 Kafka原理与核心概念
Kafka原理与核心概念








 本文介绍了Kafka的基本原理及核心概念,包括如何利用Zookeeper保存元数据、消息的存储方式、分区设计的目的等,并解释了Kafka如何通过分区实现分布式存储。
本文介绍了Kafka的基本原理及核心概念,包括如何利用Zookeeper保存元数据、消息的存储方式、分区设计的目的等,并解释了Kafka如何通过分区实现分布式存储。
上一遍讲完Kafka的安装以及简单使用。
接着进一步了解一下相关概念以及原理:
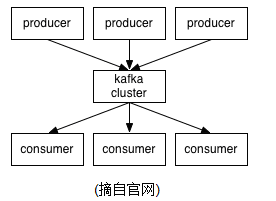
1.它使用zookeeper来保存一些meta信息。
2。按Topic分类,一个Topic将被分成多个partition(区),每个partition在存储层面是append log文件。
任何发布到此partition的消息都会直接追加到log文件的尾部。每条消息在文件中的位置称为offset,offset是一个long型数字,它是唯一标记一条信息。kafka不允许对消息进行随机读写。
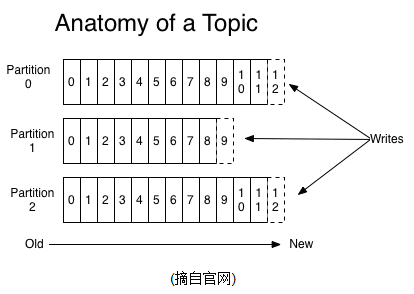
3.kafka的消息无论是否被消息都会保存一定时间,默认为2天。2天过后将被删除。来释放磁盘空间。
4.对于consumer来说:它需要保存offset,offset保存在zookeeper中。
5.kafka几乎不需要维护任何consumer与producer的状态信息,这些信息保存在zookeeper中。
6.分区的设计目的有多个,最根本的原因是kafka基于文件存储,通过分区可以将日志分散到多个server中。达到分布式。
7.每个topic分成多个partition,partition被分布到多个server中,每个server负责partition中消息的读写操作。此外还可以配置多个备份,分配到不同机器上。

















 4687
4687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









