







 该文详细介绍了如何使用albumentations库进行图像增强,包括安装、配置清华源、读取文件路径、标签处理、缓存管理和数据增强方法如Mosaic和MixUp等。同时,文章还提到了数据预处理过程中的各种变换,如旋转、平移、缩放等。
该文详细介绍了如何使用albumentations库进行图像增强,包括安装、配置清华源、读取文件路径、标签处理、缓存管理和数据增强方法如Mosaic和MixUp等。同时,文章还提到了数据预处理过程中的各种变换,如旋转、平移、缩放等。
安装albumentations
配置清华源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install -U albumentations安装不起的问题一般都是网络的问题, 开源地址:
初始化:
文件读取:
try:
f = [] # image files
for p in path if isinstance(path, list) else [path]:
p = Path(p) # os-agnostic
if p.is_dir(): # dir
f += glob.glob(str(p / '**' / '*.*'), recursive=True)
# f = list(p.rglob('*.*')) # pathlib
elif p.is_file(): # file
with open(p) as t:
t = t.read().strip().splitlines()
parent = str(p.parent) + os.sep
f += [x.replace('./', parent, 1) if x.startswith('./') else x for x in t] # to global path
# f += [p.parent / x.lstrip(os.sep) for x in t] # to global path (pathlib)
else:
raise FileNotFoundError(f'{prefix}{p} does not exist')
self.im_files = sorted(x.replace('/', os.sep) for x in f if x.split('.')[-1].lower() in IMG_FORMATS)
# self.img_files = sorted([x for x in f if x.suffix[1:].lower() in IMG_FORMATS]) # pathlib
assert self.im_files, f'{prefix}No images found'
except Exception as e:
raise Exception(f'{prefix}Error loading data from {path}: {e}\n{HELP_URL}') from e测试一下:
if __name__ == '__main__':
path = 'D:\PycharmProjects\opencvtest\datasets\coco\images'
a = LoadImagesAndLabels(path)
next(iter(a))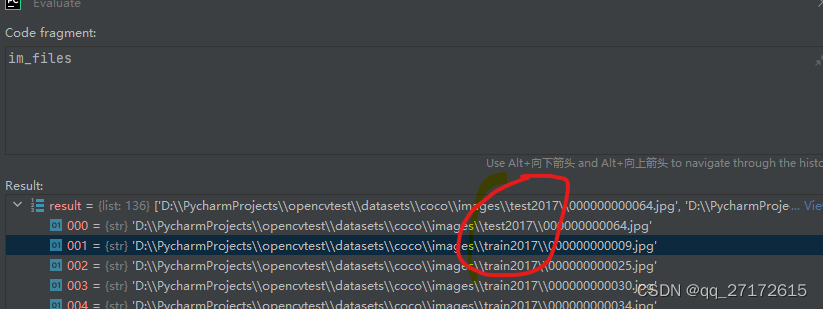
它把根目录的所有地址都读取出来了。关键这句代码
f += glob.glob(str(p / '**' / '*.*'), recursive=True)即使不了解通配符匹配规则,大概也知道是什么意思了。 **表示所有文件名, *.*表示所有文件名。p 传入的根目录
缓存cahe
# Check cache
self.label_files = img2label_paths(self.im_files) # labels
cache_path = (p if p.is_file() else Path(self.label_files[0]).parent).with_suffix('.cache')
try:
cache, exists = np.load(cache_path, allow_pickle=True).item(), True # load dict
assert cache['version'] == self.cache_version # matches current version
assert cache['hash'] == get_hash(self.label_files + self.im_files) # identical hash
except Exception:
cache, exists = self.cache_labels(cache_path, prefix), False # run cache ops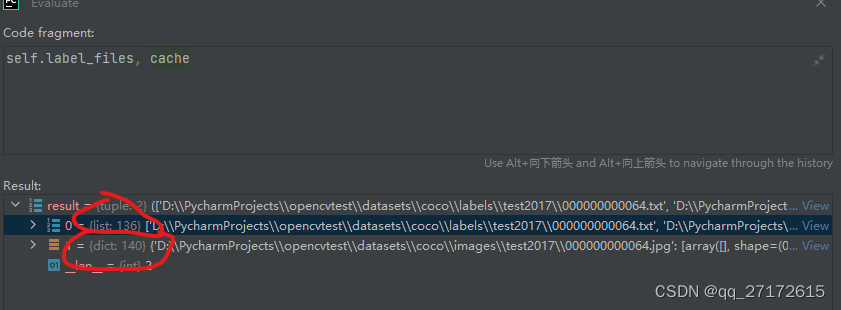
发现了 结果不一样, 先不管看这个方法
def img2label_paths(img_paths):
# Define label paths as a function of image paths
sa, sb = f'{os.sep}images{os.sep}', f'{os.sep}labels{os.sep}' # /images/, /labels/ substrings
return [sb.join(x.rsplit(sa, 1)).rsplit('.', 1)[0] + '.txt 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









