







Chain of Thoughts OR Chain of Drafts
自Chain of Thoughts(CoT,思维链)提出以来,它已成为大模型推理任务的“黄金标准”。无论是GPT-4、Gemini还是Claude,主流模型均广泛采用CoT来提升复杂问题(如数学计算、逻辑推理)的准确性。然而,CoT的冗长性和高计算成本也饱受诟病——用户问“1+1等于几”,模型可能输出一篇小作文。
为此,在论文《Chain of Draft: Thinking Faster by Writing Less》提出了一种全新的提示技术——Chain of Drafts(CoD,草稿链),旨在保留CoT逻辑严谨性的同时,大幅提升效率。本文将解析CoD的核心原理,并探讨其如何重塑大模型的应用边界。
在我看来,不管是CoT 还是CoD,两者都是有能耐的“人物”。

一、什么是Chain of Drafts?
CoD是一种“极简版”思维链,其核心思想是:只保留推理过程中最关键的中间步骤,用最简短的表达传递逻辑链。与CoT的对比见下表:
| 对比项 | Chain of Thoughts(CoT) | Chain of Drafts(CoD) |
|---|---|---|
| 推理步骤 | 完整展开每一步,如详细数学推导 | 仅保留核心步骤(如关键公式/结论) |
| 输出长度 | 冗长(通常数百token) | 简短(通常减少50%以上token) |
| 适用场景 | 教育、复杂问题调试 | 实时应用(客服、助手)、资源受限环境 |
举个🌰:
问题:Jason有20根棒棒糖,给Denny若干根后剩12根,求给出去的数量。
- CoT输出:
Jason一开始有20根棒棒糖,给出后剩下12根。 计算差值:20 - 12 = 8,因此答案是8。 - CoD输出:
20−12=8 → Final Answer: 8.
二、CoD的三大优势:效率与成本的革命
-
更少的Token,更低的成本
CoD通过压缩中间步骤,显著减少token消耗。例如,GPT-4处理同一问题时,CoD的token数仅为CoT的30%,直接降低API调用成本(尤其在批量任务中)。 -
更快的响应速度
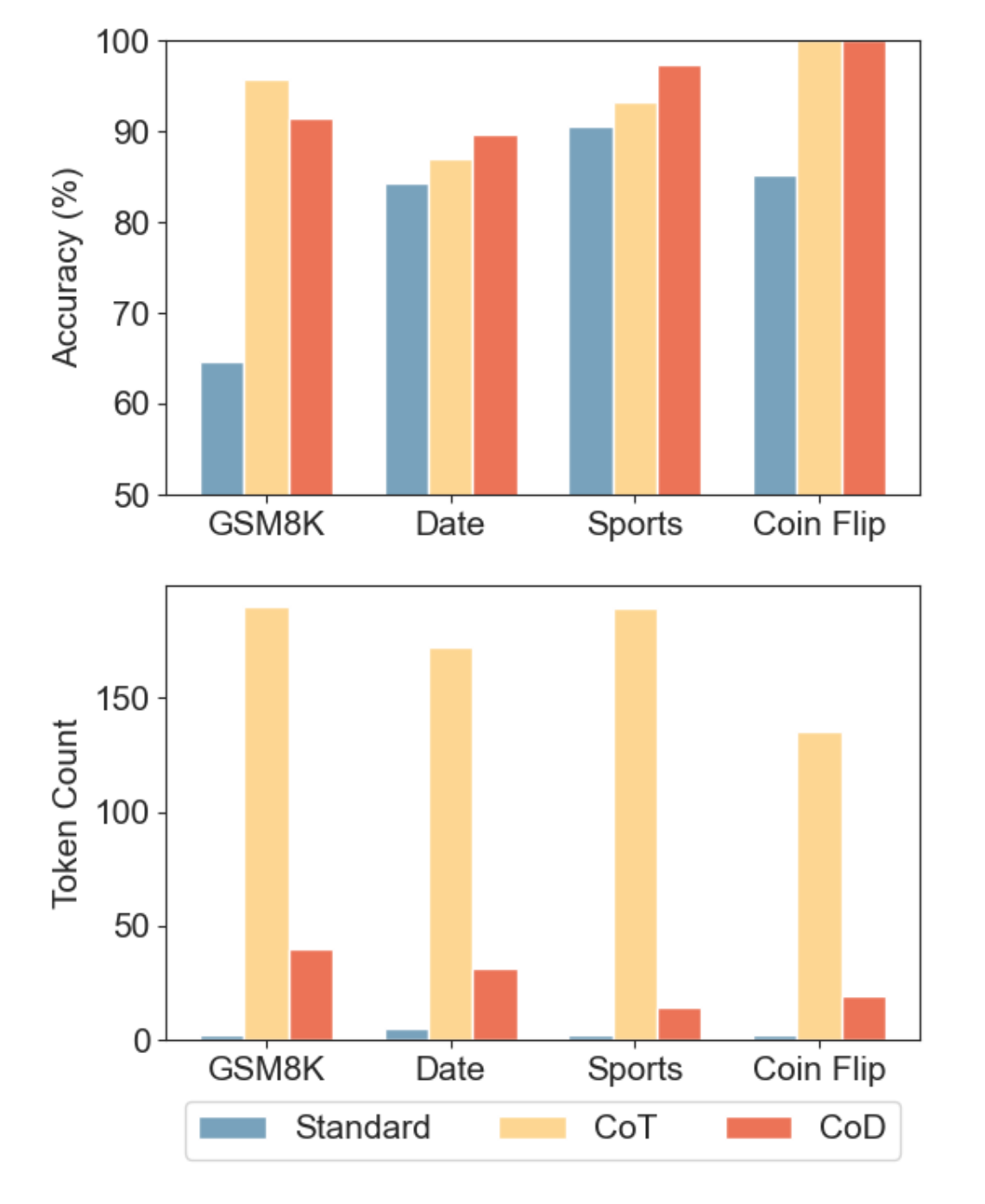
在实时场景(如智能客服)中,CoD的推理速度比CoT快40%-60%。下图为论文中的基准测试结果:模型 提示方法 准确率 Token数 延迟 标准提示 53.3% 1.1k 0.6s CoT 89.1% 4.8k 2.1s CoD 88.7% 2.3k 1.2s -
更适配生产环境
CoD的简洁输出更易集成至应用系统。例如,阿里云将CoD用于QwQ-32B模型的客服场景,响应速度提升55%,且用户反馈“答案更直接”。
三、CoT在主流模型中的应用现状
尽管CoD势头强劲,CoT仍是当前大模型的核心推理工具,尤其在需要透明性和教育意义的场景:
- GPT-4:
- 通过CoT解决复杂数学题(如国际奥赛题),准确率提升20%以上。
- 教育领域:为学生提供解题步骤,如代码调试中的逐行分析。
- Gemini:
- 在科学论文摘要生成中,使用CoT确保逻辑连贯性。
- 多模态推理:结合图像和文本,通过CoT生成详细描述。
- DeepSeek-R1:
-
纯强化学习驱动:DeepSeek-R1通过强化学习(RL)自主发展出CoT能力,无需人工标注中间步骤。例如,在数学测试AIME 2024中,其Pass@1得分从15.6%提升至71.0%,最终通过多轮优化达到86.7%,与OpenAI顶级模型持平。
-
多阶段训练优化:结合“冷启动数据+RL+拒绝采样”,R1解决了早期版本(R1-Zero)的可读性问题,生成更符合人类偏好的推理过程。
-
四、CoD的局限性与适用边界
优势
- 资源友好:适合手机、IoT设备等边缘计算场景。
- 高效实时:客服、语音助手等需快速响应的场景。
- 成本敏感:企业级应用中降低算力开销。
劣势
- 透明度不足:省略中间步骤,不利于调试与解释(如医疗诊断场景)。
- 复杂任务风险:对需要多步验证的问题(如法律文书审核),CoD可能遗漏关键逻辑。
五、CoD会取代CoT吗?
答案是否定的。二者将根据场景互补:
- CoT:用于教育、科研、复杂系统设计等需透明推理的场景。
- CoD:用于实时交互、成本敏感型任务(如电商推荐、智能家居)。
正如论文作者所述:“CoD不是CoT的替代品,而是其高效演化形态。”
结语
Chain of Drafts通过“少即是多”的设计哲学,为大模型推理效率提供了新思路。本文参考了Chain of Draft: Thinking Faster by Writing Less论文,感兴趣的小伙伴儿推荐阅读原文。
入股不亏,关注我们,获取更多AI相关知识和资讯~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









