







1.什么是聚合函数
聚合函数是hive内置函数,聚合函数对一组值执行计算,并返回单个值。 在Hive的聚合中,如果某个聚合列的值中有null,则包含该null的行将在聚合时被忽略除,了 COUNT 函数以外。为了避免这种情况,可以使用COALESCE来将null替换为一个默认值。 聚合函数经常与 SELECT 语句的 GROUP BY 子句一起使用。换句话说使用聚合函数时,一个列字段要不在group by里,要不必须在聚合函数里面,否则报错。
hive中所有的内嵌函数:Hive所有内嵌函数wiki
下面是hive中自带的内置聚合函数列表,蓝色为常用:
| 返回类型 | 函数名 | 描述 |
| BIGINT | count(*) count(expr) count(DISTINCT expr[, expr_.]) | count(*) – 返回检索到的行的总数,包括含有NULL值的行。count(expr) – 返回expr表达式不是NULL的行的数量count(DISTINCT expr[, expr]) – 返回expr是唯一的且非NULL的行的数量 |
| DOUBLE | sum(col) sum(DISTINCT col) | 对组内某列求和(包含重复值)或者对组内某列求和(不包含重复值) |
| DOUBLE | avg(col), avg(DISTINCT col) | 对组内某列元素求平均值者(包含重复值或不包含重复值) |
| DOUBLE | min(col) | 返回组内某列的最小值 |
| DOUBLE | max(col) | 返回组内某列的最大值 |
| DOUBLE | variance(col), var_pop(col) | 返回组内某个数字列的方差 |
| DOUBLE | var_samp(col) | 返回组内某个数字列的无偏样本方差 |
| DOUBLE | stddev_pop(col) | 返回组内某个数字列的标准差 |
| DOUBLE | stddev_samp(col) | 返回组内某个数字列的无偏样本标准差 |
| DOUBLE | covar_pop(col1, col2) | 返回组内两个数字列的总体协方差 |
| DOUBLE | covar_samp(col1, col2) | 返回组内两个数字列的样本协方差 |
| DOUBLE | corr(col1, col2) | 返回组内两个数字列的皮尔逊相关系数 |
| DOUBLE | percentile(BIGINT col, p) | 返回组内某个列精确的第p位百分数,p必须在0和1之间 |
| array<double> | percentile(BIGINT col, array(p1 [, p2]...)) | 返回组内某个列精确的第p1,p2,……位百分数,p必须在0和1之间 |
| DOUBLE | percentile_approx(DOUBLE col, p [, B]) | 返回组内数字列近似的第p位百分数(包括浮点数),参数B控制近似的精确度,B值越大,近似度越高,默认值为10000。当列中非重复值的数量小于B时,返回精确的百分数 |
| array<double> | percentile_approx(DOUBLE col, array(p1 [, p2]...) [, B]) | 同上,但接受并返回百分数数组 |
| array<struct {'x','y'}> | histogram_numeric(col, b) | 使用b个非均匀间隔的箱子计算组内数字列的柱状图(直方图),输出的数组大小为b,double类型的(x,y)表示直方图的中心和高度 |
| array | collect_set(col) 超常用 一般配合concat_ws使用 | 返回消除了重复元素的数组,去重 |
| array | collect_list(col) 超常用 一般配合concat_ws使用 | 返回允许重复元素的数组,不去重 |
| INTEGER | ntile(INTEGER x) | 该函数将已经排序的分区分到x个桶中,并为每行分配一个桶号。这可以容易的计算三分位,四分位,十分位,百分位和其它通用的概要统计 |
2.常用聚合函数使用演示
1. 个数统计函数: count
语法: count(*), count(expr), count(DISTINCT expr[, expr_.])
返回值: int
说明: count(*)统计检索出的行的个数,包括NULL值的行;count(expr)返回指定字段的非空值的个数;count(DISTINCTexpr[, expr_.])返回指定字段的不同的非空值的个数
举例:
hive> select count(*) from lxw_dual;
20
hive> select count(distinct t) fromlxw_dual;
10
2. 总和统计函数: sum
语法: sum(col), sum(DISTINCT col)
返回值: double
说明: sum(col)统计结果集中col的相加的结果;sum(DISTINCT col)统计结果中col不同值相加的结果
举例:
hive> select sum(t) from lxw_dual;
100
hive> select sum(distinct t) fromlxw_dual;
70
3. 平均值统计函数: avg
语法: avg(col), avg(DISTINCT col)
返回值: double
说明: avg(col)统计结果集中col的平均值;avg(DISTINCT col)统计结果中col不同值相加的平均值
举例:
hive> select avg(t) from lxw_dual;
50
hive> select avg (distinct t) fromlxw_dual;
30
4. 最小值统计函数: min
语法: min(col)
返回值: double
说明: 统计结果集中col字段的最小值
举例:
hive> select min(t) from lxw_dual;
20
5. 最大值统计函数: max
语法: max(col)
返回值: double
说明: 统计结果集中col字段的最大值
举例:
hive> select max(t) from lxw_dual;
120
6.非空集合总体变量函数: var_pop
语法: var_pop(col)
返回值: double
说明: 统计结果集中col非空集合的总体变量(忽略null
3.聚合函数使用注意事项
1.聚合条件--HAVING,从Hive0.7.0开始HAVING被添加到Hive作为GROUP BY结果集的条件过滤。HAVING可以作为子句的替代。
hive> SELECT sex_age.age FROM employee GROUP BY sex_age.age HAVING count(*) >=1;2.聚合函数经常与 SELECT 语句的 GROUP BY 子句一起使用。换句话说使用聚合函数时,一个列字段要不在group by里,要不必须在聚合函数里面,不能单独出现,否则报错。
1.只有聚合函数,没有group by ,没问题
hive (default)> select sum(a),count(distinct b) from fdm_sor.tmp_aaaaa;
OK
2 1
2.有聚合函数,又有别的列c,但是没有用group by,报错
hive (default)> select sum(a),count(distinct b) ,c from fdm_sor.tmp_aaaaa;
FAILED: SemanticException [Error 10025]: Line 1:33 Expression not in GROUP BY key 'c'
3.聚合函数配合group by 一起使用
select sum(a),count(distinct b) , c from fdm_sor.tmp_aaaaa group by c;
OK
2 1 2019-05-22 21:23:34
3.常用的collect_list与collect_set的使用,区别就是前者不去重,后者去重
collect_list,与collect_set的使用,这个使用好处就是可以轻松明白group by的原理,因为collect_list这个函数可以将分组后不可见的其他字段的情况以数组的形式展示出来,比如这里用filter_name分组,通过collect_list函数可以清晰地看到每个filter_Name组里的path_id的情况,并对些组里的字段进行统计分析
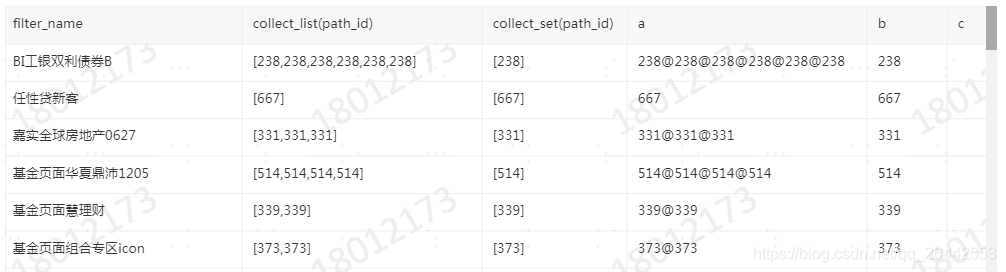
3.1演示1
select filter_name ,
collect_list(path_id),
collect_set(path_id),
concat_ws('@',collect_list(path_id)) a,
concat_ws('@',collect_set(path_id)) b,
concat_ws('@',collect_set(market_type)) c
from FDM_SOR.T_FIBA_MULTI_UBA_CFG_PATH_DETAIL_D
where path_id >89
group by filter_name 结果如下:
3.2 演示2对分组进行计算
select filter_name ,
collect_list(path_id),
collect_set(path_id),
concat_ws('@',collect_list(path_id)) a,
concat_ws('@',collect_set(path_id)) b,
concat_ws('@',collect_set(market_type)) c
from FDM_SOR.T_FIBA_MULTI_UBA_CFG_PATH_DETAIL_D
where path_id >89
group by filter_name
having count(path_id)>3 --按filter_name分组,且要求每个分组里的path_id的个数大于3个。
---having是对分组后每组进行统计的。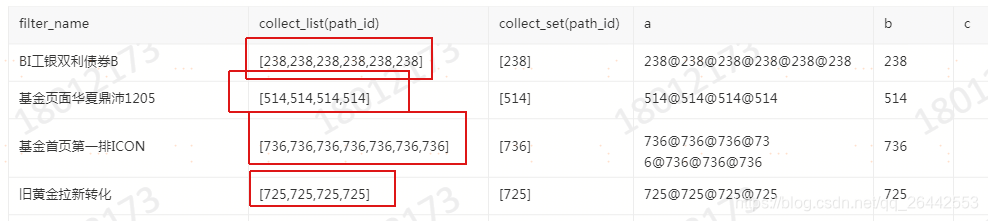


















 1287
1287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











