






简历导出工具使用的PySimpleGUI组件5.0.0版本之后开始收费了
4.60.5版本及之前都是免费的
先卸载PySimpleGUI5
pip uninstall PySimpleGUI
(base) PS C:\Users\admin> pip uninstall PySimpleGUI
Found existing installation: PySimpleGUI 5.0.6
Uninstalling PySimpleGUI-5.0.6:
Would remove:
d:\env\anaconda3\lib\site-packages\pysimplegui-5.0.6.dist-info\*
d:\env\anaconda3\lib\site-packages\pysimplegui\*
d:\env\anaconda3\scripts\psghelp.exe
d:\env\anaconda3\scripts\psghome.exe
d:\env\anaconda3\scripts\psgmain.exe
d:\env\anaconda3\scripts\psgupgrade.exe
d:\env\anaconda3\scripts\psgver.exe
d:\env\anaconda3\scripts\psgwatermarkoff.exe
d:\env\anaconda3\scripts\psgwatermarkon.exe
Proceed (Y/n)? y
Successfully uninstalled PySimpleGUI-5.0.6再安装PySimpleGUI-4-foss
pip install PySimpleGUI-4-foss
(base) PS C:\Users\admin> pip install PySimpleGUI-4-foss
Collecting PySimpleGUI-4-foss
Downloading PySimpleGUI_4_foss-4.60.4.1-py3-none-any.whl.metadata (1.1 kB)
Downloading PySimpleGUI_4_foss-4.60.4.1-py3-none-any.whl (689 kB)
---------------------------------------- 689.5/689.5 kB 966.3 kB/s eta 0:00:00
Installing collected packages: PySimpleGUI-4-foss
Successfully installed PySimpleGUI-4-foss-4.60.4.1python脚本中的引用不变:
import PySimpleGUI as sg熟悉的界面回来了
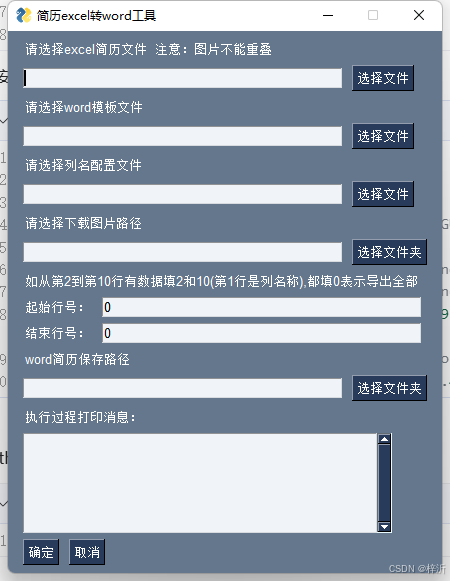
'''
需要安装的三方依赖包:
docxtpl
pip install docxtpl -i https://pypi.tuna.tsinghua.edu.cn/simple
pandas
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
PySimpleGUI
pip install PySimpleGUI -i https://pypi.tuna.tsinghua.edu.cn/simple
aiohttp
pip install aiohttp -i https://pypi.tuna.tsinghua.edu.cn/simple
'''
from openpyxl import load_workbook
from docxtpl import InlineImage
from docx.shared import Mm
from docxtpl import DocxTemplate
import pandas as pd
import requests
from io import BytesIO
from os import path
from PIL import Image
import time
from datetime import datetime
import sys
import shutil
import os
import PySimpleGUI as sg
import logging
import logging.config
import threading
import asyncio
import aiohttp
from pathlib import Path
import warnings
# 用于返回指定路径下特定文件的绝对路径,返回文件的文件名中须包含给定字符串
def find_files(path, pattern):
for root, dirs, files in os.walk(path):
for name in files:
if pattern in name:
return os.path.join(root, name)
return None
# 参数resume_table是腾讯文档导出的excel简历汇总表, word_template是word简历模板,
# default_pic是默认空白图片, image_path是图片保存路径, cfg_table是配置excel简历列名与word简历模板中每项对应关系的表
#def xlsx2docx_resume_converter(resume_table, word_template, default_pic, image_path, cfg_table, docx_path):
# start_n, end_n, 表示要导出的起始行号和结束行号
def xlsx2docx_resume_converter(resume_table, word_template, start_n, end_n, image_path, cfg_table, docx_path, log_path):
# 程序开始时间
start_time = time.time()
print(f"{time.strftime('%X')}开始导出")
data = pd.read_excel(resume_table, dtype=str)
# 取excel表格的行数
total = data.shape[0]
if start_n==0 and end_n==0:
n1 = 0
n2 = total
else:
n1 = start_n - 2 if start_n >= 2 else 0
n2 = end_n - 1 if end_n >= 2 else 0
tpl = DocxTemplate(word_template)
cfg_str = pd.read_excel(cfg_table, sheet_name='字符项')
n_cfg_str = cfg_str.shape[1]
cfg_date = pd.read_excel(cfg_table, sheet_name='日期项')
n_cfg_date = cfg_date.shape[1]
cfg_pic = pd.read_excel(cfg_table, sheet_name='图片项')
# 配置表的列数
n_cfg_pic = cfg_pic.shape[1]
# 配置表的行数
c_cfg_pic = cfg_pic.shape[0]
cfg_filename = pd.read_excel(cfg_table, sheet_name='文件名')
n_cfg_filename = cfg_filename.shape[1]
# 为原始表增加下载图片本地路径列
logfilename1 = path.join(log_path, '添加列前.xlsx')
data.to_excel(logfilename1)
data = pd.concat([data, pd.DataFrame(columns=[f"{cfg_pic.iloc[:,j].name}_localpath" for j in range(n_cfg_pic)])])
logfilename2 = path.join(log_path, '添加列后.xlsx')
data.to_excel(logfilename2)
# 将nan转为空字符串'',避免显示输出的在word文档中
g = lambda x : x if not pd.isna(x) else ''
# 如果表中不存在下载图片的本地路径,就改为默认空白图片
# f = lambda x : x if not pd.isna(x) else default_pic 不存在可以不设标签值,标签自动转为空白
# 异步多协程下载图片
#asyncio.run(coroutine_multidownload(cfg_pic, data, image_path, default_pic))
#print(data)
# 从带图片的excel中提取图片
# 新的腾讯文档将图片改为附件下载,不直接放到excel中
# extract_pictures(excel_resume_table=resume_table, pd_table=data, image_path=image_path, start_n=start_n, end_n=end_n)
excel_filename,extension = path.splitext(path.basename(resume_table))
logfilename3 = path.join(log_path, f'{excel_filename}_简历列表及下载图片的本地路径.xlsx')
data.to_excel(logfilename3)
for i in range(n1, n2):
context = {}
for j in range(n_cfg_str):
key1 = cfg_str.iloc[:,j].iloc[0]
colname = cfg_str.iloc[:,j].name
value1 = g(data[colname][i])
context[key1] = value1
logging.info(f"简历表文字内容:{key1} {colname} {value1}")
for j in range(n_cfg_date):
key2 = cfg_date.iloc[:,j].iloc[0]
colname = cfg_date.iloc[:,j].name
value2 = g(data[colname][i].split()[0])#strftime("%Y年%m月%d日"))
context[key2] = value2
logging.info(f"简历表日期:{key2} {colname} {value2}")
for j in range(n_cfg_pic):
# 从表中取列,存为series系列
series_t = cfg_pic.iloc[:,j]
# 前两行是图片长度和宽度px值
key_w = series_t.iloc[0]
key_h = series_t.iloc[1]
colname = series_t.name
# 新建模板标签空数组
# jinja2_tag = []
# 简历大表中存储地址的数组
picnames = data[f"{colname}"][i]
print(picnames)
# 遇到没有上传图片的情况,则跳过本次循环,否则picnames.replace()会报错
if pd.isna(picnames):
print(f"第{i+2}行,{colname}列无图片")
continue
# 将excel中的收集结果-Sunday🇨🇳-第26题-2023/05/05 16:56:20.jpeg
# 转为 收集结果-Sunday🇨🇳-第26题-2023-05-05 16-56-20.jpeg
picnames = picnames.replace('/', '-')
picnames = picnames.replace(':', '-')
# 将换行分隔的多个文件名转为数组,像身份证正反面,学历学位证书是多个文界面写在同一个单元格中,需要进行分列处理
pathlist = picnames.split('\n')
print(pathlist)
# c_cfg_pic为配置表行数
for k in range(c_cfg_pic-2):
keyn = series_t.iloc[k+2]
if keyn and not pd.isna(keyn):
# 如果 k 大于 单元格中文件名的数量,说明配置的图片数量大于应聘者实际上传的图片数量,
# 以实际上传的图片数量为准,多余的配置项无图片可插,因此不执行插入命令
if type(pathlist)==list and k < len(pathlist):
# 新版腾讯文档下载的excel表中不包含图片,只包含图片文件名,需要下载附件解压后得到图片
#pic_abspath = path.join(image_path, pathlist[k])
# pathlist[k]中的文件名比实际下载的文件名少后缀,
# 需要从下载图片中查找文件名包含从excel读取的文件名的文件,获取其绝对路径
# 从excel读取的文件名是收集结果-吉盛公司-第27题-2023/07/21 17:03:13.png
# 实际文件名是 收集结果-吉盛公司-第27题-2023-07-21 17-03-13.png..png
pic_abspath = find_files(image_path, pathlist[k])
# 如果有包含文件名的图片,则执行插入命令,没有则不执行
if pic_abspath:
tempfilename = f'{str(int(time.time() * 1000000))}.jpeg'
# 在存放图片的路径下,创建一个临时图片文件夹,用于存放临时图片
temp_folder = path.join(image_path, 'temp_pic')
if not path.exists(temp_folder):
os.makedirs(temp_folder)
temp_abspath = path.join(temp_folder, tempfilename)
# 个人承诺 前面是png透明图片,转换后变成全黑图片,判断如果为个人承诺,直接使用原图 ,个人承诺放在配置表最后一列
if j == n_cfg_pic - 1:
temp_abspath = pic_abspath
else:
# 为了解决原始图片格式不兼容,插入失败问题,非个人承诺签名图片,转换图片格式
Image.open(pic_abspath).convert('RGB').save(temp_abspath, format='JPEG')
context[keyn] = InlineImage(tpl, temp_abspath, width=Mm(key_w),height=Mm(key_h))
logging.info(f"简历表图片的tag标签名称和列名称:{keyn} {colname}")
tpl.render(context)
docx_filename = ''
# 解决生成文件名配置表列数不固定需求
for j in range(n_cfg_filename):
if cfg_filename.iloc[:,j].name == '顺序号':
docx_filename += f'{i+1}_'
elif cfg_filename.iloc[:,j].name == '行号':
docx_filename += f'{i+2}_'
else:
docx_filename += f'{data[cfg_filename.iloc[:,j].name][i]}_'
docx_filename += f'{data[cfg_date.iloc[:,0].name][i].split()[0]}.docx'
'''
df.iloc[:,j].name表示DataFrame df 的第j列的名称
iloc 是一个用于按位置索引选择数据的方法。在这里,df.iloc[:,j]选择了所有行(:)和第j列。
filename1 = data[cfg_filename.iloc[:,0].name][i] # 配置表的第1列 姓名 时间长了配置表修改后肯定会出问题,应该明确写到配置表中
filename2 = data[cfg_filename.iloc[:,1].name][i] # 配置表的第2列 性别
filename3 = data[cfg_filename.iloc[:,2].name][i] # 配置表的第3列
filename4 = data[cfg_date.iloc[:,0].name][i].split()[0]#strftime("%Y年%m月%d日")
docx_filename = f'{i+1}号_第{i+2}行_{filename1}_{filename2}_{filename3}_{filename4}.docx'
'''
#docx_filename = '简历'+str(i+1)+'_'+j+c+n+t+'.docx'
s2 = path.join(docx_path, docx_filename)
tpl.save(s2)
print(f'已导出第{i+1}份简历,文件名:{docx_filename}')
end_time = time.time() # 程序结束时间
run_time = end_time - start_time # 程序的运行时间,单位为秒
print(f"{time.strftime('%X')}导出结束,共导出{total}份简历,用时{round(run_time,2)}秒")
# def start_thread(resume_table, word_template, default_pic, image_path, cfg_table, docx_path):
def start_thread(resume_table, word_template, start_n, end_n, image_path, cfg_table, docx_path, log_path):
#print('开始执行')
# 让格式转换函数在子线程中运行
#thread = threading.Thread(target=xlsx2docx_resume_converter, args=(resume_table, word_template, default_pic, image_path, cfg_table, docx_path))
thread = threading.Thread(target=xlsx2docx_resume_converter, args=(resume_table, word_template, start_n, end_n, image_path, cfg_table, docx_path, log_path))
# 下面是设置守护线程:如果在程序中将子线程设置为守护线程,则该子线程会在主线程结束时自动退出
thread.setDaemon(True)
thread.start() # 启动线程
if __name__ == '__main__':
logdatetime_str = datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
logpath = path.join('log', logdatetime_str)
if not path.exists(logpath):
os.makedirs(logpath)
logfilename = path.join(logpath, '脚本执行日志.log')
logging.basicConfig(filename=logfilename,level=logging.INFO)
# 解决Workbook contains no default style
warnings.filterwarnings('ignore')
#2) 定义布局,确定行数
layout=[[sg.Text('请选择excel简历文件 注意:图片不能重叠')],
[sg.In(key='-XLSX-'),sg.FileBrowse(button_text = '选择文件',target='-XLSX-',file_types = (('All Files','*.xlsx'),)),],
[sg.Text('请选择word模板文件')],
[sg.In(key='-DOCX-'),sg.FileBrowse(button_text = '选择文件',target='-DOCX-',file_types = (('All Files','*.docx'),)),],
[sg.Text('请选择列名配置文件')],
[sg.In(key='-cfgtab-'),sg.FileBrowse(button_text = '选择文件',target='-cfgtab-',file_types = (('All Files','*.xlsx'),)),],
[sg.Text('请选择下载图片路径')],
[sg.In(key='-picPath-'),sg.FolderBrowse(button_text = '选择文件夹',target='-picPath-'),],
[sg.Text('如从第2到第10行有数据填2和10(第1行是列名称),都填0表示导出全部')],
[sg.Text('起始行号:'), sg.InputText("0", key='num1', enable_events=True)],
[sg.Text('结束行号:'), sg.InputText("0", key='num2', enable_events=True)],
[sg.Text('word简历保存路径')],
[sg.In(key='-docxResumePath-'),sg.FolderBrowse(button_text = '选择文件夹',target='-docxResumePath-'),],
[sg.Text('执行过程打印消息:')],
[sg.ML(default_text='',disabled=True,size=(50,6),reroute_stdout=True)],
[sg.Button('确定', key='run'),sg.Button('取消')]]
#3) 创建窗口
window=sg.Window('简历excel转word工具',layout)
# 默认起始行号和结束行号均为0,表示导出全部简历
num1=0
num2=0
#4) 事件循环
while True:
event,values=window.read()#窗口的读取,有两个返回值(1.事件 2.值)
#logger.info("事件:",event,"值:",values)
logging.info(f"windows窗口事件:{event},值:{values}")
if event==None or event == sg.WINDOW_CLOSED or event == '取消':#窗口关闭事件
break
elif event == 'num1' or event == 'num2':
try:
num1 = int(values['num1'])
num2 = int(values['num2'])
if num2 >= num1 >= 0:
window['num1'].update(text_color='black')
window['num2'].update(text_color='black')
window['run'].update(disabled=False)
else:
window['num1'].update(text_color='red')
window['num2'].update(text_color='red')
window['run'].update(disabled=True)
except ValueError:
window['num1'].update(text_color='red')
window['num2'].update(text_color='red')
window['run'].update(disabled=True)
elif event == 'run':
# 用于生成日期时间文件夹
datetime_str = datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
print(f'起始行号:{num1}')
print(f'结束行号:{num2}')
imagepath = values['-picPath-'] # 通过附件形式下载的图片存放的路径
print(f'存放图片的目录为“{path.abspath(imagepath)}”')
logging.info(f'存放图片的目录为“{path.abspath(imagepath)}”')
# 用于存放输出的word文档
docxpath = path.join(values['-docxResumePath-'], datetime_str)
if not path.exists(docxpath):
os.makedirs(docxpath)
print(f'存放word简历的目录为“{path.abspath(docxpath)}”')
logging.info(f'存放word简历的目录为“{path.abspath(docxpath)}”')
#start_thread(values['-XLSX-'], values['-DOCX-'], values['-defaultpic-'], values['-imagepath-'], values['-cfgtab-'], values['-docxResumePath-'])
start_thread(values['-XLSX-'], values['-DOCX-'], num1, num2, imagepath, values['-cfgtab-'], docxpath, logpath)
#5) 关闭窗口
window.close()
logging.info("窗口已关闭")
















 1779
1779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









