






如何利用Python-pptx 库和llama 大模型来自动化生成 PowerPoint 演示文稿
1、代码如下
from openai import OpenAI # 从 openai 模块导入 OpenAI 类
import textwrap
from pptx import Presentation
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from pydantic import BaseModel, Field
from typing import List
from llama_index.core import PromptTemplate
from llama_index.core import PromptTemplate
from llama_index.core.program import LLMTextCompletionProgram
api_key1 = '你的OPENAI_API_KEY' # 定义API密钥
import os
os.environ['OPENAI_API_KEY'] = api_key1
os.environ["OPENAI_API_BASE"] = 'https://chatapi.littlewheat.com/v1'
os.environ['GROQ_API_KEY'] = api_key1
# 基于 prompt 生成文本
def get_completion(prompt, model="gpt-3.5-turbo"):
messages = [{"role": "user", "content": prompt}]
response = llm.chat.completions.create(
model=model,
messages=messages,
temperature=0, # 模型输出的随机性,0 表示随机性最小
)
return response.choices[0].message.content
#you can use any PDF/text document for this excercise
#2.数据预处理:对源文档进行预处理,以便更好地进行信息检索。
reader = SimpleDirectoryReader(input_files =['E:/vscodeproject/大模型代码/钉钉考勤管理系统员工操作手册-v1.2.1(20240418)(2).pdf'])
docs = reader.load_data()
#3.创建向量存储索引:将处理后的文档内容输入到向量存储中,创建一个检索索引。
index = VectorStoreIndex.from_documents(docs)
# Creating a Pydantic object for structured output
#4.定义输出结构:使用结构化模型定义输出内容的格式,例如标题和 bullet points。
class Extract(BaseModel):
title: str = Field(description="Title for the information retrieved")
bullet_points: List[str] = Field(description="Three bullet-points for the information")
# The prompt
template = (
"We have provided context information below. \n"
"---------------------\n"
"{context_str}"
"\n---------------------\n"
"Given this information, please generate a header, and 3 bullet points for the {query_str}\n"
"Also fetch sub_titles and numbers to describe the information"
)
qa_template = PromptTemplate(template)
# Building the Query Engine, passing in the Prompt and Pydantic model
#5.构建查询引擎:配置查询引擎,包括 LLM、提示模板和输出格式。
query_engine = index.as_query_engine(similarity_top_k=3,text_qa_template=qa_template,response_mode='tree_summarize', output_cls=Extract)
# Query and response
#6.生成内容:通过查询引擎使用 LLM 生成幻灯片的内容,包括标题和关键点。
response=query_engine.query("加班申请的流程")
#Another Pydantic model to extract output
#7.生成 Python-pptx 代码:使用 LLM 再次调用,将生成的内容转换为 Python-pptx 代码。
template = (
"We have provided information below. \n"
"---------------------\n"
"{title}"
"{bullet_points}"
"\n---------------------\n"
"Given this information, please generate python-pptx code for a single slide with this title & bullet points\n"
"Separate the bullet points into separate texts"
"Do not set font size"
)
def create_ppt_from_code(code: str, output_file: str = "llm_generated.pptx"):
"""
根据生成的 Python 代码创建 PPT 文件
"""
# 创建一个新的 PPT 对象
prs = Presentation()
# 动态执行生成的代码
try:
# 找到第一个逗号的位置
comma_index = code.find("```python\n")
# 找到第一个逗号的位置
comma_index1 = code.find("\n```\n\n")
# 截取逗号和分号之间的部分
code = code[comma_index+9:comma_index1]
print("输出====:",code) # 输出: World
pre_index = code.find("presentation = Presentation()")
if pre_index>0:
code = code.replace("presentation = Presentation()", "")
code3 = textwrap.dedent(code).strip() # 去掉公共缩进
print("======",code3)
exec(code3, {"presentation":prs})
else:
code = code.replace("prs = Presentation()", "")
code3 = textwrap.dedent(code).strip() # 去掉公共缩进
print("======",code3)
exec(code3, {"prs":prs})
except Exception as e:
print(f"代码执行出错: {e}")
return
# 保存 PPT 文件
prs.save(output_file)
print(f"PPT 文件已生成: {output_file}")
class LLMTextCompletionProgram1:
def __init__(self, model: str, api_key: str, output_cls: str, prompt_template_str: str,base_url: str, verbose: bool = False):
self.model = model
self.api_key = api_key
self.output_cls = output_cls
self.prompt_template_str = prompt_template_str
self.verbose = verbose
self.base_url=base_url
@classmethod
def from_defaults(cls, output_cls: str, prompt_template_str: str, verbose: bool = False):
# 默认初始化方法
return cls(model="gpt-3.5-turbo", api_key=api_key1, output_cls=output_cls, prompt_template_str=prompt_template_str,base_url='https://chatapi.littlewheat.com/v1', verbose=verbose)
def generate(self, title: str, bullet_points: str) -> str:
print(self.prompt_template_str.format(title=title,bullet_points=bullet_points))
# 模拟调用 LLM 生成 Python 代码
from openai import OpenAI
client = OpenAI(api_key=self.api_key,base_url=self.base_url)
response = client.chat.completions.create(
model=self.model,
messages=[
{"role": "system", "content": "你是一个 Python 代码生成助手,生成用于创建 PowerPoint 的 Python 代码"},
{"role": "user", "content": self.prompt_template_str.format(title=title,bullet_points=bullet_points)},
],
max_tokens=500,
)
generated_code = response.choices[0].message.content
print("查询内容=====:\n", self.prompt_template_str)
if self.verbose:
print("生成的 Python 代码:\n", generated_code)
return generated_code
program = LLMTextCompletionProgram1.from_defaults(
output_cls="Python_code",
prompt_template_str=template,
verbose=True
)
#Feeding the response of the previous LLM call
#8.执行代码创建幻灯片:执行生成的 Python-pptx 代码,自动创建 PowerPoint 幻灯片。
#exec(output.code)
# 创建 PPT 文件
# 生成 Python 代码
generated_code = program.generate(title=response.title, bullet_points=response.bullet_points)
create_ppt_from_code(generated_code, "E:\示例4444_PPT.pptx")
2、实现结果
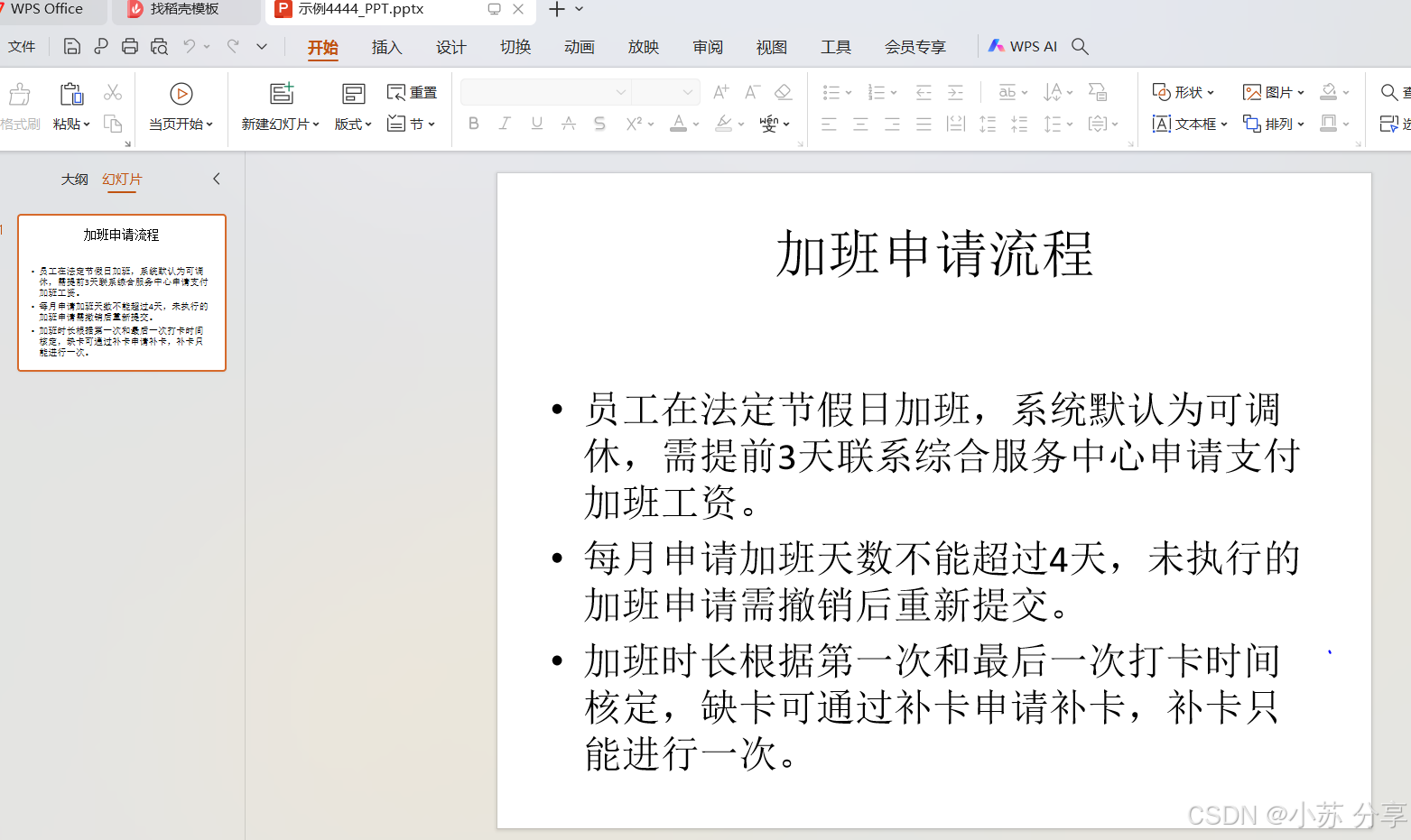
3、实现原理
通过读取pdf文件内容,并根据query查询pdf文件相关内容,并通过大模型输入内容。把输出内容通过大模型生成ppt代码,并执行代码生成ppt文件。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









