







一、背景介绍:
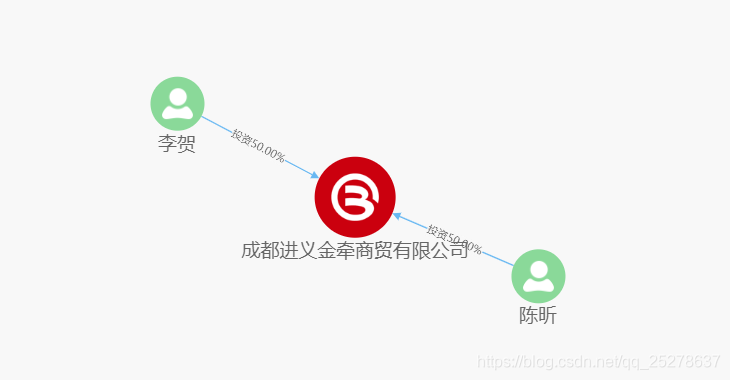
如上图所示,公司展示的实际控制人是使用工商投资关系,通过spark程序进行股权穿透计算后得到的结果,结果是直接写入到es的,es的结构如下图:

再拿es中的一条具体数据来看看,如下图:

可以看到es中有三个属性,分别是target_id, links,nodes,其中target_id是一个正常的string字段,links和nodes都是嵌套的json数组。
二、问题描述
因为实际控制人的数据是直接使用spark算法写入es的,后来需要用这个数据来进行一些其他逻辑的加工,所以首先考虑的是如何将嵌套es索引的数据拿到hive中,其次一个nodes中有多个节点信息,而实际控制人是tag标识为Top,如下图所示:

所以还涉及到了从nodes中筛选节点的问题。
三、处理思路
1.修改spark算法代码,在将数据写入es的同时将数据写入hive中。
2.由于hive支持和es的映射,所以可以将es的数据抽取到hive表中。
四、方案选择
因实际控制人spark算法是打好的jar包部署到客户现场,如果修改代码就涉及到重新打包并上传,流程很慢,任务紧急,所以就优先考虑使用思路2进行处理。
五、操作步骤
1.将es数据映射到一张hive表中
drop table if exists a_mart.controller_es2hive;
create table a_mart.controller_es2hive(
target_id string,
links array<struct<id:string, 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









