







 该研究提出了一个融合RGB和热成像信息的大规模RGBT人群数据集,包含2030对图像和138389个人头注释。为了解决多模态人群计数问题,他们设计了一个跨模态协作表示学习框架,通过信息聚合-分布模块(IADM)动态捕捉模态间的互补性。实验表明,这种方法在RGBT-CC和ShanghaiTechRGBD数据集上表现出色,证明了多模态信息的有效性。
该研究提出了一个融合RGB和热成像信息的大规模RGBT人群数据集,包含2030对图像和138389个人头注释。为了解决多模态人群计数问题,他们设计了一个跨模态协作表示学习框架,通过信息聚合-分布模块(IADM)动态捕捉模态间的互补性。实验表明,这种方法在RGBT-CC和ShanghaiTechRGBD数据集上表现出色,证明了多模态信息的有效性。
Cross-Modal Collaborative Representation Learning and a Large-Scale RGBT Benchmark for Crowd Counting
一、动机:大多数以前的方法仅利用RGB图像的有限信息,并且可能无法在不受限制的环境中发现潜在的行人。在这项工作中,我们发现合并光学和热学信息可以极大地帮助识别行人。
二、解决方法:合并图像光学信息(RGB)和热力学信息(T)帮助识别行人。
贡献:
1、提出一个大规模RGBT人群数据集,包含2030对RGB-Thermal图像,共138389个人头注释;
2、一个跨模式的协作表示学习框架,该框架能够使用所设计的信息聚合分发模块来全面学习不同模态之间的互补性;
3、在RGBT-CC和ShanghaiTechRGBD上进行的大量实验表明,该方法对于多模态人群计数是有效且通用的。

常规的多模态学习方法大多是单向信息传递,通常将多模态数据的组合嵌入深度神经网络或者直接融合其特征,无法很好地利用补充信息;
为了促进多模态人群计数,提出了一种跨模态的协作表示学习框架,采用动态增强机制充分利用模态互补性;
该框架包含三部分:多个特定于模态的分支,一个模态共享的分支,一个信息聚合-分布模块(IADM)组成,以完全捕获不同模态的互补信息;
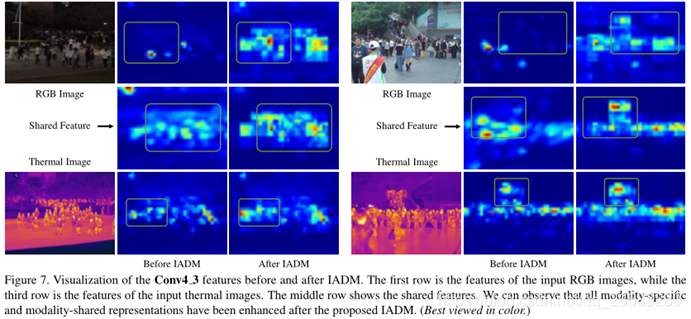
IADM包括(1)信息聚合转移,它动态地聚合所有特定于模态的特征的上下文信息,以增强模态共享的特征;以及(2)信息分发转移,其传播模态共享的信息,以对称地细化每个特定于模态的特征,以供进一步的表示学习。
三、具体方法
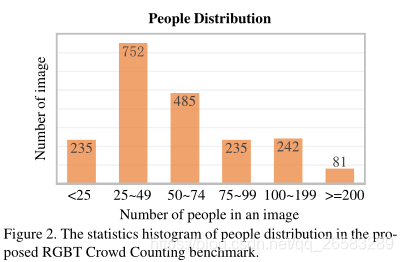
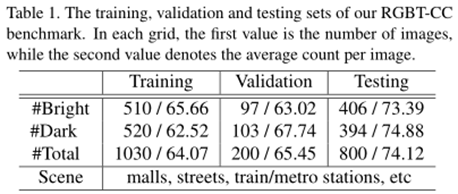
3.1 RGBT数据集
RGBT-CC数据集包括2,030对具有代表性的RGBT图像,分辨率640x480;
其中1013对处于明亮环境,1017对处于黑暗环境;
共有138389个人头注释,平均每场图片包含68个人头;
训练集1030对,验证集200对,测试集800对。
3.2 跨模态协同表征学习框架
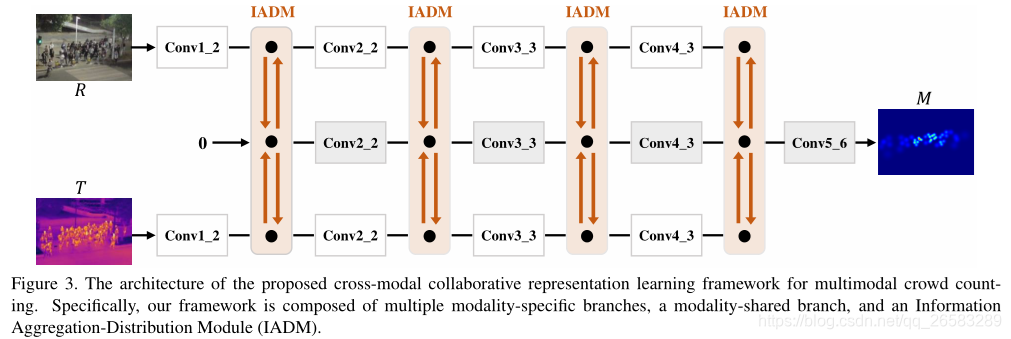
顶部和底部主干是特定模态分支(即RGB图像和热图像);
中间主干是为模态共享分支;
IADM动态传输特定共享的信息,以协作增强特定模态分支和共享模态分支的表达;
最终的模态共享分支特征包含全面的信息,并有助于生成高质量的人群密度图。
具体实现:
1、 输入RGB图像和热图像至各自的特定模态分支;
2、0张量作为模态共享分支的输入,并逐层聚合两个特定模态分支的特征信息;
3、所有分支基于CSRNet实现,其中,两个特定模态分支(Top和bottom)由CSR前端组成(即VGG16前10层),一个模态共享分支(Middle)由CSR最后14层组成(即VGG16前2-10层+后端6个空洞卷积)
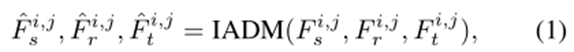

3.3 信息聚合-分发模块(IADM)
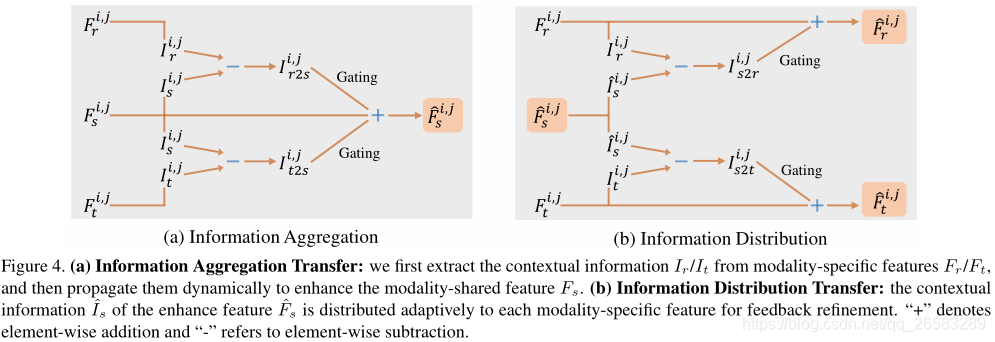
图中聚合-分发机制中传播的是上下文信息而不是原始特征,因为后面的方式会导致特定共享特征的过度混合。
IADM包括三部分:
1、Contextual Information Extraction;
2、Information Aggregation Transfer (IAT);
3、Information Distribution Transfer (IDT);



四、实验结果
4.1 评价指标
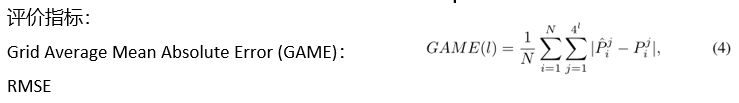
4.2 消融实验
4.2.1 1.多模态数据的有效性/2.多模态数据融合方式的有效性
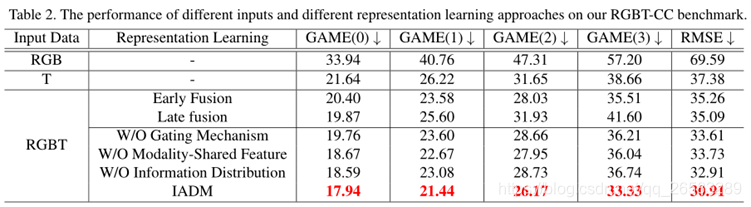
6中多模态数据学习方式:
(1)Early Fushion:将RGB和热图像Concat作为输入;
(2)Late Fushion:分别提取RGB和热力图特征,Concat特征以生成密度图;
(3)W/O Gating Mechanism:
(4)W/O Modality-Shared Feature:
(5)W/OModality-Shared Feature
(6)W/O Information Distribution
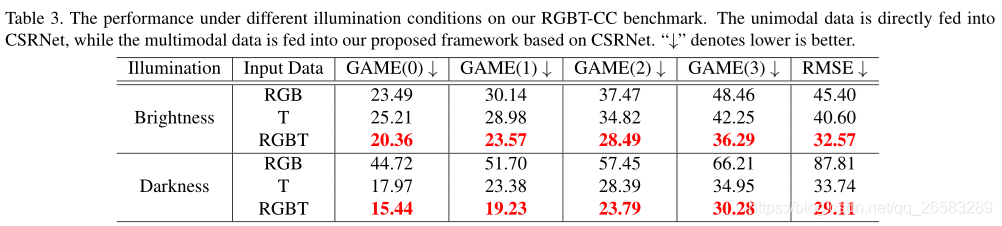
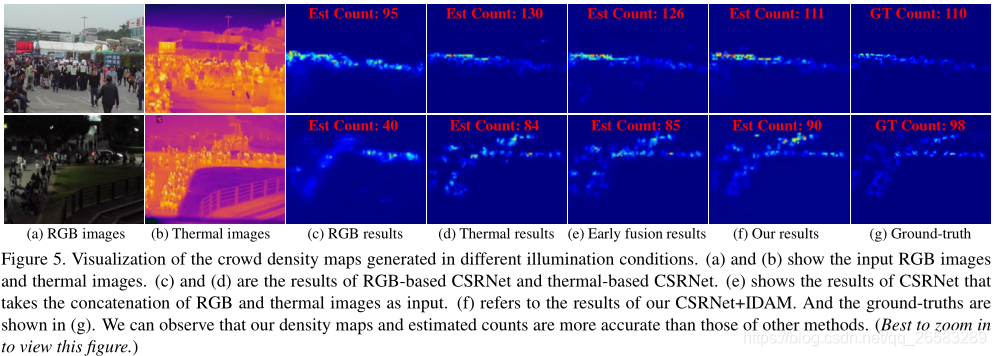
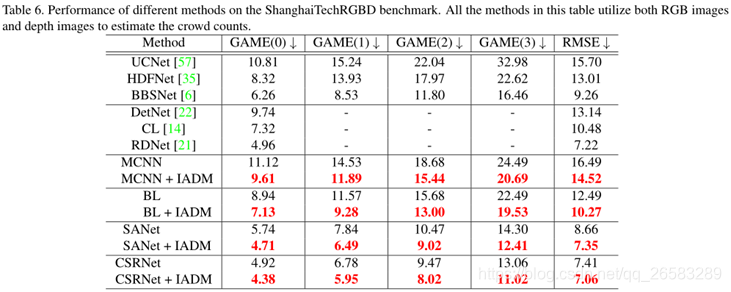
实验得出,热力图信息极大地有助于将潜在的行人与混乱的背景区分开,而光学信息则有助于消除热图像中的负热物体。
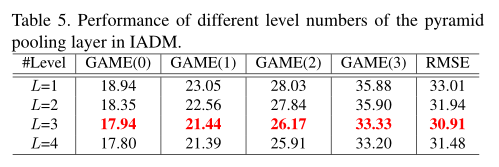
4.2.2 3.L级金字塔池化的有效性
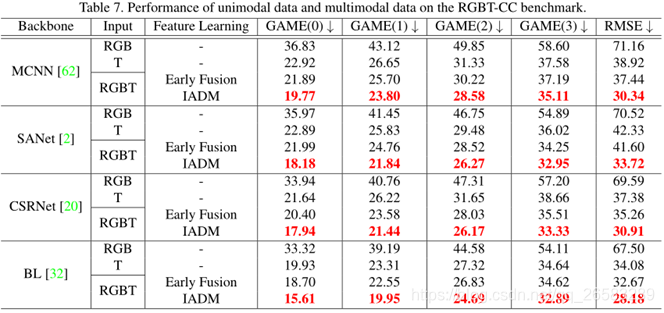
4.2.4 4.与早期方法相比
1、对于MCNN/SANet/BL 采用concat RGB图像和热力图方式作为输入;
2、对于多模态模型DetNet/CL/RDNet, RGB图和热力图分别作为输入;
3、将MCNN/SANet/BL作为IADM的Backbone;
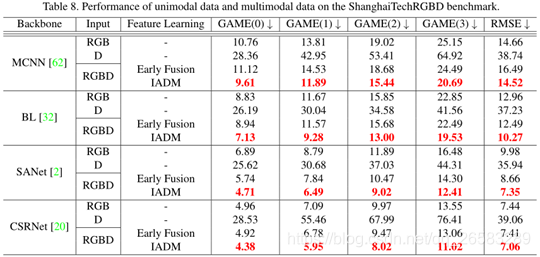
4.2.5 5.在ShanghaiTechRGBD数据集上有效性



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









