






一、CountDownLatch,Semaphore的高频问题:
1.1 CountDownLatch是啥?有啥用?底层咋实现的?
CountDownLatch 本质上是一个计数器,用于协调多个线程之间的同步。主要应用场景是在多线程并行处理业务时,需要等待其他线程处理完再进行后续操作,例如合并结果或响应用户请求。
用法:
- 在主线程中创建一个 CountDownLatch 对象,指定计数器的初始值。
- 每个子线程在处理完任务后,调用
countDown方法将计数器减1。 - 主线程调用
await方法,等待计数器归零后继续执行。
底层实现:
- 基于 AQS(AbstractQueuedSynchronizer)实现。
- 创建 CountDownLatch 时,指定的数值会赋值给 state 属性。
- 子线程调用
countDown方法时,state 减1。 - 当 state 归零时,调用
await方法挂起的线程会被唤醒。
注意:CountDownLatch 不能重复使用,用完即销毁。
1.2 Semaphore是啥?有啥用?底层咋实现的?
Semaphore 是一种信号量,用于控制同时访问某个特定资源的线程数量,常用于限流。
用法:
- 在 Hystrix 中用于信号量隔离,限制并发线程数。
- 创建 Semaphore 对象时,指定信号量的数量。
- 每个任务提交时,获取一个信号量;任务完成后,归还信号量。
底层实现:
- 基于 AQS 实现。
- 构建信号量时,指定信号量的资源数。
- 获取信号量时,通过 CAS 保证原子性。
- 归还信号量时,也通过类似的机制保证线程安全。
1.3 main线程结束,程序会停止吗?
- 如果 main 线程结束后,仍有用户线程在执行,程序不会结束。
- 如果 main 线程结束后,剩下的线程都是守护线程,程序会结束。
二、CopyOnWriteArrayList的高频问题:
2.1 CopyOnWriteArrayList是如何保证线程安全的?有什么缺点吗?
线程安全性:
- 写操作时,通过 ReentrantLock 保证原子性。
- 写操作会复制一个副本,写入成功后再更新到 CopyOnWriteArrayList 的数组中。
- 读操作不会出现数据不一致问题,因为读的是快照。
缺点:
- 写操作时需要复制副本,如果数据量大,空间占用和写入时间成本较高。
- 不适合写操作频繁且数据量大的场景。
三、ConcurrentHashMap(JDK1.8)的高频问题:
3.1 HashMap为啥线程不安全?
- 在 JDK1.7 中可能出现环(扩容时)。
- 数据可能会覆盖和丢失。
- 计数器操作(如
++)不安全,导致记录不准确。 - 数据迁移和扩容可能导致数据丢失。
3.2 ConcurrentHashMap如何保证线程安全的?
- 尾插和扩容时通过 CAS 保证线程安全。
- 写入数组时通过 CAS 保证安全,挂入链表或插入红黑树时通过 synchronized 保证安全。
- 计数器采用 LongAdder 实现,底层使用 CAS。
- 扩容时通过 CAS 保证数据迁移不出现并发问题,并支持并发扩容。
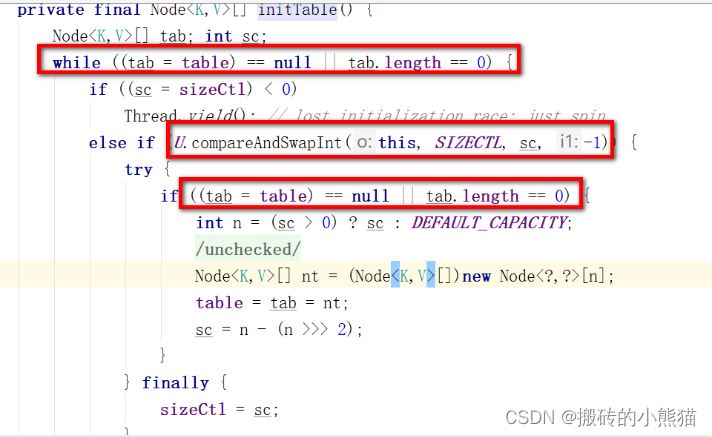
3.3 ConcurrentHashMap构建好,数组就创建出来了吗?如果不是,如何保证初始化数组的线程安全?
- ConcurrentHashMap 是懒加载机制,大多数框架组件都是懒加载的。
- 通过 CAS 修改 sizeCtl 变量保证初始化线程安全,同时使用双重检查锁定(DCL)技术,外层判断数组未初始化,内层再检查一次。
3.4 为什么负载因子是0.75,为什么链表长度到8转为红黑树?
负载因子:
- 0.75 是一个平衡选择,兼顾了空间利用率和哈希冲突率。
- 0.5:扩容太频繁,空间利用率低。
- 1:哈希冲突频繁,查询效率低。
链表转红黑树:
- 根据泊松分布,链表长度达到8的概率非常低,保持查询效率。
- 红黑树写入成本高,尽量规避使用。
3.5 ConcurrentHashMap何时扩容,扩容的流程是什么?
扩容时机:
- 元素个数达到负载因子计算的阈值。
- 调用
putAll方法时,如果插入的数据大于下次扩容的阈值。 - 数组长度小于64,且链表长度大于等于8时。

扩容流程:
- 每个扩容线程计算一个扩容标识戳。
- 第一个扩容线程对 sizeCtl + 2,表示一个线程在扩容。
- 其他扩容线程对 sizeCtl + 1,表示多个线程帮助扩容。
- 第一个线程初始化新数组。
- 每个线程领取迁移数据任务,每次长度为16。
- 数据迁移完毕后,线程退出扩容,对 sizeCtl - 1。
- 最后一个退出扩容的线程检查遗留数据,再 - 1,扩容结束。
3.6 ConcurrentHashMap得计数器如何实现的?
- 基于 LongAdder 的机制实现,但没有直接使用 LongAdder,而是采用类似 LongAdder 的原理实现。
- LongAdder 使用 CAS 添加,保证原子性,同时基于分段锁保证并发性。
3.7 ConcurrentHashMap的读操作会阻塞吗?
- 读操作不会阻塞。
- 读数组:直接返回。
- 读链表:遍历链表查询。
- 扩容时:如果当前索引位置数据已迁移到新数组,直接查询新数组。
- 读红黑树:转换红黑树时,保留一个双向链表,读操作查询链表。通过 TreeBin 的 lockState 判断是否有线程在写操作。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











