







目录
Hadoo基础概念
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。
HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
Hadoop解决哪些问题?
-
海量数据需要及时分析和处理
-
海量数据需要深入分析和挖掘
-
数据需要长期保存
海量数据存储的问题:
-
磁盘IO称为一种瓶颈,而非CPU资源
-
网络带宽是一种稀缺资源
-
硬件故障成为影响稳定的一大因素
Hadoop 相关技术
Hbase
- Nosql数据库,Key-Value存储
- 最大化利用内存
HDFS
- hadoop distribute file system(分布式文件系统)
- 最大化利用磁盘
MapReduce
- 编程模型,主要用来做数据分析
- 最大化利用CPU
集中式系统
集中式系统用一句话概括就是:一个主机带多个终端。终端没有数据处理能力,仅负责数据的录入和输出。而运算、存储等全部在主机上进行。现在的银行系统,大部分都是这种集中式的系统,此外,在大型企业、科研单位、军队、政府等也有分布。集中式系统,主要流行于上个世纪。
集中式系统的最大的特点就是部署结构非常简单,底层一般采用从IBM、HP等厂商购买到的昂贵的大型主机。因此无需考虑如何对服务进行多节点的部署,也就不用考虑各节点之间的分布式协作问题。但是,由于采用单机部署。很可能带来系统大而复杂、难于维护、发生单点故障(单个点发生故障的时候会波及到整个系统或者网络,从而导致整个系统或者网络的瘫痪)、扩展性差等问题。
分布式系统(distributed system)
一群独立计算机集合共同对外提供服务,但是对于系统的用户来说,就像是一台计算机在提供服务一样。分布式意味着可以采用更多的普通计算机(相对于昂贵的大型机)组成分布式集群对外提供服务。计算机越多,则CPU、内存、存储资源等也就越多,能够处理的并发访问量也就越大。
一个标准的分布式系统应该具有以下几个主要特征:
- 分布性
分布式系统中的多台计算机之间在空间位置上可以随意分布,系统中的多台计算机之间没有主、从之分,即没有控制整个系统的主机,也没有受控的从机。
- 透明性
系统资源被所有计算机共享。每台计算机的用户不仅可以使用本机的资源,还可以使用本分布式系统中其他计算机的资源(包括CPU、文件、打印机等)。
- 同一性
系统中的若干台计算机可以互相协作来完成一个共同的任务,或者说一个程序可以分布在几台计算机上并行地运行。
- 通信性
系统中任意两台计算机都可以通过通信来交换信息。
分布式数据和存储
大型网站常常需要处理海量数据,单台计算机往往无法提供足够的内存空间,可以对这些数据进行分布式存储。
分布式计算
随着计算技术的发展,有些应用需要非常巨大的计算能力才能完成,如果采用集中式的单机大机器的计算,需要耗费相当长的时间来完成。分布式计算将该应用分解成许多小的部分,分配给多台计算机进行处理。这样可以节约整体计算时间,大大提高计算效率。
关系型数据库, MapReduce (大规模数据批量分析)
数据访问效率
磁盘寻址时间提高速度远远小于数据传输速率提高速度(寻址是将磁头移动到特定硬盘位置进行读写操作,这是导致硬盘操作延迟的主要原因,而传输速率取决于硬盘的带宽)。对于超大规模数据(以PB为单位)必须考虑使用其他方式。关系型数据库使用B树结构进行数据的更新查询操作,对于最大到GB的数据量,一般相对数据量较小,效果很好。但是大数据量时,B树使用排序/合并方式重建数据库以更新数据的效率远远低于MapReduce。
数据结构不同
- 结构化数据
(structured data):是具体既定格式的实体化数据,如XML文档或满足特定预定义格式的数据库表。这是RDBMS包括的内容。
半结构化数据
- 半结构化数据
(semi-structured data):比较松散,虽然可能有格式,但是经常被忽略,所以他只能作为对的一般指导。如:一张电子表格,其结构是由单元格组成的网格,但是每个单元格自身可保存任何形式的数据。
非结构化数据
- 非结构化数据
(unstructured data):没有什么特别的内部结构,如纯文本或图像数据。
关系型数据使用的是结构化数据,在数据库阶段按具体类型处理数据。关系型数据的规范性非常重要,保持数据的完整性、一致性。
MapReduce 线性,可伸缩性编程
程序员需要编写 map函数 和 reduce函数。每个函数定义从一个键值对集合到另一个键值对集合的映射。
MapReduce 工作原理

map函数:接受一个键值对(key-value pair),产生一组中间键值对。MapReduce框架会将map函数产生的中间键值对里键相同的值传递给一个reduce函数。
reduce函数:接受一个键,以及相关的一组值,将这组值进行合并产生一组规模更小的值(通常只有一个或零个值)。
单词统计为例子:
主要分为Split、Map、Shuffle和Reduce阶段,每个阶段在WordCount中的作用如下:
- Split阶段,首先大文件被切分成多份,假设这里被切分成了3份,每一行代表一份。
- Map阶段,解析出每个单词,并在后边记上数字1。
- Shuffle阶段,将每一份中的单词分组到一起,并默认按照字母进行排序。
- Reduce阶段,将相同的单词进行累加。
输出结果。
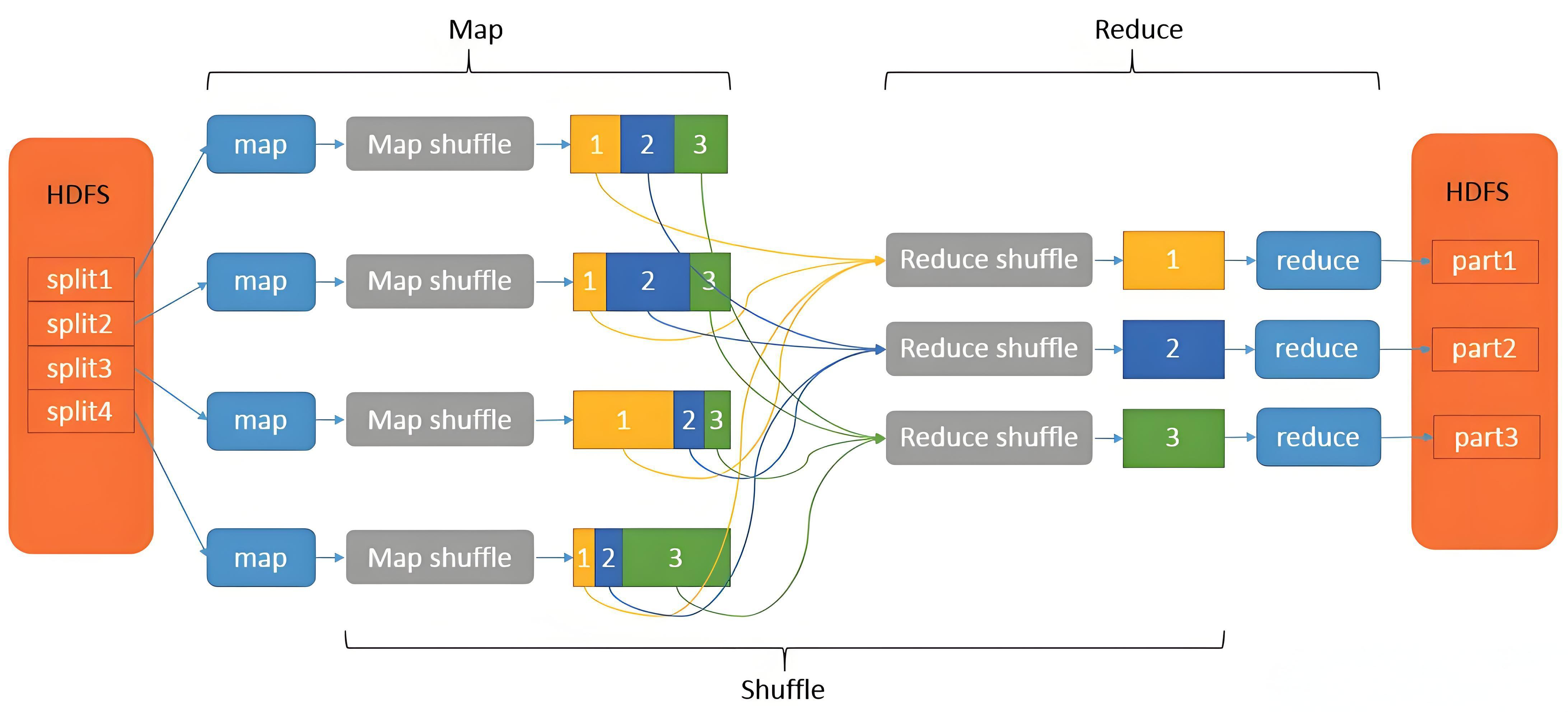
mapreduce整体工作流程
MapReduce的工作过程,一共分为input、split、map、shuffle、reduce、output六个阶段。
具体执行过程如下: - input阶段:将数据源输入到MapReduce框架中 - split阶段:将大规模的数据源切片成许多小的数据集,然后对数据进行预处理,处理成适合map任务输入的形式。 - map阶段:对输入的键值对进行处理,然后产生一系列的中间结果。通常一个split分片对应一个map任务,有几个split就有几个map任务。 - shuffle阶段:对map阶段产生的一系列进行分区、排序、归并等操作,然后处理成适合reduce任务输入的键值对形式。Shuffle完成对数据的排序和合并等操作,但是Shuffle不会对输入的数据进行改动,所以还是key2和value2。 - reduce阶段:提取所有相同的key,并按用户的需求对value进行操作,最后也是以的形式输出结果。 - output阶段:进行一系列验证后,将reduce的输出结果上传到分布式文件系统中。
map的流程
Read阶段:MapTask通过InputFormat获得的RecordReader,从输入InputSplit中解析出一个个Key-Value。
Map阶段:该节点主要是将解析出的Key-Value交给用户编写map()函数处理,并产生一系列新的Key-Value。
Collect收集阶段:在用户编写map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它会将生成的Key-Value分区(调用Partitioner),并写入一个环形内存缓冲区中。
Spill阶段:即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作。
Merge阶段:当所有数据处理完成后,MapTask对所有临时文件进行一次合并,以确保最终只会生成一个数据文件
reduce流程
Copy阶段:ReduceTask从各个MapTask上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中。
Sort阶段:在远程拷贝数据的同时,ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。按照MapReduce语义,用户编写reduce()函数输入数据是按Key进行聚集的一组数据。为了将Key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经实现对自己的处理结果进行了局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可。
Reduce阶段:reduce()函数将计算结果写到HDFS上。
三次排序
-
第一次排序:在map阶段,数据从内存中的环形缓冲区溢出到磁盘时,落地磁盘的文件会按照key进行分区和排序,排序算法为快速排序
-
第二次排序:在map阶段,最后对输出的文件进行combiner合并过程中,需要对溢出的小文件进行归并排序,排序算法为归并排序
-
第三次排序:在reduce阶段,reducetask将不同maptask端文件拉到同一个reduce分区后,对文件进行合并,排序算法为归并排序
Shuffle的定义和作用
Shuffle是MapReduce框架中的一个核心过程,位于mapper之后、reducer之前。其主要作用是将map端的无规则输出按指定的规则处理成具有一定规则的数据,以便reduce端接收处理。Shuffle涉及磁盘的读写和网络的传输,因此其性能直接影响整个程序的运行效率
为了优化Hadoop Shuffle的性能,可以采取以下措施:
- 数据压缩:在map端对数据进行压缩,减少数据传输量。
- 数据合并:在第一次排序后进行数据合并处理,减少数据倾斜。
- 调整环形缓冲区大小和溢写阈值:合理设置这些参数可以优化性能。
- 使用combiner:在第一次排序后使用combiner进行初步的数据合并处理
HDFS架构
HDFS采用master/slave架构

Block 数据块
linux中每个磁盘有默认的数据块大小,这是对磁盘操作的最小单位,通常512字节。HDFS同样也有块(Block)的概念,默认64MB/128MB,比磁盘块大得多。与单一的文件系统类似,HDFS上的文件系统也被划分成多个分块(Chunk)作为独立的存储单元。
一个hadoop文件就是由一系列分散在不同的DataNode上的block组成。
HDFS默认的Block为64MB/128MB?
块相对较大,主要是把寻道时间最小化。如果一个块足够大,从硬盘传输数据的时间将远远大于寻找块起始位置的时间。这样使得HDFS的数据块速度和硬盘的传输速度更加接近。
NameNode(元数据节点)
NameNode的作用是管理文件目录结构,接收用户的操作请求,是管理数据节点的,是一个jetty服务器。
NameNode节点维护两套数据
- 一套是文件目录与数据块之间的关系 (eg:
file1: block1,block2...) - 另一套是数据块与节点之间的关系 (eg:
block1: dataNode1, dataNode2)(不会持久化,靠DataNode和NameNode通信心跳完成汇报)
前一套 数据是 静态的 ,是存放在磁盘上的, 通过fsimage和edits文件来维护 ; 后一套 数据是 动态的 ,不持久放到到磁盘的,每当集群启动的时候,会自动建立这些信息,所以一般都放在内存中。
看看NameNode保存文件的具体metadata信息,包括:
-
文件owership和permissions
-
文件包含哪些块
-
Block保存在哪个DateNode(由DataNode启动时上报给)
例如一个Metadata: 文件名file.txt, 有三个数据块,每个数据块有3个备份存储到DataNode中
file.txt
Block A:
DataNode1,DataNode5,DataNode6
Block B:
DataNode7,DataNode1,DataNode2
Block C:
DataNode5,DataNode8,DataNode9
NameNode的metadata信息在启动后会加载到内存中
文件包括如下:
- fsimage (文件系统镜像):元数据镜像文件。存储某一时段NameNode内存元数据信息。
- edits: 操作日志文件。
- fstime: 保存最近一次checkpoint的时间
NameNode决定是否将文件映射到DataNode的复制块上:多副本,默认3个,第一个复制块存储在同一机架的不同节点上,最后一个复制块存储到不同机架的某个节点上。


转自:http://www.cnblogs.com/gisorange/p/4328859.html
Secondary NameNode(辅助元数据信息)
Secondary NameNode是一个用来监控HDFS状态的辅助后台程序。定期的将Namespace镜像与操作日志文件(edit log)合并,以防止操作日志文件(edit log)变得过大;能减少NameNode启动时间。
它不是NameNode的热备份,可以作为一个冷备份
- 将本地保存的fsimage导入
- 修改cluster的所有DataNode的NameNode地址
- 修改所有client端的NameNode地址
- 或者修改Secondary NameNode IP为 NameNode IP

缺点
- 性能瓶颈:
Secondary NameNode需要从NameNode拉取编辑日志和fsimage文件,这可能导致网络流量增大,特别是在大型集群中。
合并过程本身也是一个相对耗时的操作,尤其是在集群元数据非常庞大时,这可能导致NameNode在执行checkpoint时性能下降。
- 单点故障:
Secondary NameNode作为一个单独的服务运行,如果它发生故障或不可用,那么HDFS集群的checkpoint过程将受到影响。
- 资源占用:
Secondary NameNode需要额外的资源(如CPU、内存和磁盘空间)来执行checkpoint操作,这可能对资源紧张的环境造成压力。
- 不支持在线Checkpoint:
在Hadoop 1.x中,Secondary NameNode不支持在线Checkpoint。这意味着在执行checkpoint时,NameNode必须停止服务一小段时间,这对于需要高可用性的生产环境来说是一个不可接受的缺点。
Standby NameNode
在Hadoop 3.x及更高版本中,推荐使用Standby NameNode来实现NameNode的高可用性。这种方式下,有两个NameNode实例(一个活跃的Active NameNode和一个待命的Standby NameNode),以及一个共享的编辑日志和文件系统镜像。这样可以在Active NameNode故障时,快速切换到Standby NameNode,而不需要手动介入。
步骤如下:
-
配置NameNode HA: 在hdfs-site.xml中配置NameNode HA相关的属性,如dfs.nameservices、dfs.ha.namenodes.{nameservice}、dfs.namenode.rpc-address.{nameservice}.{nn}等。
-
配置JournalNode: 设置JournalNode来存储共享的编辑日志。在所有NameNode和JournalNode所在的节点上配置dfs.journalnode.edits.dir。
-
配置ZooKeeper: 使用ZooKeeper来管理NameNode之间的状态和领导者选举。配置ZooKeeper的连接信息在hdfs-site.xml中。
-
启动NameNode和JournalNode: 启动所有配置好的NameNode和JournalNode服务。
-
格式化NameNode: 在第一次启动时,需要格式化NameNode的命名空间。可以使用hdfs namenode -format命令。注意,在HA配置中,只需要在Active NameNode上格式化一次。
-
启动ZooKeeper、JournalNode、Active NameNode和Standby NameNode: 确保ZooKeeper、JournalNode以及两个NameNode都正常运行。
通过以上步骤,可以实现Hadoop环境中的NameNode的备(Secondary)状态或高可用性配置。对于生产环境,推荐使用Hadoop 3.x及以上版本的Standby NameNode来实现高可用性。
DataNode(数据存储节点)
DataNode的作用是HDFS中真正存储数据的。
DataNode的作用:
-
保存Block,每个块对应一个元数据信息文件。这个文件主要描述这个块属于哪个文件,第几个块等信息。
-
启动DataNode线程的时候会向NameNode汇报Block信息
-
通过向NameNode发送心跳保持与其联系(3秒一次),如果NameNode 10分钟没有收到DataNode的心跳,认为其已经lost,并将其上的Block复制到其它的DataNode.
假设文件大小是100GB,从字节位置0开始,每64MB字节划分为一个block,依此类推,可以划分出很多的block。每个block就是64MB大小。block是hdfs读写数据的基本单位。
rack 机架
在 Hadoop 中,机架指的是物理服务器所在的物理位置或逻辑分组。一个 Hadoop 集群通常由多台服务器(节点)组成,这些服务器可以分布在多个机架上。Hadoop 的设计考虑了故障容忍性和数据处理的效率,因此对机架有着精细的管理和优化。
机架的作用
- 数据本地性:Hadoop 尽量在数据所在的节点上处理数据,从而减少网络传输的开销。
- 容错性:Hadoop 通过将数据备份到不同机架的节点来提高数据的可靠性。
- 负载均衡:合理的机架设计可以避免集群某个机架的过载,确保集群资源的有效利用。
一个Block的副本会保存到两个或两个以上的机架上的服务器中,这样能防灾容错,因为一个机架出现掉电,交换机挂了的概率还是很高的。
hadoop读取文件

hadoop写文件

Hadoop在创建新文件时是如何选择block的位置的呢,综合来说,要考虑以下因素:带宽(包括写带宽和读带宽)和数据安全性。如果我们把三个备份全部放在一个datanode上,虽然可以避免了写带宽的消耗,但几乎没有提供数据冗余带来的安全性,因为如果这个datanode宕机,那么这个文件的所有数据就全部丢失了。另一个极端情况是,如果把三个冗余备份全部放在不同的机架,甚至数据中心里面,虽然这样数据会安全,但写数据会消耗很多的带宽。Hadoop 0.17.0给我们提供了一个默认replica分配策略(Hadoop 1.X以后允许replica策略是可插拔的,也就是你可以自己制定自己需要的replica分配策略)。replica的默认分配策略是把第一个备份放在与客户端相同的datanode上(如果客户端在集群外运行,就随机选取一个datanode来存放第一个replica),第二个replica放在与第一个replica不同机架的一个随机datanode上,第三个replica放在与第二个replica相同机架的随机datanode上。如果replica数大于三,则随后的replica在集群中随机存放,Hadoop会尽量避免过多的replica存放在同一个机架上。
转自:http://www.cnblogs.com/beanmoon/archive/2012/12/17/2821548.html
NameNode的安全模式
在分布式文件系统自动的时候,开始时会有安全模式,当分布式文件系统处于安全模式的情况下,文件系统中不允许有上传,修改,删除等写操作,只能读,直到安全模式结束。
1) namenode启动的时候,首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作
2) 一旦在内存中成功建立文件系统元数据的映射,则创建一个新的fsimage文件(这个操作不要SecondaryNameNode)和一个空的日志edits文件
3) NameNode开始监听RPC和HTTP请求
4) 此刻namenode运行在安全模式,即namenode的文件系统对于客户端来说是只读的。(可以显示目录,显示文件内容等;写,删除,重命名等操作都会失败)
5) 系统中的数据块的位置不是有namenode维护的,而是以块列表的形式存储在datanode中(datanode启动汇报的)
6) 在系统的正常操作期间,namenode会在内存中保留所有块位置的映射信息
7)在安全模式下,各个datanode会向namenode发送块列表的最新情况
8) 进入和离开安全模式
查看namenode处于哪个状态
hadoop dfsadmin -sagemode get
进入安全模式(hadoop启动的时候是在安全模式)
hadoop dfsadmin -sagemode enter
离开安全模式
hadoop dfsadmin -sagemode leave
Hadoop中的RPC机制
同其他RPC框架一样,Hadoop RPC分为四个部分:
(1)序列化层:Clent与Server端通信传递的信息采用了Hadoop里提供的序列化类或自定义的Writable类型;
(2)函数调用层:Hadoop RPC通过动态代理以及java反射实现函数调用;
(3)网络传输层:Hadoop RPC采用了基于TCP/IP的socket机制;
(4)服务器端框架层:RPC Server利用java NIO以及采用了事件驱动的I/O模型,提高RPC Server的并发处理能力;
扩展:yarn
在 YARN 出现之前,Hadoop 1.0 的架构很简单,但也存在致命缺陷。它的核心是 MapReduce v1,由两个主要部分组成:
- JobTracker: 一个“超级大总管”,集所有权力于一身。它既要管理集群资源(哪个机器有多少空闲),又要调度所有任务(Map、Reduce 任务的分配、监控、重试)。
- TaskTracker: 每个工作节点上的“小工头”,负责执行 JobTracker 分配下来的具体任务,并向 JobTracker 汇报心跳和任务状态。
弊端:
- 单点故障 (Single Point of Failure): JobTracker 是唯一的“大总管”,一旦它宕机,整个集群就瘫痪了,所有正在运行的任务都会失败。
- 性能瓶瓶颈: 所有的任务调度和资源管理都压在 JobTracker 一个进程上,当集群规模变大、任务增多时,它会不堪重负,成为整个系统的性能瓶颈。
- 编程模型单一: 这个架构天生就是为 MapReduce 模型设计的,不支持其他计算框架,如 Spark、Flink、Storm 等。想在 Hadoop 集群上跑其他类型的应用?几乎不可能。
- 资源利用率低: 资源被划分为固定的 Map Slot 和 Reduce Slot。如果 Map Slot 用完了,即使 Reduce Slot 大量空闲,Map 任务也只能等待,资源无法灵活共享。
YARN (Yet Another Resource Negotiator - 另一个资源协调者) 应运而生。它的核心思想是:将资源管理和任务调度这两大职能分离开。
YARN 的定位是 Hadoop 集群的通用资源管理系统和任务调度平台,可以理解为大数据集群的**“操作系统”**。它不再关心你运行的是什么类型的应用(MapReduce、Spark、Flink…),只负责高效、公平地为这些应用分配和管理资源(CPU、内存)。
yarn 架构
+-------------------------------------------------+
| ResourceManager (总老板) |
| +------------------+ +----------------------+ |
| | Scheduler | | ApplicationManager | | <-- (全局唯一)
| | (负责资源分配策略) | | (负责管理所有应用) | |
| +------------------+ +----------------------+ |
+-------------------------------------------------+
^ | ^ |
| Heartbeat/Resource Report | Application Submission
| v | v
+----------------+ +----------------+ +----------------+
| NodeManager 1 | | NodeManager 2 | | NodeManager N | <-- (每个节点一个)
| (车间主任) | | (车间主任) | | (车间主任) |
| +-----------+ | | +-----------+ | | +-----------+ |
| | Container |<-+---| | AppMaster |<-+---| | Container | |
| | (工位/任务) | | | (项目经理) | | | (工位/任务) | |
| +-----------+ | | +-----------+ | | +-----------+ |
| +-----------+ | | +-----------+ | | +-----------+ |
| | Container | | | | Container | | | | Container | |
| +-----------+ | | +-----------+ | | +-----------+ |
+----------------+ +----------------+ +----------------+
比喻:
| YARN 组件 | 工厂比喻 | 职责 |
|---|---|---|
| ResourceManager (RM) | 工厂总老板 | 全局资源管理器。 |
| NodeManager (NM) | 车间主任 | 节点资源管理器。每个工作节点上有一个,负责管理本台机器的资源,并向“总老板”汇报。 |
| ApplicationMaster (AM) | 项目经理 | 应用程序管理器。每个应用(Job)启动时,会有一个专属的“项目经理”,负责向“总老板”申请资源,并指挥“车间主任”干活。 |
| Container | 标准工位 | 资源容器。对资源(CPU、内存)的抽象。一个“工位”就是一份定量的资源,任务只能在分配好的“工位”里运行。 |
Spark 应用提交到 YARN 集群的完整流程
- 客户端提交应用:
- 你在终端执行 spark-submit --master yarn … 命令。
- 客户端会连接到 ResourceManager (总老板),说:“我要启动一个 Spark 应用,请给我一个‘项目经理’的位置。”
- 启动 ApplicationMaster (项目经理):
- RM 收到请求后,会在某个 NodeManager (车间主任) 上找一个空闲的 Container (工位)。
- 然后命令这个 NM 在这个 Container 里启动 ApplicationMaster (项目经理) 进程。
- AM 注册并申请资源:
- AM 启动后,会立即反向注册到 RM,说:“老板你好,我是 Spark 应用 XXX 的项目经理,现在开始由我负责。根据我的计算,我需要 10 个工位(Container),每个需要 2核CPU 和 4G 内存。”
- RM 分配资源:
- RM 的 Scheduler 组件根据当前的资源状况和调度策略(如公平调度、容量调度),开始在各个 NM 上寻找符合条件的空闲 Container。
- 找到后,RM 不会直接把任务放进去,而是把这些 Container 的“使用券”发给 AM。
- AM 指挥 NM 启动任务:
- AM 拿到“使用券”后,会直接与对应的 NodeManager (车间主任) 通信,说:“张主任,我这里有老板批的条子,请在你的 2 号和 5 号工位上,启动我的 Spark Executor 任务。”
- NM 验证“使用券”后,就在指定的 Container 里启动真正的计算任务(如 Spark Executor)。
- 任务运行与监控:
- 各个 Container 里的任务开始执行计算。它们会定期向自己的 AM (项目经理) 汇报进度和状态。
- AM 负责监控整个应用的运行情况,如果某个任务失败了,它可以向 RM 重新申请一个 Container 来重试这个任务。
- 同时,各个 NM 也会持续向 RM 汇报自己整个节点的健康状况。
- 应用结束:
- 当应用所有任务都成功完成后,AM (项目经理) 会向 RM (总老板) 注销自己,并告知任务已完成。
- RM 收到通知后,会回收这个应用占用的所有 Container (工位),以便分配给下一个应用。
yarn调度机制
Hadoop YARN 的调度器(Scheduler)是 ResourceManager (RM) 中最核心、最复杂的组件之一。它决定了集群中的资源(CPU、内存)如何被分配给成百上千个并发的应用(Job)。
| 特性 | 容量调度器 (Capacity Scheduler) | 公平调度器 (Fair Scheduler) | FIFO 调度器 |
|---|---|---|---|
| 核心理念 | 资源保障 (Guarantee) | 公平共享 (Fairness) | 先到先服务 |
| 资源分配单位 | 队列 (Queue) | 资源池 (Pool) | 单一队列 |
| 默认行为 | 按队列容量分配,空闲资源可弹性共享 | 所有活跃应用平分资源 | 队列头部应用优先 |
| 小任务处理 | 可能需要在队列内排队等待 | 立即获得资源,响应快 | 必须等待大任务完成 |
| 抢占机制 | 为保障队列容量而抢占 | 为满足最小共享而抢占 | 无抢占 |
| 数据本地性 | 支持节点本地性,但不如 Fair Scheduler 优化 | 通过延迟调度优化数据本地性 | 支持节点本地性 |
| 典型场景 | 企业级多租户共享集群,需要严格的资源配额和SLA保障 | 交互式、多用户共享集群,强调任务响应速度和公平性 | 教学、测试环境 |
| 默认选择 | CDH, HDP 等发行版默认 |
在现代大数据平台中,容量调度器和公平调度器是绝对的主流,选择哪一个取决于你的业务需求:
- 如果你的组织结构清晰,需要为不同部门划分明确的资源“领地”,并提供服务等级协议(SLA),那么容量调度器是更好的选择。
- 如果你希望集群对所有用户都尽可能公平,特别是希望短平快的交互式查询能得到快速响应,那么公平调度器可能更适合你。

















 5321
5321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









