







 本文探讨了UTF-8编码验证的两种方法:模拟遍历与位运算遍历。通过Java和Python实现,介绍了如何判断一组整数是否构成有效的UTF-8编码。
本文探讨了UTF-8编码验证的两种方法:模拟遍历与位运算遍历。通过Java和Python实现,介绍了如何判断一组整数是否构成有效的UTF-8编码。
UTF-8 编码验证的思路探讨与源码
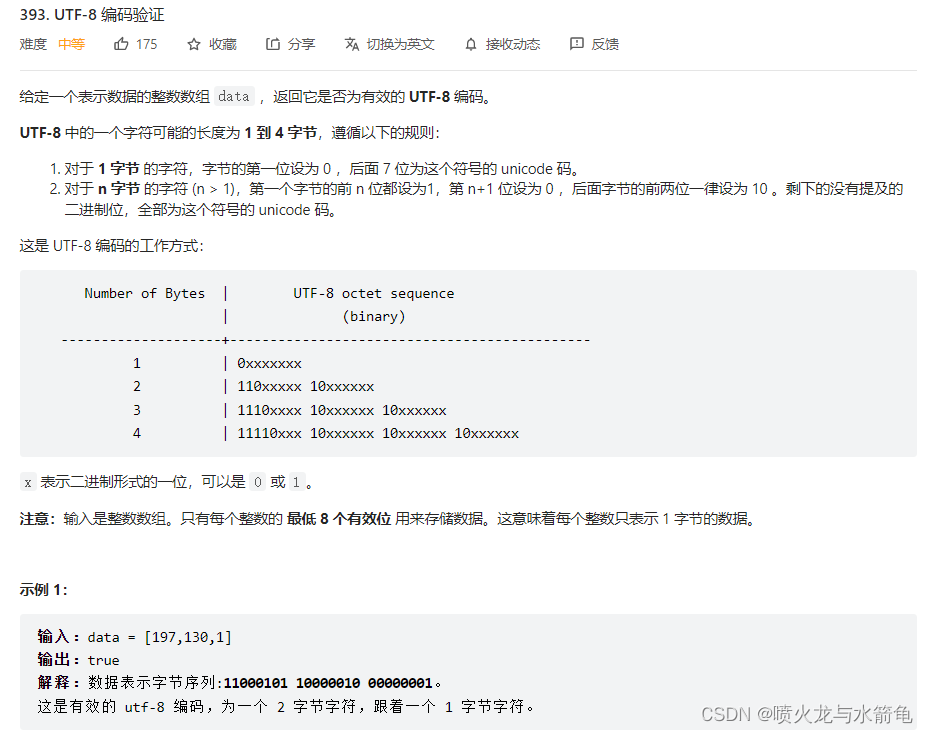
UTF-8 编码验证的题目如下图,该题属于位运算类和数组类型的题目,主要考察对于位运算方法的使用和数组结构的理解。本文的题目作者想到2种方法,分别是模拟遍历方法和位运算遍历方法,其中模拟遍历方法使用Java进行编写,而位运算遍历方法使用Python进行编写,当然这可能不是最优的解法,还希望各位大佬给出更快的算法。
本人认为该题目可以使用模拟遍历方法的思路进行解决,首先计算数组长度,开始遍历,将当前元素的数字记录,然后对从第 7 位开始往后有多少位连续的 1就代表这是一个几字节的字符,并记录该数字,如果该数字为1或者大于4就均违反编码规则,返回False结果;而如果位置 后面不满足条件也返回False,否则检查指定下标范围的数是否满足前两位为10的要求,若不满足返回False结果。直到最终遍历结束并返回判定结果。那么按照这个思路我们的Java代码如下:
#喷火龙与水箭龟
class Solution {
public boolean validUtf8(int[] data) {
int dataLen = data.length;
for (int ir = 0; ir < dataLen;) {
int tes = data[ir];
int jr = 7;
while (jr >= 0 && (((tes >> jr) & 1) == 1)){
jr = jr - 1;
}
int countNum = 7 - jr;
if (countNum == 1 || countNum > 4){
return false;
}
if (ir + countNum - 1 >= dataLen){
return false;
}
for (int kr = ir + 1; kr < ir + countNum; kr++) {
if ((((data[kr] >> 7) & 1) == 1) && (((data[kr] >> 6) & 1) == 0)){
continue;
}
return false;
}
if (countNum == 0){
ir = ir + 1;
}else{
ir = ir + countNum;
}
}
return true;
}
}

显然,我们的模拟遍历方法的效果还不错,还可以使用位运算遍历的方法解决。首先设计两个掩码,定义一个获取字节的函数,在函数内部,首先判断头字节和MASK1的按位与运算结果是否为0,如果为0则当前字符由1个字节组成。如果不为0则创建位掩码MASK并将初始值设为MASK1。然后再初始化参数并计算数组长度,并开始遍历数组,对满足逻辑条件的就返回False的结果,否则就继续搜索,直到遍历结束并返回最终的结果。所以按照这个思路就可以解决,下面是Python代码:
#喷火龙与水箭龟
class Solution:
def validUtf8(self, data: List[int]) -> bool:
MASK1 = 1 << 7
MASK2 = (1 << 7) | (1 << 6)
def getBytes(num: int) -> int:
if (num & MASK1) == 0:
return 1
res = 0
mask = MASK1
while num & mask:
res = res + 1
if res > 4:
return -1
mask >>= 1
if res>=2:
return res
else:
return -1
ind = 0
m = len(data)
while ind < m:
n = getBytes(data[ind])
if n < 0 or ind + n > m or any((ch & MASK2) != MASK1 for ch in data[ind + 1: ind + n]):
return False
ind = ind +n
return True

从结果来说Java版本模拟遍历方法的效率还可以,而Python版本的位运算遍历方法的速度也还不错,但应该是有更多的方法可以进一步提速的,希望朋友们能够多多指教,非常感谢。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









