



 本文围绕Redis展开,阐述其业务处理主线程坚持单线程的原因,介绍了Reactor - IO多路复用模式。还对比了Redis事务和Lua脚本,事务具备一定隔离性,Lua脚本可减少网络开销、保证原子性且能复用。最后探讨了缓存与数据库更新顺序问题及分布式锁的重要性。
本文围绕Redis展开,阐述其业务处理主线程坚持单线程的原因,介绍了Reactor - IO多路复用模式。还对比了Redis事务和Lua脚本,事务具备一定隔离性,Lua脚本可减少网络开销、保证原子性且能复用。最后探讨了缓存与数据库更新顺序问题及分布式锁的重要性。
之前跟某某居公司的高级开发有交流过Redis现在是多线程还是单线程,其实我觉得聊这种八股文问题没啥意思,毕竟他又没有说明,他提问前提是问的主线程是否为单线程。
因为Redis 在 2.6 版本,会启动 2 个后台线程,分别处理关闭文件、AOF 刷盘这两个任务;所以这时候起redis就不是单线程了,不过我知道他的意思还是想问主线程是怎么回事。
那么我给出我的答案,主线程到现在仍然是单线程。然后这位兄弟就着急了,redis 6.0版本之后处理业务线程也变成多线程了。我回答,多线程也只是IO线程(用来从内核空间加载数据到用户空间,或者将用户空间的数据写回内核空间的)开启了多线程,而且默认设置只是写回IO线程是开启多线程,IO读取线程仍然是主线程来完成。
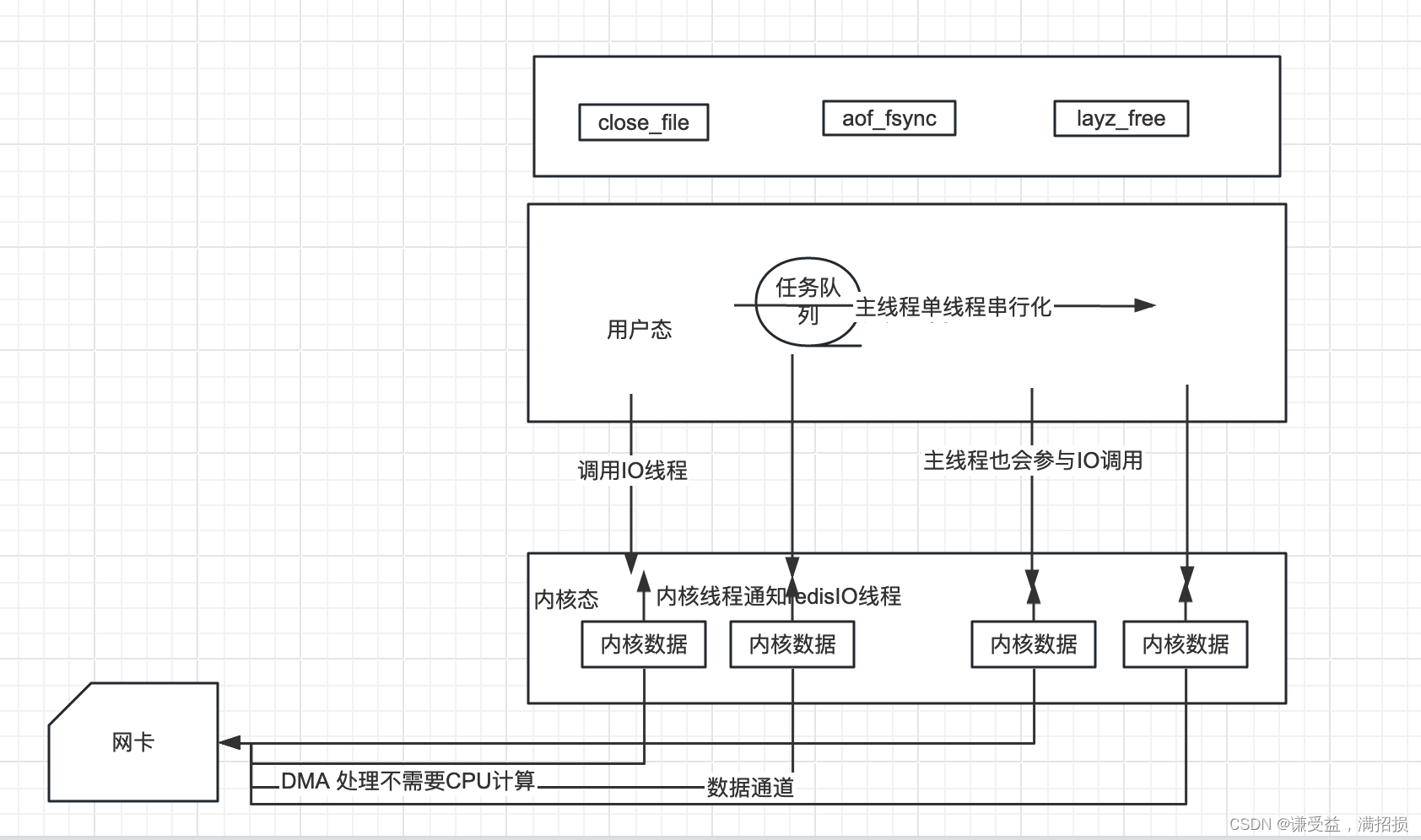
处理业务还是用的主线程也就是单线程来完成,只有这样,才能实现事务和Lua脚本的具有一定的原子性,打包的指令不会被其他指令插入。分布式锁也是在此基础上才能实现。
然后这位兄弟就说,实现指令原子性和串行化操作的是因为redis用了阻塞队列,我:内心此时无比语塞??就利用队列阻塞,处理逻辑不是单线程,或者做同步处理,它能是串行化处理任务的??你做过线程池处理任务吗?线程池的任务队列可都是阻塞队列的,线程池多线程处理任务不能并行化处理?此时,心里虽然不认同但我也并没有再聊下去了。
redis为什么要坚持将业务处理的主线程设计为单线程?
OK,从上图中可以看出redis其实主要性能占用是用户态和内核态的数据读写,而处理业务的主线程其实也就是处理下缓存设置,比较多的是各种数据结构缓存的时候,计算key的hash值,对应存放的内存地址。所以,它不算是cpu密集型计算。没必要用多线程,再用锁实现指令的串行化操作,维护大量线程,占用内存资源,锁的争用和释放也会消耗大量资源。
所以,基于内存操作,配合优秀的数据结构设计,比如跳表,hash,单线程完全可以胜任这种非CPU密集型运算,少了上下文切换,和锁的获取与释放操作,反而比多线程处理效率要更高。节省出其他物理线程给IO线程,和内核线程也没有浪费服务器的物理线程。当然,IO多路复用模型功不可没,
Reactor-IO多路复用
虽然IO多路复用算是同步阻塞式IO的升级版,但是也就在把数据从内核态复制到用户态的过程阻塞,在数据从物理硬件传输到内核态的过程中,根本不用阻塞,epoll函数做到哪个socket数据准备好了就通知用户态,这么多的socket,在主线程的event_loop执行完毕之前,总会有一路IO数据是准备好的。
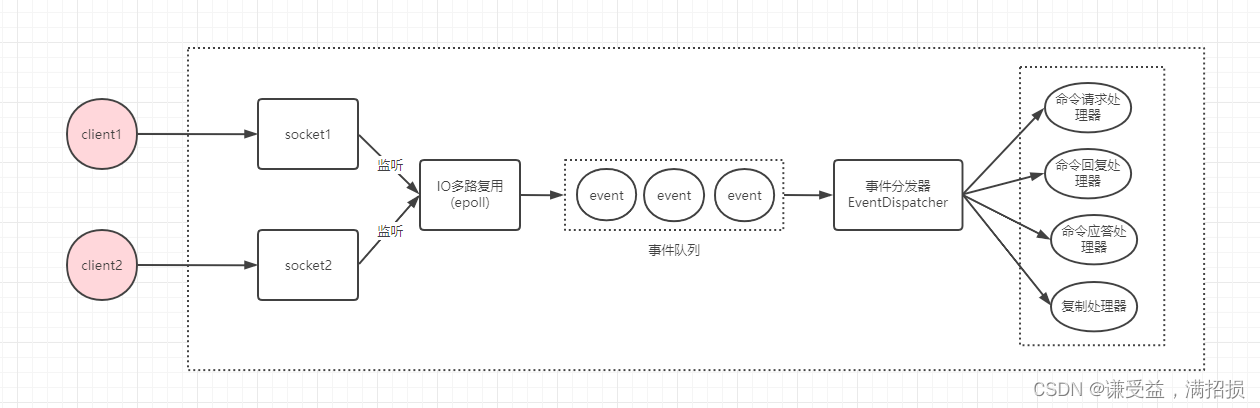
采用Reactor的网络设计模式,而不用Proactor模式的原因,是因为redis的client客户端其实也就微服务所在的服务器,连接数并不算太多,而Proactor是异步IO,适合连接数比较多的极致网络传输需求,并且,和上述redis没必要用多线程处理一样的原因,Proactor的异步IO会创建大量内核态线程,带来大量服务器的资源开销和性能占用,没有必要。
上述解析是吧redis一直沿用单线程处理业务的原因讲完了。那么redis事务和Lua脚本有什么区别?
redis的事务:

事务包含三个阶段:
- 事务开启,使用 MULTI , 该命令标志着执行该命令的客户端从非事务状态切换至事务状态 ;
- 命令入队,MULTI 开启事务之后,客户端的命令并不会被立即执行,而是放入一个事务队列
- 执行事务或者丢弃。如果收到 EXEC 的命令,事务队列里的命令将会被执行 ,如果是 DISCARD 则事务被丢弃。
Redis的事务模式具备如下特点:
- 保证隔离性;
- 无法保证持久性;
- 具备了一定的原子性,但不支持完全回滚,所以原子性其实是不具备的;
- 在加watch情况下具备一致性,因为在事务开启的时候,其他事务是可以修改同一数据的。加watch辅助,可以回滚全部的冲突操作,但是因为异常不是因为错误引起的回滚,事务不能完全回滚,所以一致性也是有争议的。
所以严格来说,其实redis的事务只具备隔离性这一条了,而且是因为事务开启后,没有发出提交指令之前,所有操作都只是入队操做,并没有对redis内存数据做任何修改,其他的事务当然是看不到了,因为这个原因保证了事务的隔离性。那redis的事务看起来确实太弱了,就是保证了多条指令的打包操作,不允许其他指令穿插进来而已。确实只有这个作用了。
还是将实践操作的过程贴出来一下吧。

在事务执行 EXEC 命令之前 ,Redis key 依然可以被修改。
在事务开启之前,我们可以 watch 命令监听 Redis key 。在B事务执行之前,A事务我们修改 key 值 ,B事务执行失败,返回 nil 。
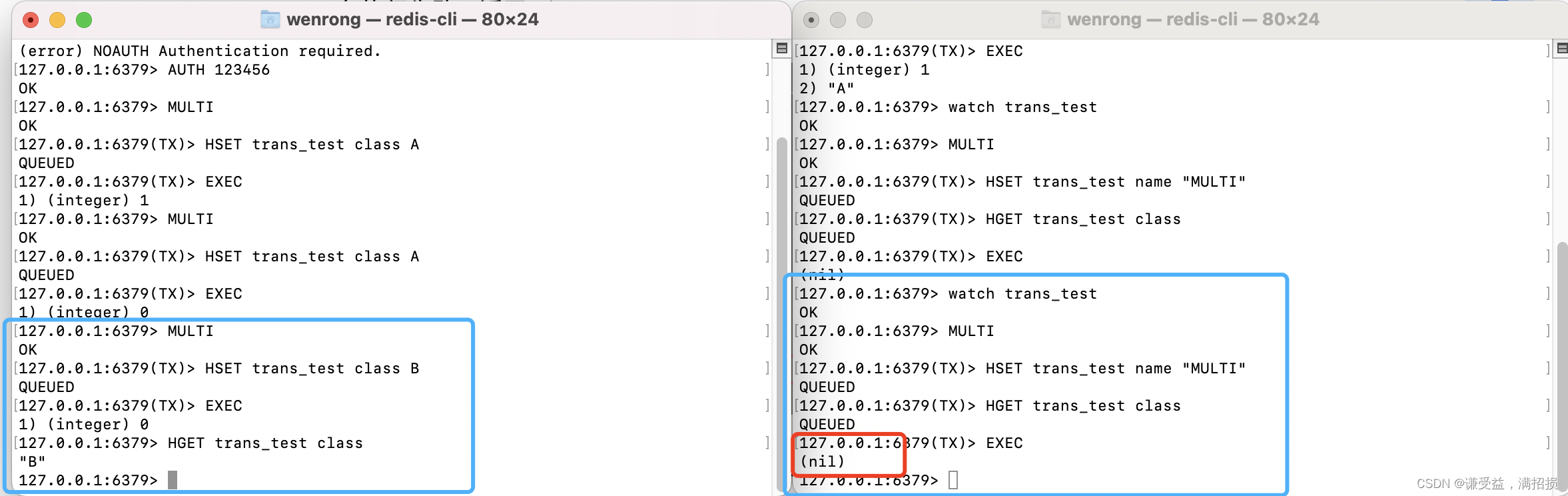
加了watch之后,可以解决这个问题。
Lua脚本:
从 Redis 2.6.0 版本开始, Redis内置的 Lua 解释器,可以实现在 Redis 中运行 Lua 脚本。
使用 Lua 脚本的好处 :
- 减少网络开销。将多个请求通过脚本的形式一次发送,减少网络时延。
- 原子操作。Redis会将整个脚本作为一个整体执行,中间不会被其他命令插入。
- 复用。客户端发送的脚本会永久存在 Redis 中,其他客户端可以复用这一脚本而不需要使用代码完成相同的逻辑。
从定义上来说, Redis 中的脚本本身就是一种事务, 所以任何在事务里可以完成的事, 在脚本里面也能完成。 并且一般来说, 使用脚本要来得更简单,并且速度更快。因为脚本可以缓存起来,可以复用,不用重复传输。
因为脚本功能是 Redis 2.6 才引入的, 而事务功能则更早之前就存在了, 所以 Redis 才会同时存在两种处理事务的方法。
因为事务提供了一种即使不使用脚本, 也可以避免竞争条件的方法, 而且事务本身的实现并不复杂。事务在某种情况下是可以完全回滚的,Lua脚本做不到。
- Lua 脚本是另一种形式的事务,他具备一定的原子性,但脚本报错的情况下,事务并不会回滚。
- Lua 脚本可以保证隔离性,而且可以完美的支持后面的步骤依赖前面步骤的结果。
而Redisson实现的分布式锁的基础就是依赖于Lua脚本,运用了Lua脚本的原子性,而redis单个指令本来就是串行的,所以获取锁的过程可以说是一种乐观锁,所有的乐观锁CAS操作都是发起方可以多线程,多请求并发,但在核心数据修改的步骤,是原子性,并且是串行执行的。
Lua脚本支持后面的步骤依赖前面的结果,比如里面有条件判断。
Lua脚本可以缓存,节省了网络资源的开销。
最后几个问题也可以讨论下:
假如加持分布式锁的业务方法,里面的逻辑没有数据库修改,没有较多的业务运算,只有可以在脚本里完成的更新缓存的几步操作,那么是不是就可以不用Redisson的可重入锁的加锁解锁保证原子性和串行执行?
不用锁,只用Lua脚本这种多指令打包,原子性操作方式是可以实现的。并且脚本里也可以实现一些简单的计算逻辑。但是大多数业务方法,就算不更新数据库,也会有复杂的业务逻辑处理的,这些光靠脚本是不可能实现的。所以分布式锁的重要性不可取代。
最后同样是这个某某居公司的高级开发问我,你们在下订单的时候,为了提升速度,只更新缓存,数据库放到后面再更新,不更新数据库是非常不负责任的做法。
我又感到奇怪了,用消息队列,滞后异步更新数据库数据是削峰填谷而已,又不是真的不更新数据库。怎么就是不负责任了?难道缓存就真的只用于下单前,放进购物车的时候,库存的快速查询吗?下单阻塞时间长,一样是不可接受的吧?
Ok,那假如就按照他所说的,来考虑缓存更新和数据库更新放在一起处理时候会出现哪些问题,又有哪些解决方案。
假如,先更新缓存,不成功,就直接结束整个业务方法,成功后再来更新数据库,缓存更新成功,数据库更新失败了,数据库操作可以依赖数据库事务回滚掉,但是缓存的更新请求是已经提交了,这需要做数据回退补偿操作,代码复杂度会大大增加。同样也需要在分布式锁加持的前提下操作,在回退之前,分布式锁不可以释放。这不用担心其他业务方法,访问到了将要回退的数据。
先更新数据库,数据库更新失败,同样直接结束方法。数据库更新成功后,缓存更新失败了,直接抛出异常,数据库依赖事务做回滚。
对比起来,先更新数据库的方案会更好一点。但不管哪一种方式,都不能提前释放掉分布式锁,所以,既然用了缓存了,何必要降数据库的更新和缓存在一起操作呢?除非是对下单阻塞可以忍受,仅仅要求在商品浏览的时候有一个高性能查询的应用场景。
下一篇,我会接着讲一下redisson实现的MultiLock、RedLock分布式锁,出现脑裂情况该怎么解决。
如果你觉得我的博客内容对你有帮助,请关注我,更多的学习资料,源码解析,设计思想,方案推陈,都可以与你分享,共同进步。




















 1898
1898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











