









目录
一、创建文件组(可选)
选中数据库实例,右键属性-文件组,在行这里点击【添加文件组】
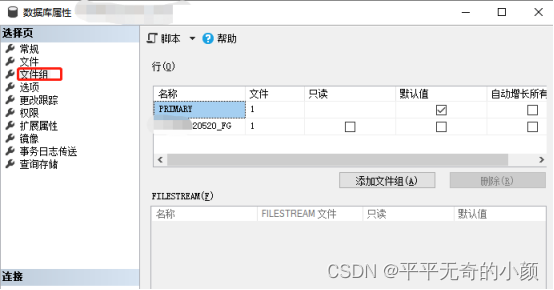
二、为文件组分配数据库文件(可选)
打开>数据库-属性-文件 ,添加一个文件。文件后缀名为.ndf
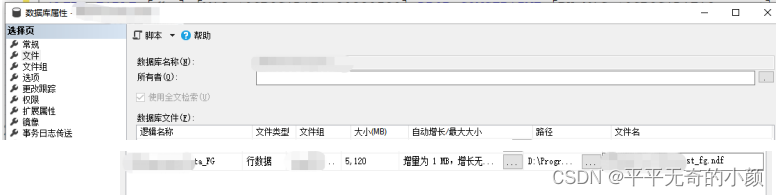
若没有给文件组分配数据库文件,则执行分区脚本时,会报错“没有为文件组 "test20220520_FG" 分配文件”
为什么是.ndf呢?
来看看SQL Server数据库有三种类型的文件
| 文件 | 说明 |
| 主 | 包含数据库的启动信息,并指向数据库中的其他文件。 每个数据库有一个主要数据文件。 主要数据文件的建议文件扩展名是 .mdf。 |
| 辅助副本 | 用户定义的可选数据文件。 通过将每个文件放在不同的磁盘驱动器上, 可以将数据分散到多个磁盘上。 次要数据文件的建议文件扩展名是 .ndf。 |
| 事务日志 | 此日志包含用于恢复数据库的信息。 每个数据库必须至少有一个日志文件。 事务日志的建议文件扩展名是 .ldf。 |
三、使用SQL 分区向导创建分区脚本
1.选择分区列
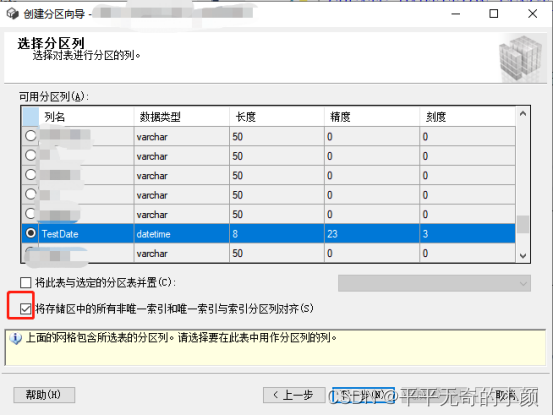
2.新建分区函数名
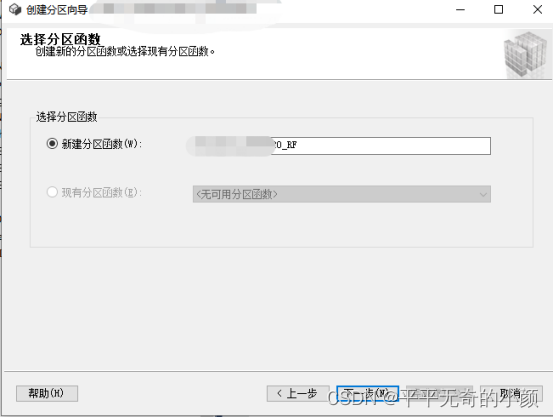
3.新建分区方案名
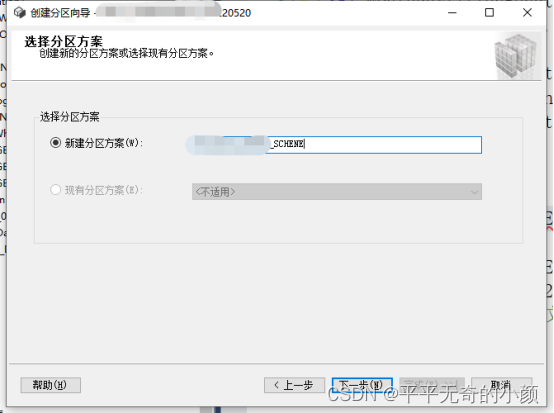
4.设置分区方案
选择范围:右边界
点击【设置边界】,这里日期范围为2020-03-01 ~ 2022-05-20
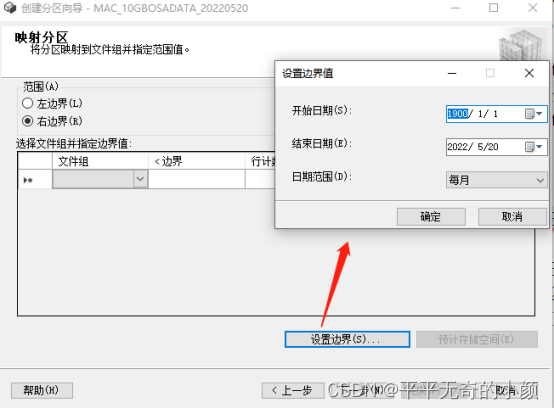
点击确定之后,自动生成边界值
分区映射文件组:点击文件组列的![]() 选择创建的文件组。
选择创建的文件组。
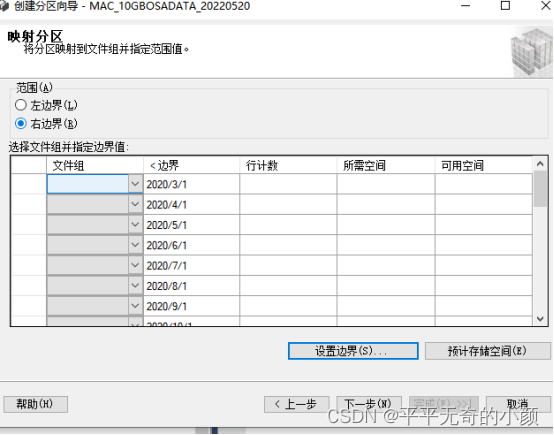
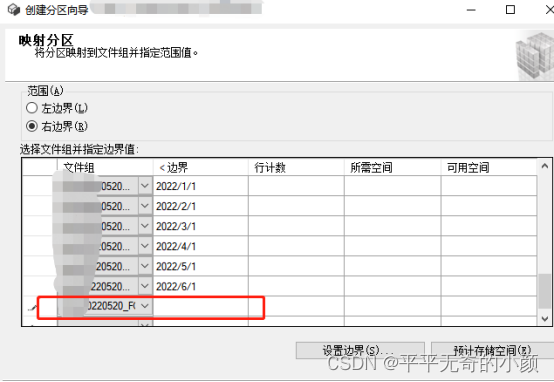
5.选择创建脚本
脚本创建完成
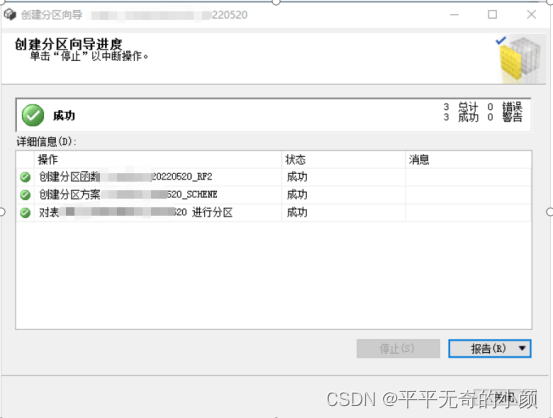
创建的分区脚本如下
USE [test_Data]
GO
--开始事务
BEGIN TRANSACTION
--创建分区函数
CREATE PARTITION FUNCTION [test_20220520_RF](datetime) AS
RANGE RIGHT FOR VALUES (N'2020-03-01T00:00:00', N'2020-04-01T00:00:00', N'2020-05-01T00:00:00', N'2020-06-01T00:00:00', N'2020-07-01T00:00:00', N'2020-08-01T00:00:00', N'2020-09-01T00:00:00', N'2020-10-01T00:00:00', N'2020-11-01T00:00:00', N'2020-12-01T00:00:00', N'2021-01-01T00:00:00', N'2021-02-01T00:00:00', N'2021-03-01T00:00:00', N'2021-04-01T00:00:00', N'2021-05-01T00:00:00', N'2021-06-01T00:00:00', N'2021-07-01T00:00:00', N'2021-08-01T00:00:00', N'2021-09-01T00:00:00', N'2021-10-01T00:00:00', N'2021-11-01T00:00:00', N'2021-12-01T00:00:00', N'2022-01-01T00:00:00', N'2022-02-01T00:00:00', N'2022-03-01T00:00:00', N'2022-04-01T00:00:00', N'2022-05-01T00:00:00', N'2022-06-01T00:00:00')
--创建分区方案
CREATE PARTITION SCHEME [testdata_220520_SCHENE] AS PARTITION [test_20220520_RF] TO ([test20220520_FG], [test20220520_FG], [test20220520_FG], [test20220520_FG], [test20220520_FG], [test20220520_FG], [test20220520_FG], [test20220520_FG], [test20220520_FG], [test20220520_FG], [test20220520_FG], [test20220520_FG], [test20220520_FG], [test20220520_FG], [test20220520_FG], [test20220520_FG], [test20220520_FG], [test20220520_FG], [test20220520_FG], [test20220520_FG], [test20220520_FG], [test20220520_FG], [test20220520_FG], [test20220520_FG], [test20220520_FG], [test20220520_FG], [test20220520_FG], [test20220520_FG], [test20220520_FG])
--删除表的主键
ALTER TABLE [dbo].[tb_test_20220520] DROP CONSTRAINT [PK_MAC_10Gtestdata2_copy1] WITH ( ONLINE = OFF )
--添加主键
ALTER TABLE [dbo].[tb_test_20220520] ADD CONSTRAINT [PK_MAC_10Gtestdata2_copy1] PRIMARY KEY NONCLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
--创建索引
CREATE CLUSTERED INDEX [ClusteredIndex_on_testdata_220520_SCHENE_637979900884802738] ON [dbo].[tb_test_20220520]
(
[TestDate]
)WITH (SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF) ON [testdata_220520_SCHENE]([TestDate])
--删除原索引
DROP INDEX [ClusteredIndex_on_testdata_220520_SCHENE_637979900884802738] ON [dbo].[tb_test_20220520]
--创建非聚集索引 字段:TestDate
CREATE NONCLUSTERED INDEX [index_testdata_220520] ON [dbo].[tb_test_20220520]
(
[TestDate] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = ON, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [testdata_220520_SCHENE]([TestDate])
--事务提交
COMMIT TRANSACTION三、执行脚本
在sql server里在目标数据库里,打开一个【新建查询】窗口,将上述脚本粘贴进去。执行即可。
脚本里会对表的主键和索引重建,所以执行的时间会有点长。
执行时间参考:三四千万的数据,执行大概一个半小时

















 167
167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









