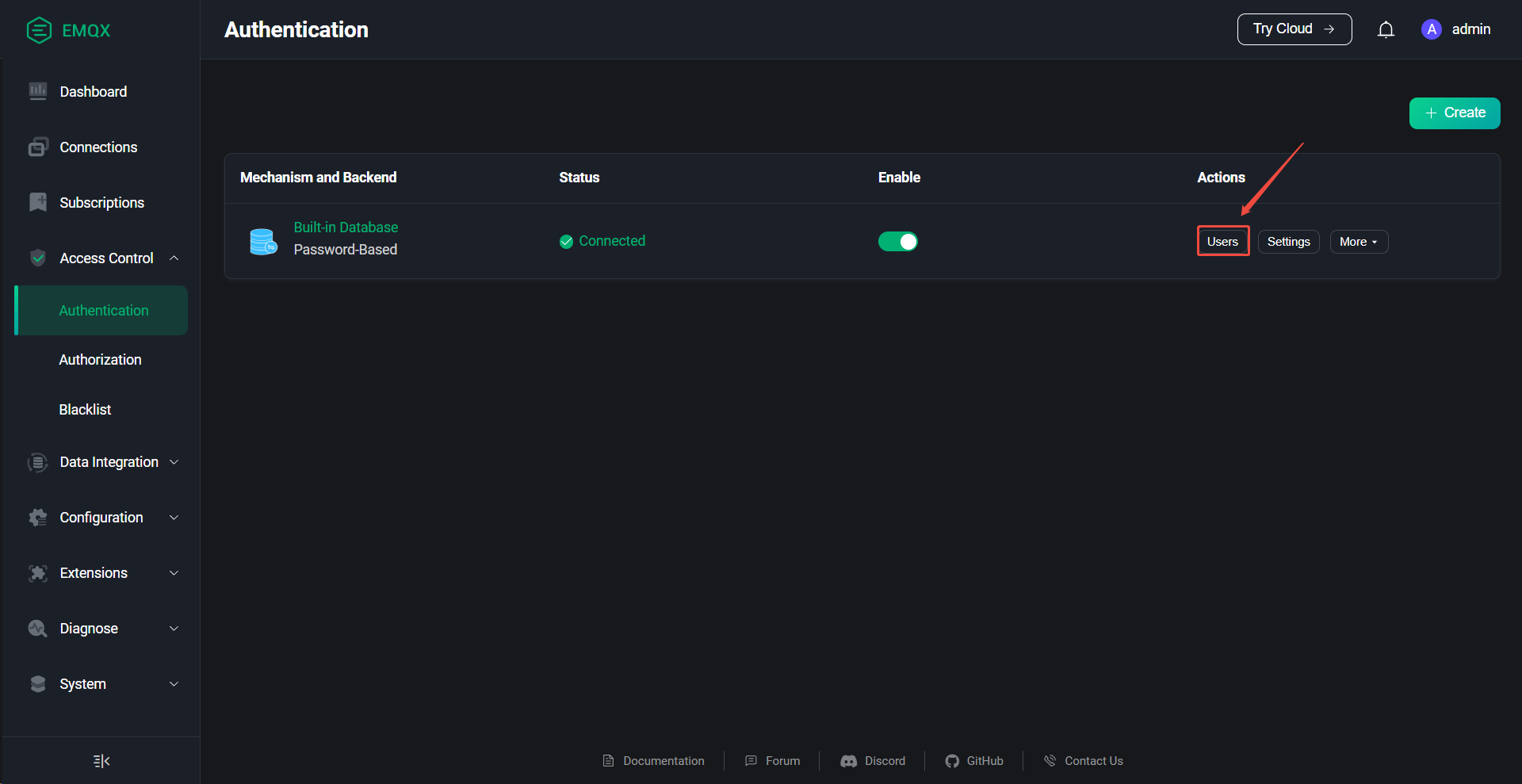
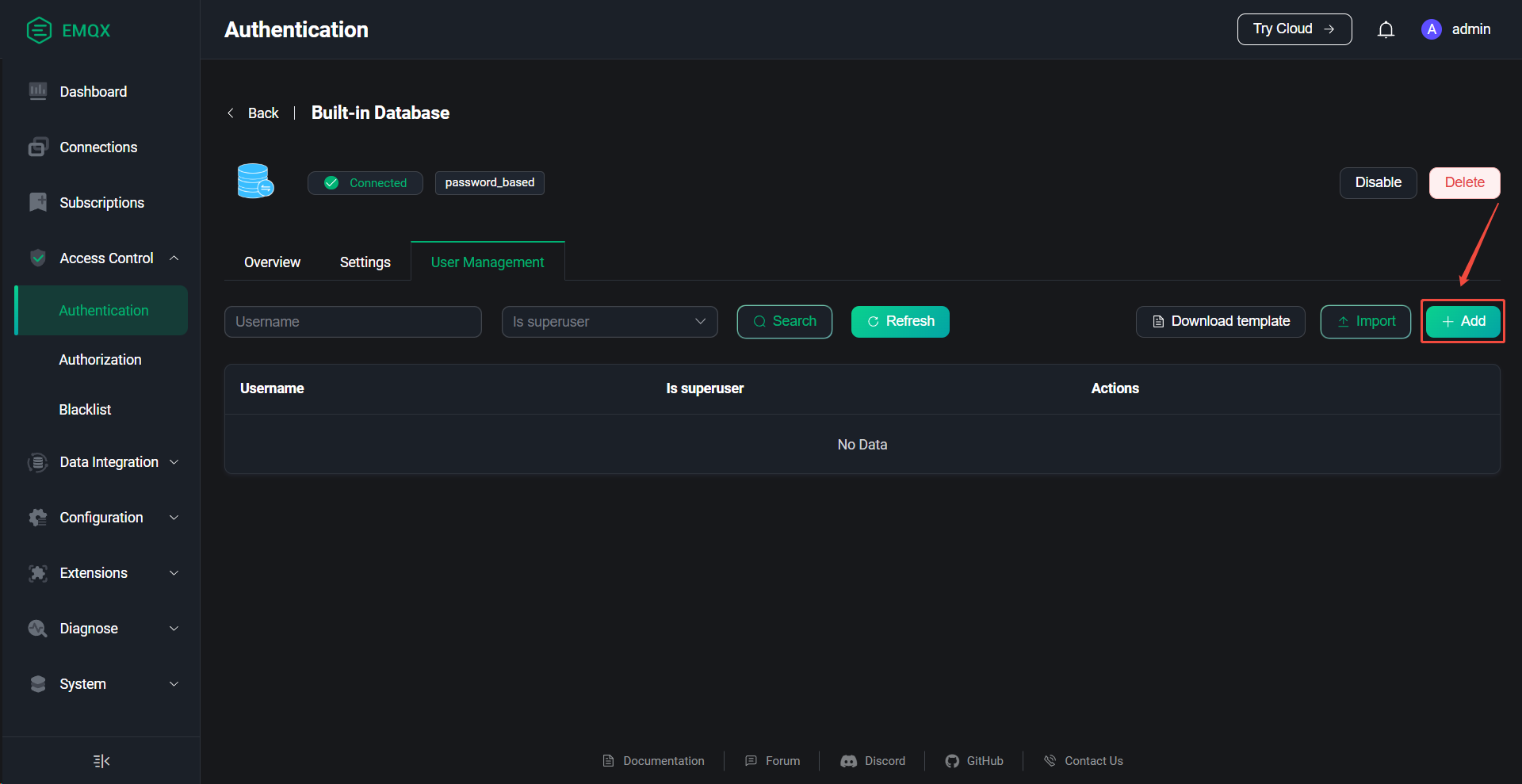
6、EMQX创建授权用户
访问控制台:http://10.10.10.23:18083
账号:admin
密码:Admin@123
7、重启telegraf-consumer
docker-compose restart telegraf_consumer
8、启动服务器A上的telegraf
docker run -d --name telegraf -v ~/telegraf/config/telegraf.conf:/etc/telegraf/telegraf.conf telegraf:1.34.4
三、验证
1、查看emqx中topic消息
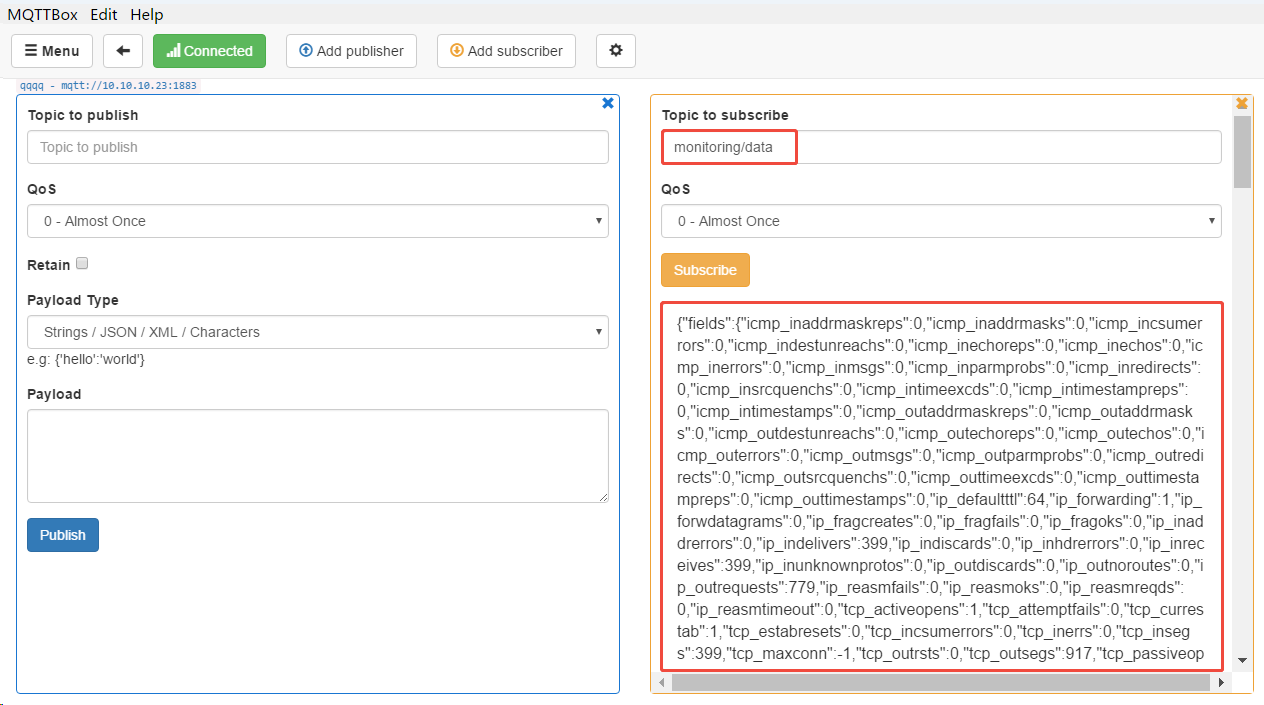
2、查询influxdb数据
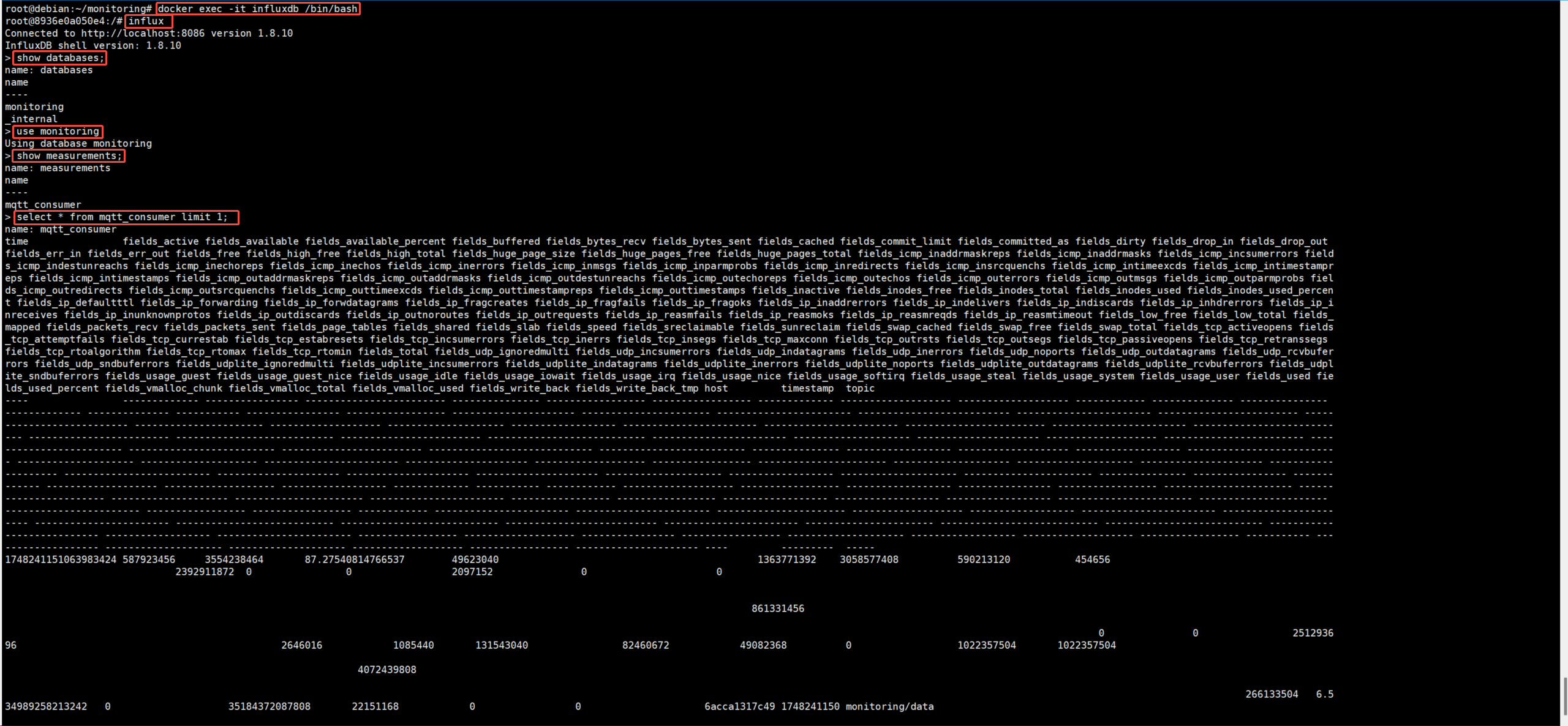
缺点:所有监控指标都写入到了一个measurement中,未后续使用grafana展示数据带来不便。
第二版(优化 - 指标分类)
目标:将不同指标信息输出到emqx的不同topic
一、服务器A修改 - 10.10.10.22
1、修改服务器A的telegraf.conf配置文件
[agent]
interval = "10s"
[[inputs.cpu]]
percpu = false
totalcpu = true
[[inputs.mem]]
[[inputs.disk]]
mount_points = ["/"]
[[inputs.net]]
[[outputs.mqtt]]
servers = ["tcp://10.10.10.23:1883"]
topic = "monitoring/{{ .Name }}" # 动态主题,按measurement分类(如monitoring/cpu、monitoring/mem)
username = "telegraf_user"
password = "Telegraf@123"
data_format = "influx"
二、服务器D修改 - 10.10.10.23
1、修改服务器D的telegraf.conf配置文件
[agent]
interval = "10s"
flush_interval = "30s"
[[inputs.mqtt_consumer]]
servers = ["tcp://emqx:1883"]
topics = ["monitoring/#"] # 订阅所有子主题
username = "telegraf_user"
password = "Telegraf@123"
data_format = "influx"
topic_tag = "measurement" # 将主题名写入tag
[[processors.starlark]]
source = '''
def apply(metric):
# 从主题名提取measurement(例如monitoring/cpu → cpu)
topic = metric.tags["measurement"]
metric.name = topic.split("/")[-1]
return metric
'''
[[outputs.influxdb]]
urls = ["http://influxdb:8086"]
database = "monitoring"
timeout = "10s"
三、重启所有telegraf
1、重启服务器A的telegraf
docker restart telegraf
2、重启服务器D的telegraf
docker-compose restart telegraf_consumer
四、验证
1、查看emqx中topic消息
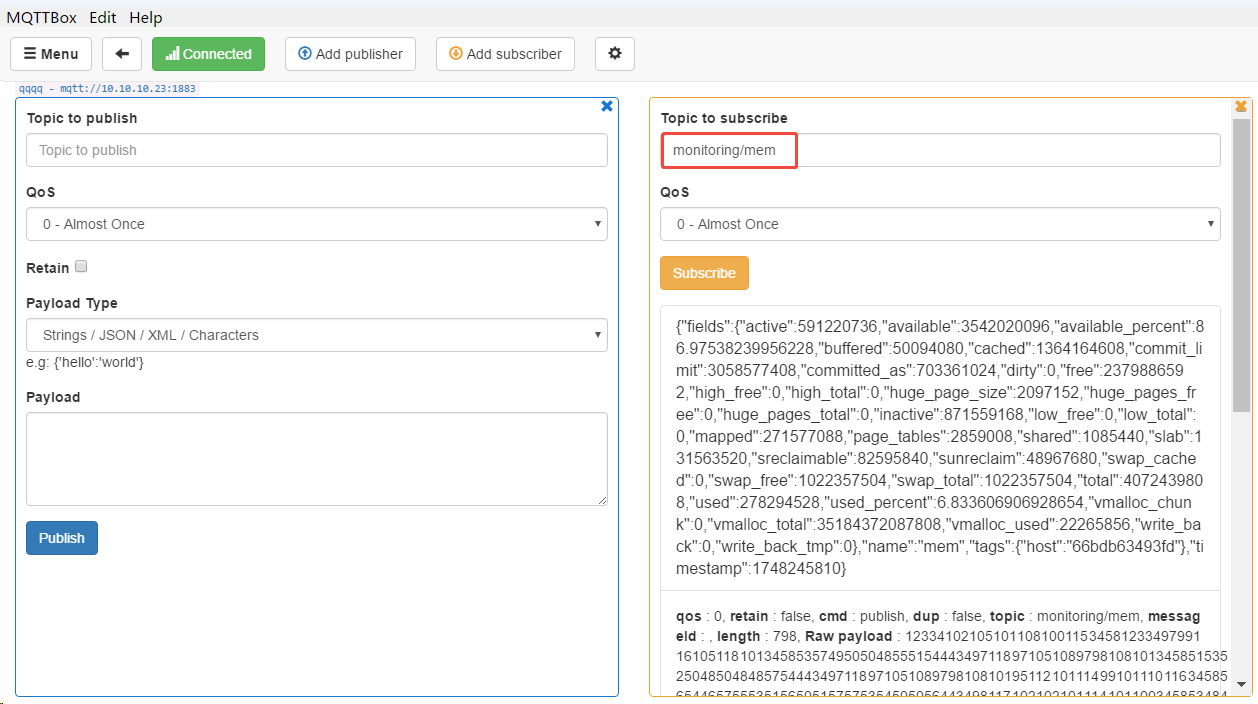
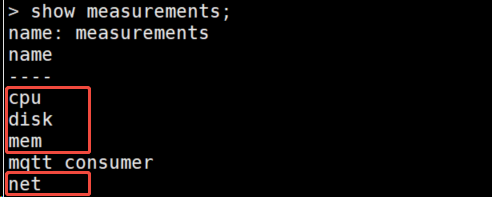
2、查询influxdb数据
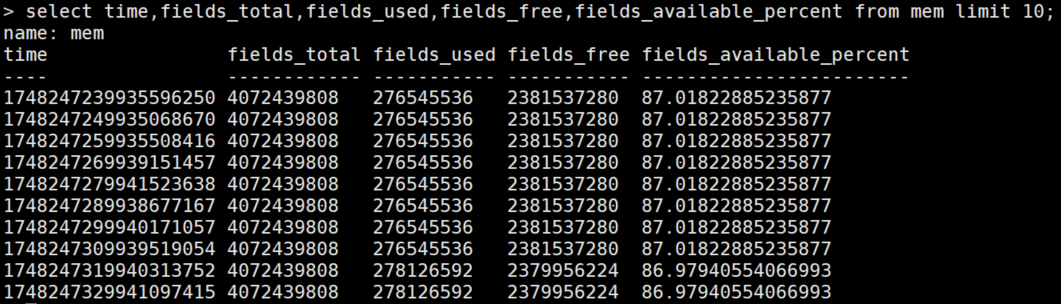
五、配置grafana
浏览器访问http://10.10.10.23:3000
账号admin
密码admin
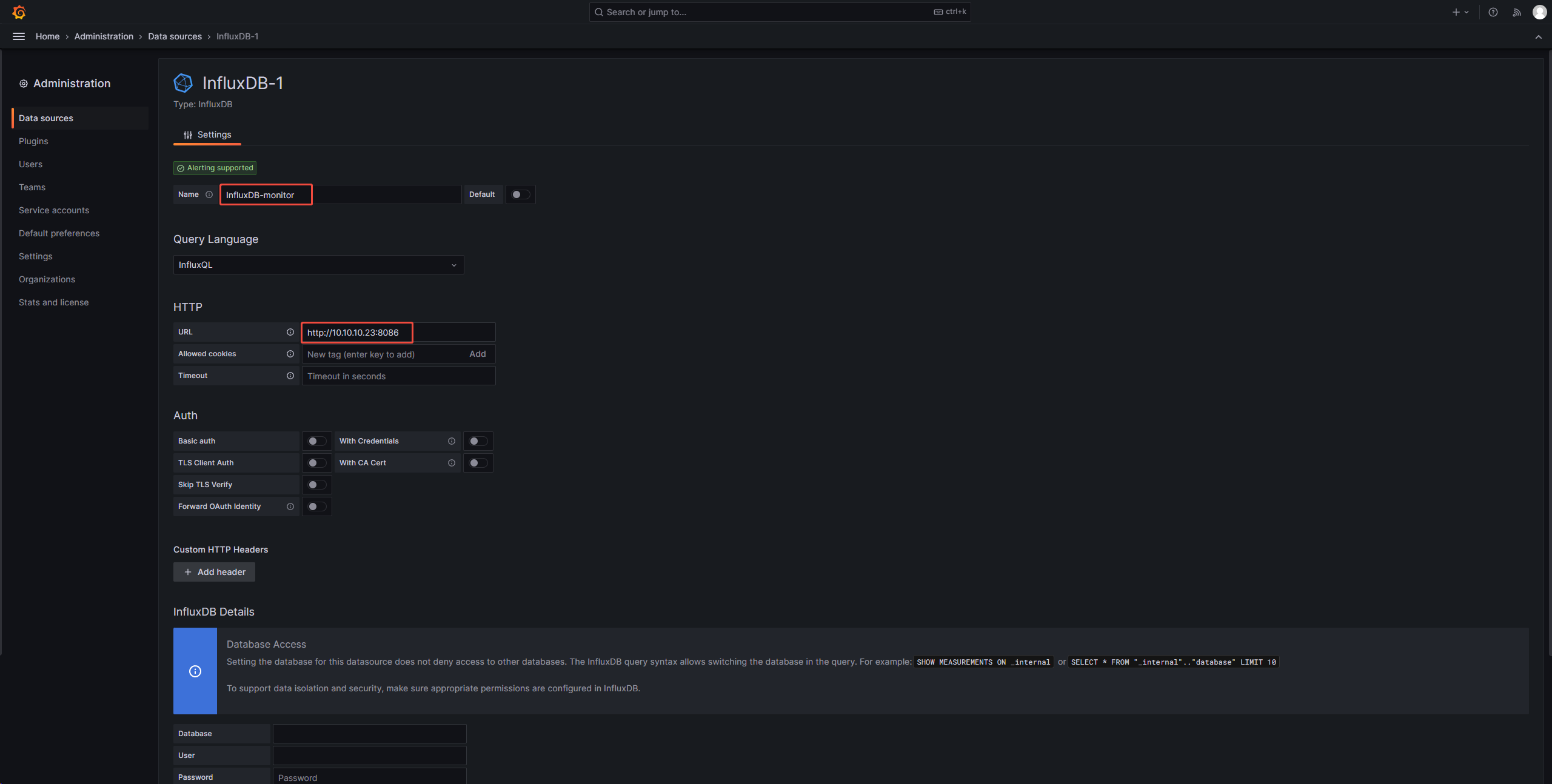
1、添加influxdb数据源
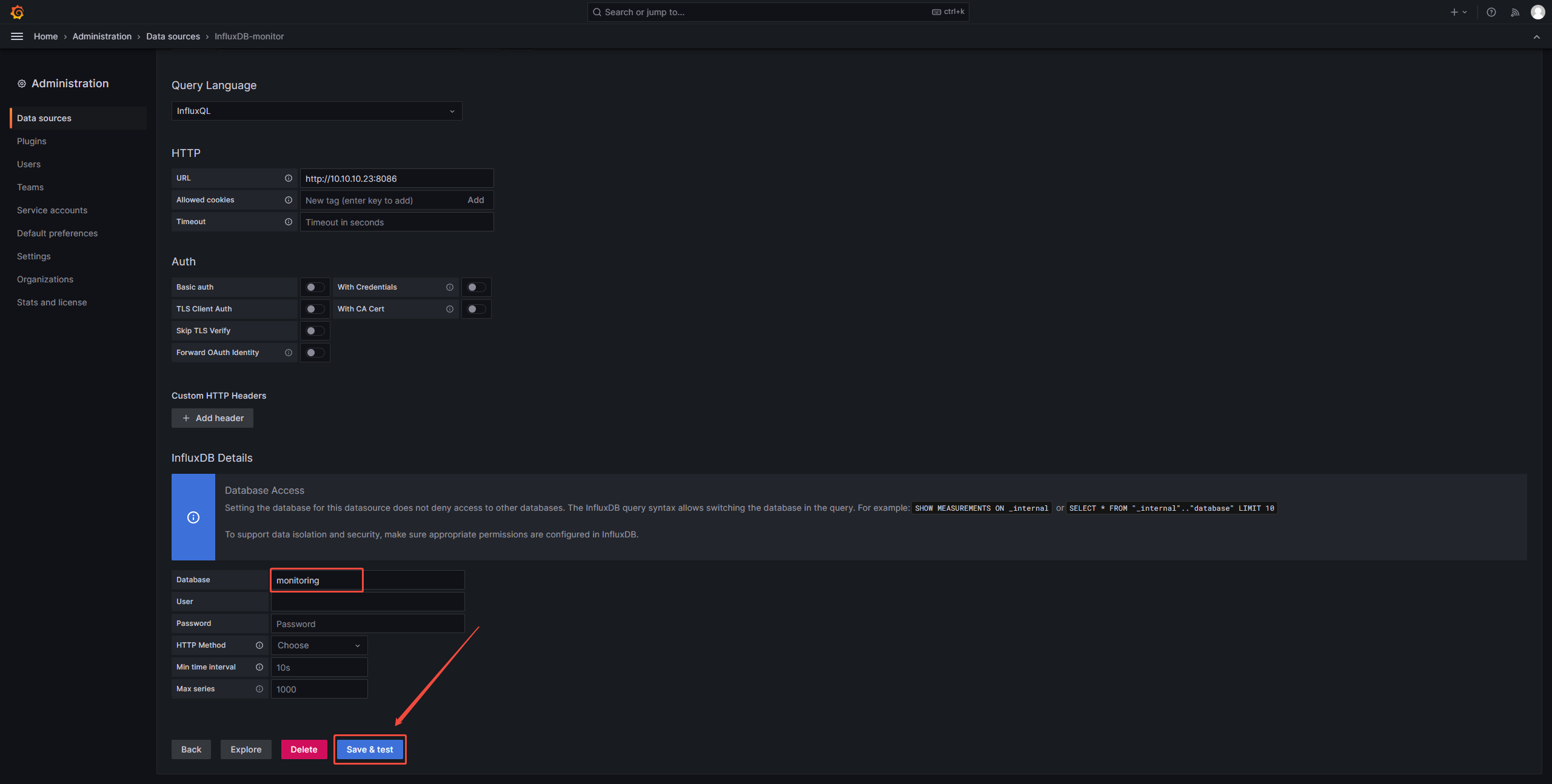
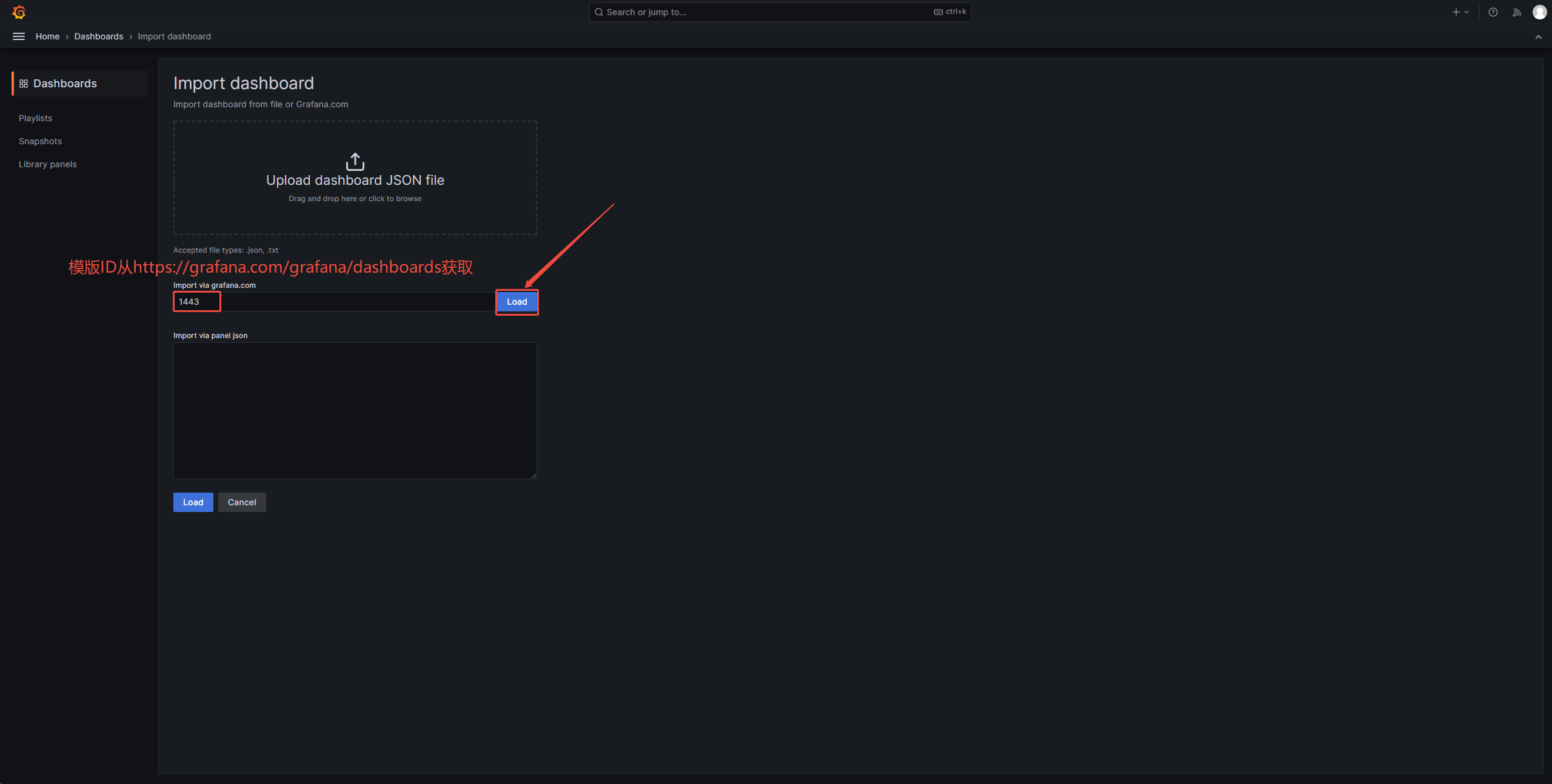
2、配置仪表盘
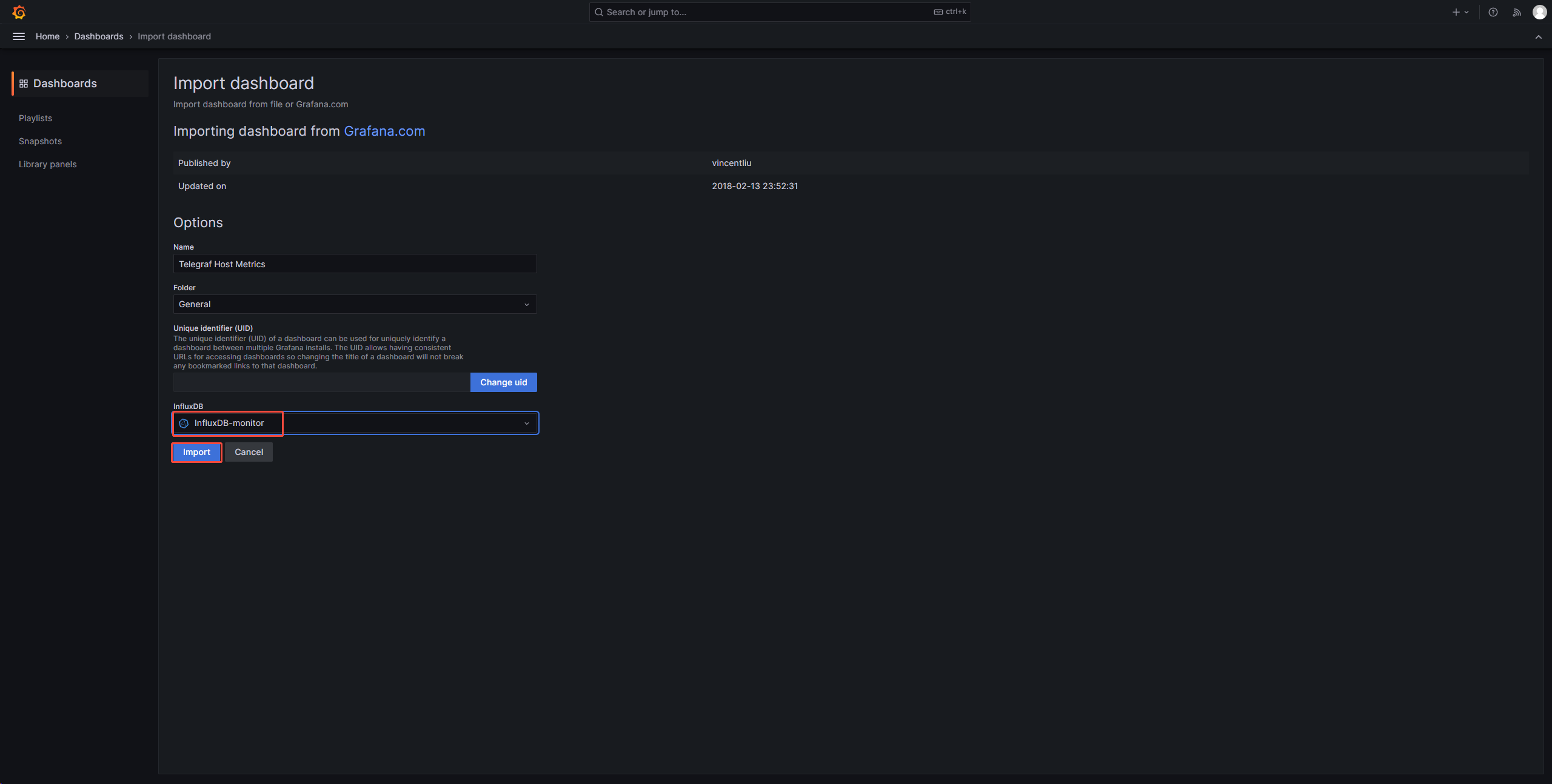
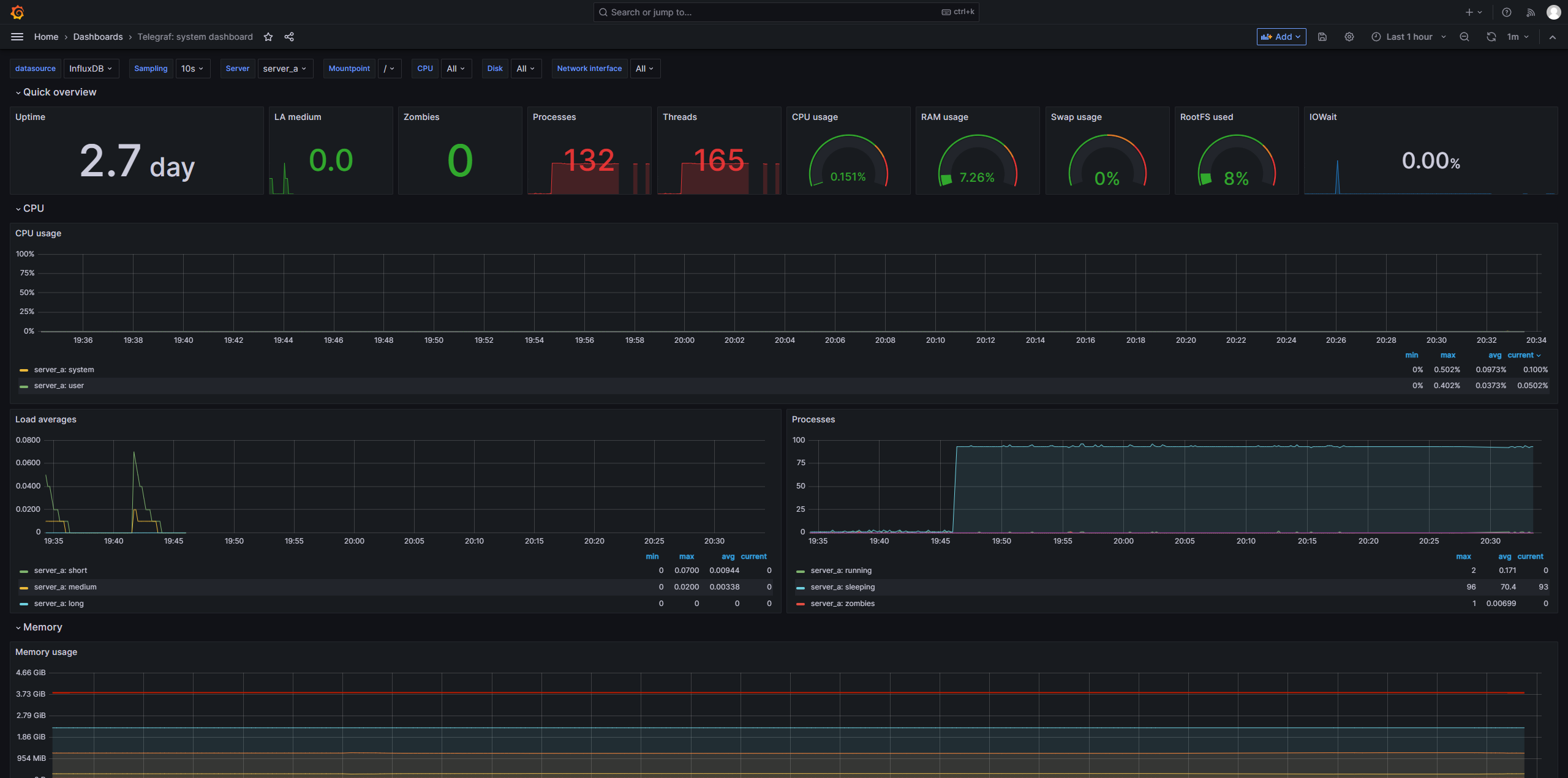
3、仪表盘对应telegraf配置
此grafana模版的采集端配置为:
[agent]
interval = "10s"
round_interval = true
metric_batch_size = 1000
metric_buffer_limit = 10000
collection_jitter = "0s"
flush_interval = "10s"
flush_jitter = "0s"
precision = ""
debug = false
quiet = false
hostname = "server_a"
omit_hostname = false
[[inputs.cpu]]
percpu = true
totalcpu = true
fieldexclude = ["time_*"]
[[inputs.disk]]
ignore_fs = ["tmpfs", "devtmpfs"]
[[inputs.diskio]]
[[inputs.kernel]]
[[inputs.mem]]
[[inputs.processes]]
[[inputs.swap]]
[[inputs.system]]
[[inputs.net]]
[[inputs.netstat]]
[[inputs.interrupts]]
[[inputs.linux_sysctl_fs]]
[[outputs.mqtt]]
servers = ["tcp://10.10.10.23:1883"]
topic = "monitoring/{{ .Name }}" # 动态主题,按measurement分类(如monitoring/cpu、monitoring/mem)
username = "telegraf_user"
password = "Telegraf@123"
data_format = "influx"
[[outputs.file]]
files = ["stdout"]
第三版(优化 - 增加自定义指标)
一、服务器A修改 - 10.10.10.22
1、修改telegraf配置文件
# 最顶部添加
[global_tags]
ip = "10.10.10.22"
sys_name = "ERP办公系统"
2、重启telegraf
docker restart telegraf
3、查询influxdb数据
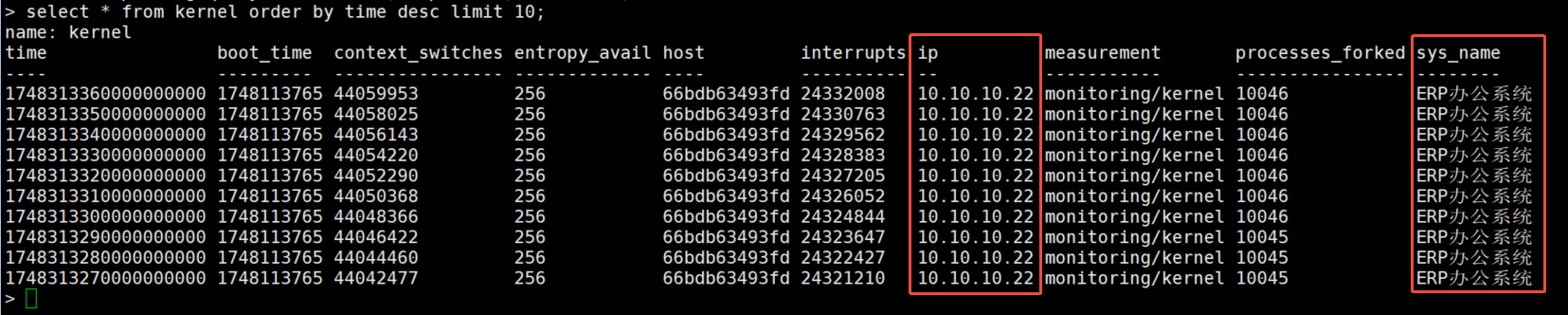
4、为什么InfluxDB中的host标签是“66bdb63493fd”?
原因分析:
Telegraf运行在Docker容器中时,默认会使用容器的主机名(即Docker容器的短ID)作为host标签的值。
Telegraf的[agent]配置中默认启用hostname参数,它会自动获取操作系统的主机名。在容器化部署中,该主机名就是容器的ID。
解决方案:
方法一:直接覆盖host标签
[global_tags]
host = "server_a" # 自定义主机名
ip = "10.10.10.23"
sys_name = "ERP办公系统"
[agent]
interval = "10s"
omit_hostname = true # Telegraf 不会自动添加 host 标签
......
方法二:通过hostname参数定义
[agent]
interval = "10s"
hostname = "server_a" # 直接指定主机名
omit_hostname = false # 默认值,Telegraf会自动采集当前运行机器的主机名,并将其作为 host 标签添加到所有采集的指标数据中
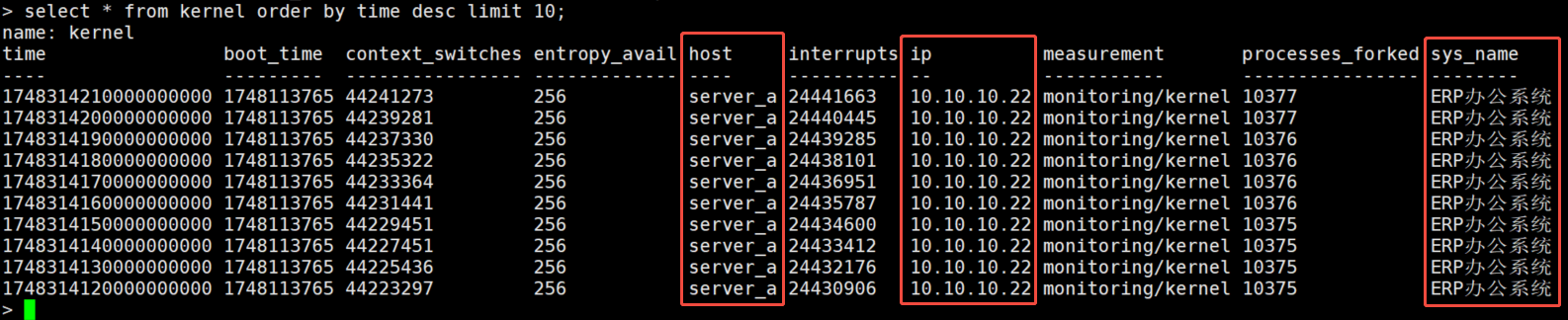
重启telegraf
docker restart telegraf
查询influxdb数据,至此结束。


















 4902
4902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









