






1.JDK 自带工具类创建的线程池的四种方式
newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
2.创建线程池的7个参数
.corePoolSize线程池的核心线程数
maximumPoolSize能容纳的最大线程数
keepAliveTime空闲线程存活时间
unit 存活的时间单位
workQueue 存放提交但未执行任务的队列
threadFactory 创建线程的工厂类
handler 等待队列满后的拒绝策略
3.为什么要手动创建线程池
JDK 自带工具类创建的线程池存在的问题
直接使用这些线程池虽然很方便,但是存在两个比较大的问题
1.有的线程池可以无限添加任务或线程,容易导致 OOM;
2.还有一个问题就是这些线程池的线程都是使用 JDK 自带的线程工厂 (ThreadFactory)创建的,线程名称都是类似pool-1-thread-1的形式,第一个数字是线程池编号,第二个数字是线程编号,这样很不利于系统异常时排查问题。
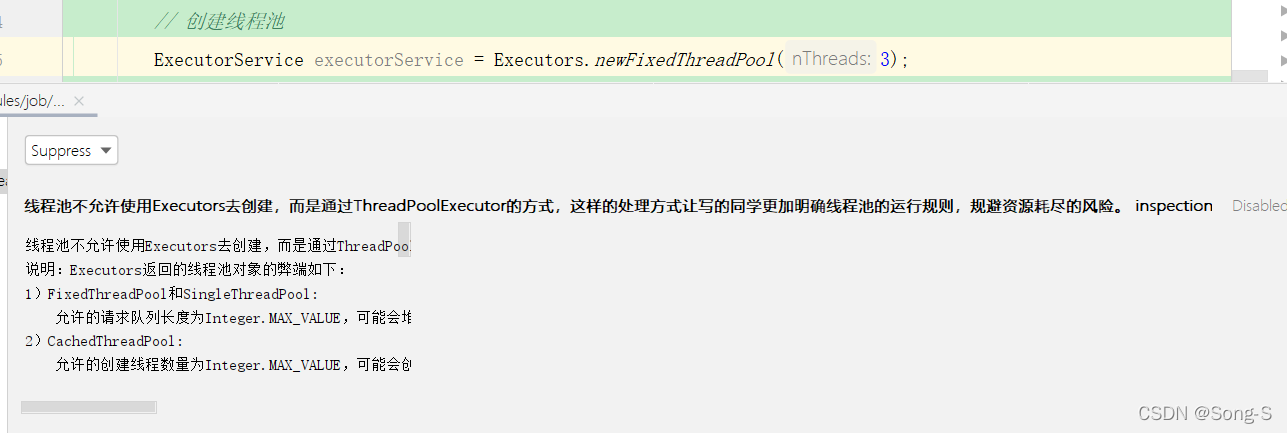
3.如果你安装了“阿里编码规约”的插件,在使用Executors创建线程池时会出现以下警告信息:
4.手动创建线程池代码实例*
// 手动创建线程池(核心线程数为cpu核数,最大线程cpu核数X2)
ExecutorService threadPool = new ThreadPoolExecutor(
4,
8,
30,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(20),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.DiscardPolicy());
// 根据runnable 创建一个futuretask对象
FutureTask<Map<String, Object>> managementScoreTask = new FutureTask<>(new Callable<Map<String, Object>>() {
@Override
public Map<String, Object> call() {
//替换为自己的业务方法返回
return calculationManagementScore(tbBeforeInvestmentEntity);
}
});
//向线程池提交任务,交由线程池去执行
threadPool.submit(managementScoreTask);
//...按自己业务继续向线程池添加任务
//最后关闭线程池
threadPool.shutdown();
//从线程池中获取数据get
Map<String, Object> managementScoreResult = managementScoreTask.get();
**5.四种线程池拒绝策略**
当线程池的任务缓存队列已满并且线程池中的线程数目达到maximumPoolSize时,如果还有任务到来就会采取任务拒绝策略,通常有以下四种策略:
ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
ThreadPoolExecutor.DiscardPolicy:丢弃任务,但是不抛出异常。
ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新提交被拒绝的任务
ThreadPoolExecutor.CallerRunsPolicy:由调用线程(提交任务的线程)处理该任务


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









