




 本文详细解析了MapReduce的执行流程,包括map和reduce进程的工作原理,shuffle过程以及三次排序的实现方式。深入理解MapReduce如何处理大规模数据集,提高大数据处理效率。
本文详细解析了MapReduce的执行流程,包括map和reduce进程的工作原理,shuffle过程以及三次排序的实现方式。深入理解MapReduce如何处理大规模数据集,提高大数据处理效率。
MapReduce的执行流程
 MapReduce执行流程分为map进程和reduce进程两部分,对应上图中左右两部分
MapReduce执行流程分为map进程和reduce进程两部分,对应上图中左右两部分
map部分:
1、stdin(input的是标准输入流,传入的是一整块的数据块,hadoop2.x中HDFS block的大小默认128M,hadoop1.x为64M)数据进来的时候会split切分成一条一条记录的形式,经过map函数操作(如wordCount),输出后的数据进入到内存缓存区中(默认100M,由io.sort.mb属性控制),当写满此内存区的80%(由io.sort.spill.percent属性控制)后,便会整块数据spill溢写到磁盘上,此时流程并不会中止,而是剩下的20%内存供其他数据继续存入。
2、溢写到磁盘上的数据,都经过了partition和sort的操作,单词根据hash的方式进行了分区,相同的单词进入同一个分区,分区后按照单词进行排序。如果此时设置了Combiner(mapred.compress.map.out设置为true),将排序后的结果进行Combianer操作,这样做的目的是让尽可能少的数据写入到磁盘。
3、程序结束后,会进行数据合并(merge on disk)操作,将所有的数据按照分区进行合并,之后会根据分区发送到对应的reduce上(分区的数量是由reduce的数量来决定的,这样保证了reduce上的数据都是同一个分区)。
reduce部分:
1、map进程全部都执行完之后,reduce会有个内存缓存区来接收各个reduce节点传过来的数据,数据块会进行merge操作
2、merge有三种形式:1、内存到内存;2、内存到磁盘;3、磁盘到磁盘。默认情况下第一种形式不启用,让人比较困惑。当内存中的数据量到达一定阈值,就启动内存到磁盘的merge。与map端类似,这也是溢写的过程,在这个过程中如果你设置有Combiner,也是会启用的,然后在磁盘中生成了众多溢写文件。第二种merge方式一直在运行,直到没有map端的数据时才结束,然后启动第三种磁盘到磁盘的merge方式生成最终的那个文件。
3、当Reducer的输入文件已定,整个Shuffle才最终结束,最后reduce函数进行操作及输出到HDFS中(一个reduce输出一个数据文件)。
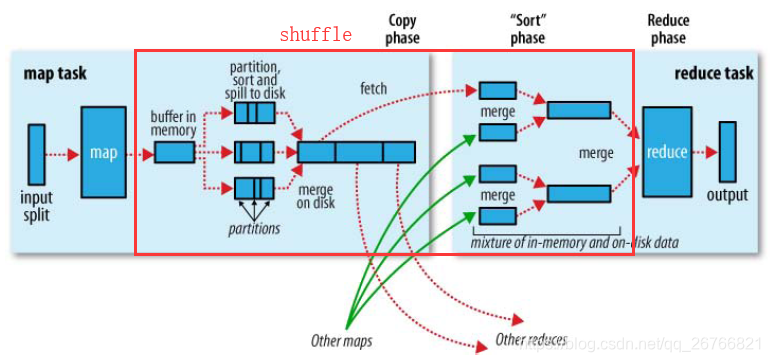 shuffle过程:
shuffle过程:
shuffle过程为图中红线部分,是整个MR过程中最耗性能的部分,数据在不同节点中的传输涉及到网络io和磁盘io,同一个节点的话只进行了磁盘io。
以上MapReduce流程中一共有三次排序,第一次是在环形溢写到缓冲区中进行快速排序,当达到默认阈值80M时写到spill到磁盘,第二次是在多个spill的文件进行merge过程中排序,第三次是在reduce fetch多个map产生的多个merge文件时做一次sort,整个过程中第一次是快速排序因为在内存中,第二和第三次为归并排序。

















 2027
2027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









