







 本文使用Python3.6.4在Win10环境下进行安居客西安地区的房源爬虫,对数据进行分析并实施线性回归。首先展示爬虫与分析结果,然后对不结构化的数据进行预处理,包括处理单价和总价的区间值及缺失值。通过预处理获得干净数据,进行回归分析。在分析过程中发现部分数据存在错误,如总价为多少万的表述,提示未来数据处理需要注意此类情况。
本文使用Python3.6.4在Win10环境下进行安居客西安地区的房源爬虫,对数据进行分析并实施线性回归。首先展示爬虫与分析结果,然后对不结构化的数据进行预处理,包括处理单价和总价的区间值及缺失值。通过预处理获得干净数据,进行回归分析。在分析过程中发现部分数据存在错误,如总价为多少万的表述,提示未来数据处理需要注意此类情况。
安居客爬虫+分析+回归
工具:Pycharm,Win10,Python3.6.4
这次我们要做的是安居客西安地区房源爬虫,然后数据分析,并做一个简单的回归分析。
我们之前的爬虫和简单的数据分析已经说了很多了,这里我不再展开描述,我直接贴出结果。
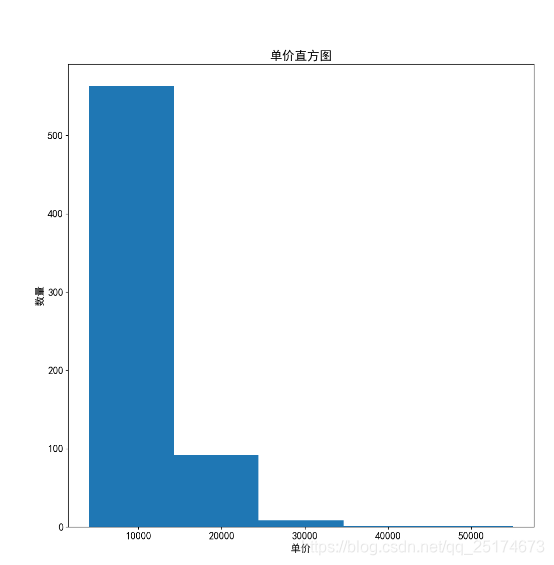
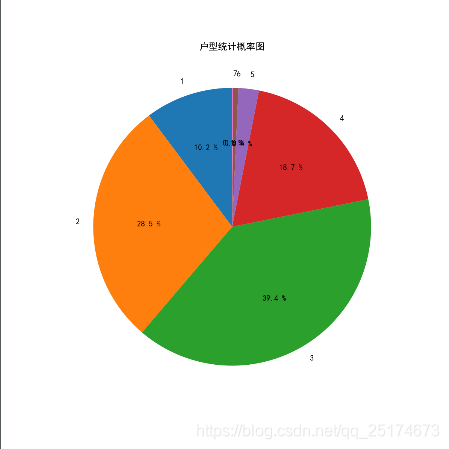
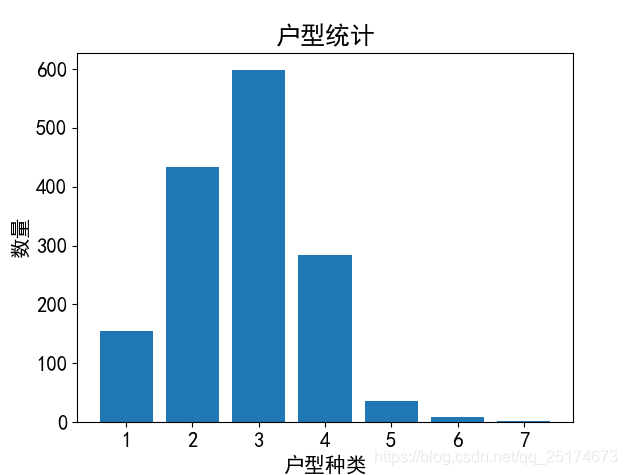
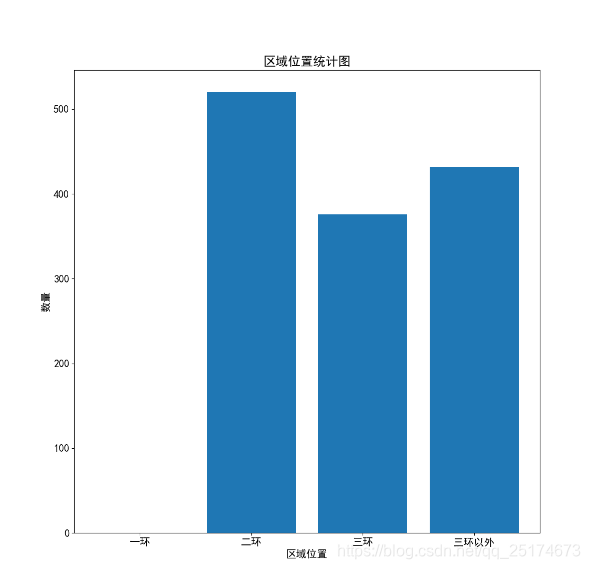
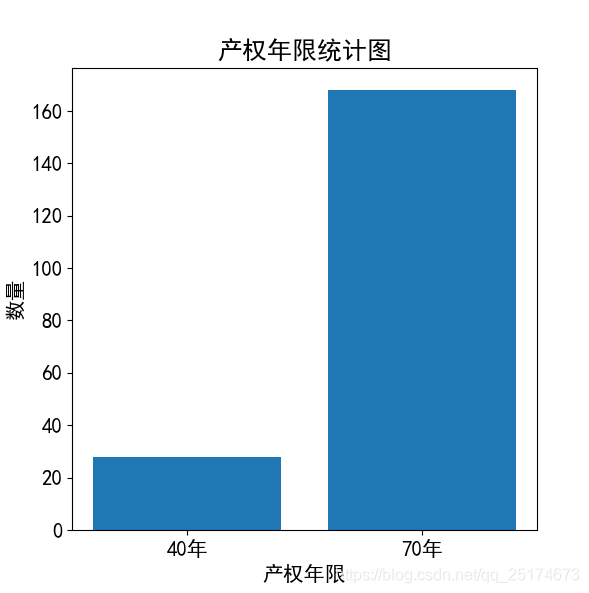
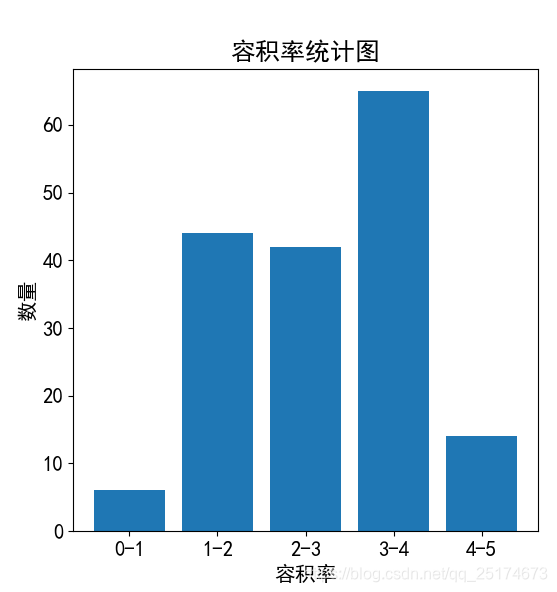
工具:Pycharm,Win10,Python3.6.4
这次我们要做的是安居客西安地区房源爬虫,然后数据分析,并做一个简单的回归分析。
我们之前的爬虫和简单的数据分析已经说了很多了,这里我不再展开描述,我直接贴出结果。
 7816
7816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章






















