




 本文详细介绍Hadoop集群的安装与配置流程,包括环境准备、网络配置、SSH无密码登录设置、PATH变量配置及核心配置文件调整。适用于初学者快速搭建Hadoop集群环境。
本文详细介绍Hadoop集群的安装与配置流程,包括环境准备、网络配置、SSH无密码登录设置、PATH变量配置及核心配置文件调整。适用于初学者快速搭建Hadoop集群环境。
集群安装前置条件
已掌握Hadoop单机伪分布式安装配置,否则先查看Hadoop伪分布式安装与配置。
环境
Ubuntu 18.04 + JDK 1.8 + Hadoop 2.10 + SSH
本教程简单的使用两个节点作为集群环境:一个Master节点,一个Slave节点。
准备工作
Hadoop 集群的安装配置大致为如下流程:
- 选定一台机器作为 Master
- 在 Master 节点上配置 hadoop 用户、安装 SSH server、安装 Java 环境
- 在 Master 节点上安装 Hadoop,并完成配置
- 在其他 Slave 节点上配置 hadoop 用户、安装 SSH server、安装 Java 环境
- 将 Master 节点上的 /usr/local/hadoop 目录复制到其他 Slave 节点上
- 在 Master 节点上开启 Hadoop
如果你已按照Hadoop伪分布式安装与配置进行过单机伪分布式安装,且能正常运行,将此虚拟机实例进行克隆即可。
先关闭当前虚拟机实例。
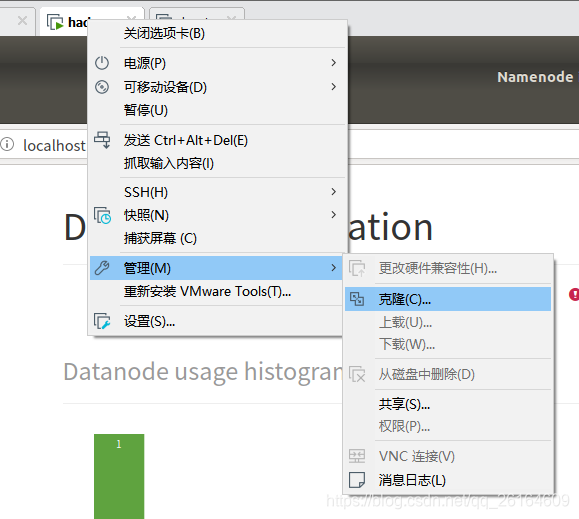
选择创建完整克隆,此时你就创建了一个跟前者功能完全相同的虚拟机实例(SSH+Java+Hadoop已拥有),就不用再重新配置了。
网络配置
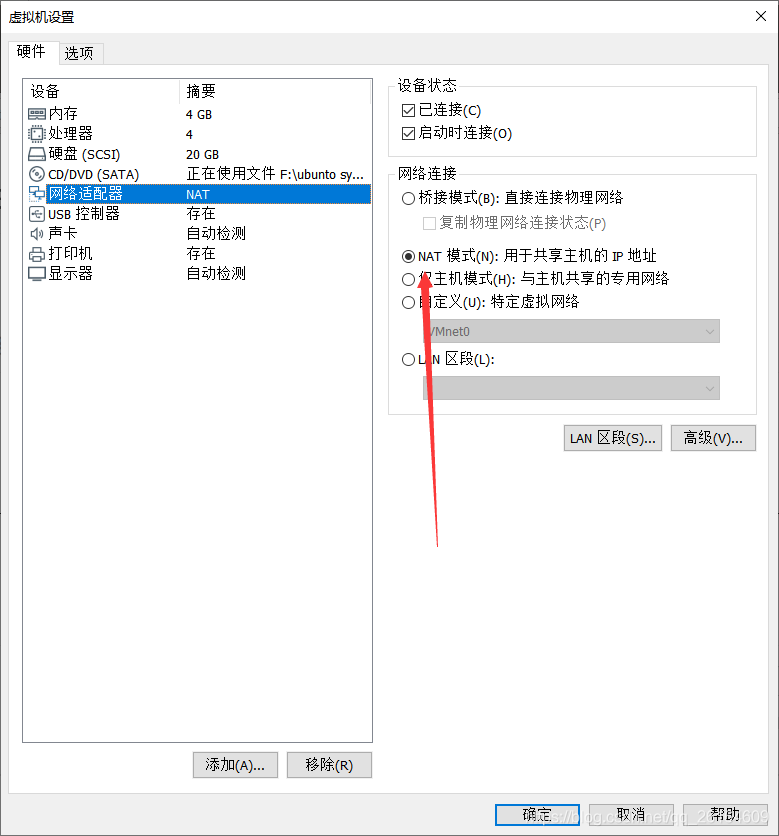
两个虚拟机实例的网络适配器选用NAT模式即可。
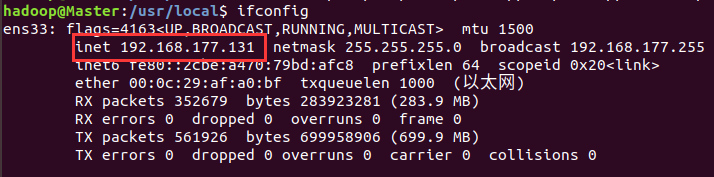
查看Linux的几点IP地址(命令为ifconfig),即inet地址。
Master节点IP
Slave节点IP
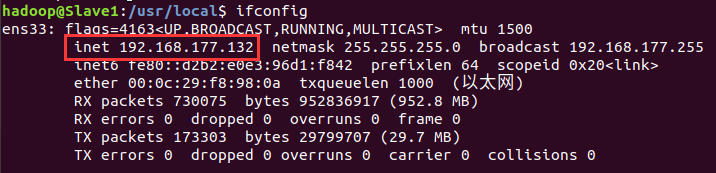
首先在Master节点上关闭Hadoop(/usr/local/hadoop/sbin/stop-dfs.sh),在进行后续进群配置。
为了便于区分,我们修改一下各个节点的主机名
sudo vim /etc/hostname
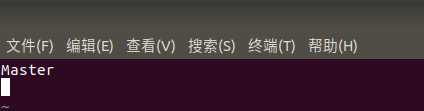
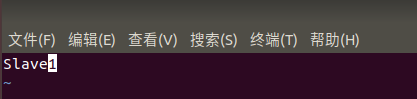
然后根据上述我们查到的两个节点的IP地址修改自己所用节点的IP映射
sudo vim /etc/hosts在 Master与Slave1节点的/etc/hosts 中将该映射关系填写上去即可(一般该文件中只有一个 127.0.0.1,其对应名为 localhost,如果有多余的应删除,特别是不能有 “127.0.0.1 Master” 这
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 571
571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









