






 本文深入探讨了Java开发中的关键概念,包括JDK、JRE和JVM的关系与作用,阐述了它们在Java程序开发和运行中的不同职责。此外,介绍了Math.round()方法的四舍五入规则,以及Java中的面向对象编程思想。文章还详细讲解了线程的创建方式、线程池的工作原理和线程安全,强调了防止死锁的策略。最后,讨论了防止SQL注入的方法、HTTP的GET和POST请求的区别,并分析了线程池的七大参数及其意义。
本文深入探讨了Java开发中的关键概念,包括JDK、JRE和JVM的关系与作用,阐述了它们在Java程序开发和运行中的不同职责。此外,介绍了Math.round()方法的四舍五入规则,以及Java中的面向对象编程思想。文章还详细讲解了线程的创建方式、线程池的工作原理和线程安全,强调了防止死锁的策略。最后,讨论了防止SQL注入的方法、HTTP的GET和POST请求的区别,并分析了线程池的七大参数及其意义。
1、JDK 、JRE和JVM 是什么?
- JDK: java development kit, java开发工具包,用来开发Java程序的,针对java开发者。
- JRE: java runtime environment, java运行时环境,针对java用户
- JVM: java virtual machine,java虚拟机 用来解释执行字节码文件(class文件)的。
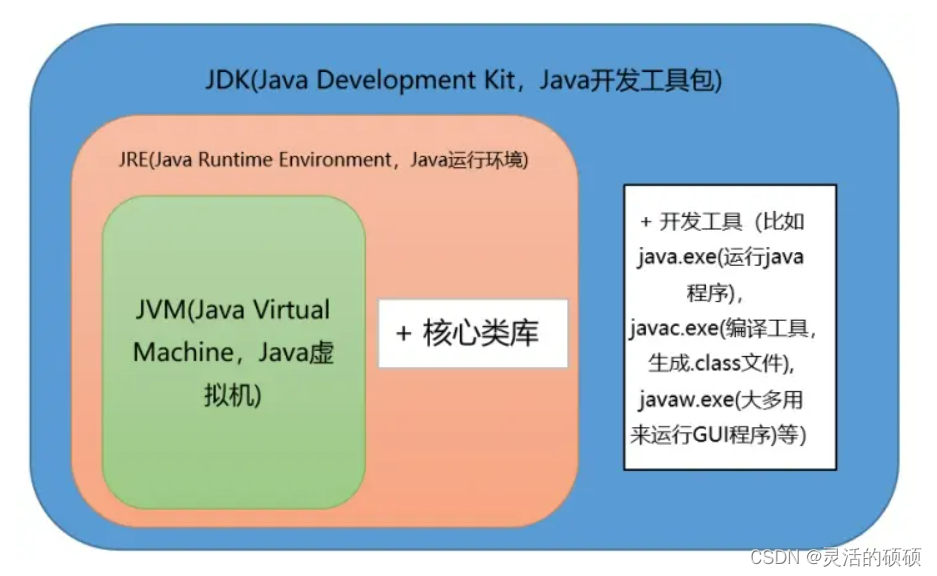
JDK
JDK(Java SE Development Kit),Java标准开发包,它提供了编译、运行Java程序所需的各种工具和资源,包括Java编译器、Java运行时环境,以及常用的Java类库等。
JRE
JRE( Java Runtime Environment) 、Java运行环境,用于解释执行Java的字节码文件。普通用户而只需要安装 JRE(Java Runtime Environment)来运行 Java 程序。而程序开发者必须安装JDK来编译、调试程序。
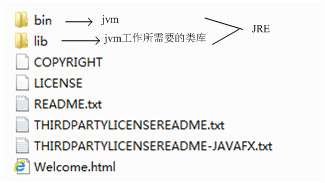
下图是JRE的安装目录:里面有两个文件夹bin和lib,在这里可以认为bin里的就是jvm,lib中则是jvm工作所需要的类库,而jvm和 lib和起来就称为jre。
JVM
JVM(Java Virtual Mechinal),Java虚拟机,是JRE的一部分。它是整个java实现跨平台的最核心的部分,负责解释执行字节码文件,是可运行java字节码文件的虚拟计算机。所有平台的上的JVM向编译器提供相同的接口,而编译器只需要面向虚拟机,生成虚拟机能识别的代码,然后由虚拟机来解释执行。
当使用Java编译器编译Java程序时,生成的是与平台无关的字节码,这些字节码只面向JVM。不同平台的JVM都是不同的,但它们都提供了相同的接口。JVM是Java程序跨平台的关键部分,只要为不同平台实现了相应的虚拟机,编译后的Java字节码就可以在该平台上运行。

2、JDK 、JRE和JVM 有什么区别和关系?
- JDK 用于开发,JRE 用于运行java程序 ;如果只是运行Java程序,可以只安装JRE,无序安装JDK。
- JDk包含JRE,JDK 和 JRE 中都包含 JVM。
- JVM 是 java 编程语言的核心并且具有平台独立性。
3、java 中的 Math.round(-1.5) 等于多少?
round( ):
它表示四舍五入,算法为 Math.floor(x+0.5),即将原来的数字加上 0.5 后再向下取整,所以,Math.round(11.5) 的结果为12,Math.round(-11.5) 的结果为-11。
Math提供了三个与取整有关的方法:ceil、floor、round
(1)ceil:向上取整;
- Math.ceil(11.3) = 12;
- Math.ceil(-11.3) = 11;
(2)floor:向下取整;
- Math.floor(11.3) = 11;
- Math.floor(-11.3) = -12;
(3)round:四舍五入;
加0.5然后向下取整。
- Math.round(11.3) = 11;
- Math.round(11.8) = 12;
- Math.round(-11.3) = -11;
- Math.round(-11.8) = -12;
4、什么是面向对象
面向对象是一种思想,是基于面向过程而言的,就是说面向对象是将功能等通过对象来实现,将功能封装进对象之中,让对象去实现具体的细节。
对比面向过程,是两种不同的处理问题角度。
面向过程更注重事情的每一步骤和顺序,而面向对象更注重事情有哪些参与者(对象)、以及各自需要做些什么。
例如:冰箱装大象
面向过程会将任务分解成一系列的步骤(函数):
1. 打开冰箱
2. 把大象装进去
3. 关上冰箱
面向对象会分解成两个对象:
冰箱: 存放大象 打开冰箱 关上冰箱
大象 : 进入冰箱
从这个例子可以看出,面向过程比较直接高效,而面向对象更易于复用、扩展和维护。
5、&和&&的区别?
& 按位运算符; 逻辑运算符
作为逻辑运算符时,&左右两端条件式有一个为假就会不成立,但是两端都会运行,比如(1+2)=4 &(1+2)=3;1+2=4即使为假也会去判断1+2=3是否成立。
&&——逻辑运算符
&&也叫做短路运算符,因为只要左端条件式为假直接不成立,不会去判断右端条件式。
同点:只要有一端为假,则语句不成立
6、用最有效率的方法计算2乘以8?
2 << 3(左移3位相当于乘以2的3次方,右移3位相当于除以2的3次方)
7、数组有没有length()方法?String有没有length()方法?
数组没有length()方法,有length 的属性。String 有length()方法。JavaScript中,获得字符串的长度是通过length属性得到的,这一点容易和Java混淆。
8.守护线程是什么?
守护线程(即daemon thread),是个服务线程,准确地来说就是服务其他的线程。
9. 并行和并发有什么区别?
并行:不同实体上,两个或多个事件在同一时刻发生
并发:同一实体上,两个或多个事件在同一时刻间隔发生
总结:并发编程的目标是充分的利用处理器的每一个核,以达到最高的处理性能
10.创建线程有哪几种方式?
①. 继承Thread类创建线程类
-
定义Thread类的子类,并重写该类的run方法,该run方法的方法体就代表了线程要完成的任务。因此把run()方法称为执行体。
-
创建Thread子类的实例,即创建了线程对象。
-
调用线程对象的start()方法来启动该线程。
②. 通过Runnable接口创建线程类
-
定义runnable接口的实现类,并重写该接口的run()方法,该run()方法的方法体同样是该线程的线程执行体。
-
创建 Runnable实现类的实例,并依此实例作为Thread的target来创建Thread对象,该Thread对象才是真正的线程对象。
-
调用线程对象的start()方法来启动该线程。
③. 通过Callable和Future创建线程
-
创建Callable接口的实现类,并实现call()方法,该call()方法将作为线程执行体,并且有返回值。
-
创建Callable实现类的实例,使用FutureTask类来包装Callable对象,该FutureTask对象封装了该Callable对象的call()方法的返回值。
-
使用FutureTask对象作为Thread对象的target创建并启动新线程。
-
调用FutureTask对象的get()方法来获得子线程执行结束后的返回值。
11.说一下 runnable 和 callable 有什么区别?
-
Runnable接口中的run()方法的返回值是void,它做的事情只是纯粹地去执行run()方法中的代码而已;
-
Callable接口中的call()方法是有返回值的,是一个泛型,和Future、FutureTask配合可以用来获取异步执行的结果。
public class ThreadTest {
public static void main(String[] args) {
// RunnableThread thread = new RunnableThread();
// new Thread(thread).start();
CallableThread ct = new CallableThread();
FutureTask task = new FutureTask(ct);
new Thread(task).start();
}
static class RunnableThread implements Runnable{
@Override
public void run() {
System.out.println("Runnable======");
}
}
static class CallableThread implements Callable {
@Override
public Object call() throws Exception {
System.out.println(Thread.currentThread().getName());
return 0;
}
}
12.三种创建方式优缺点
- 使用Thread类
优点:编写相对简单,访问当前线程直接使用this就可以获得当前线程。
缺点:由于线程类已经继承了Thread类,所以不能再继承其他的父类。
- 使用Runnable接口
优点:没有继承Thread类,所以可以继承其他的类,适合多线程访问同一资源的情况,将cpu和数据分开,形成清晰的模型,较好的体现了面向对象的思想
缺点:编程相对复杂,要想获得当前线程对象,需要使用Thread.currentThread()方法。
- 使用callable接口
优点:也可以继承其他的类,多线程可以共享同一个target对象,适合多线程访问同一资源的情况,将cpu和数据分开,形成清晰的模型,较好的体现了面向对象的思想,还有返回值
缺点:编程稍显复杂,如果要访问当前线程,则必须使用Thread.currentThread()方法。
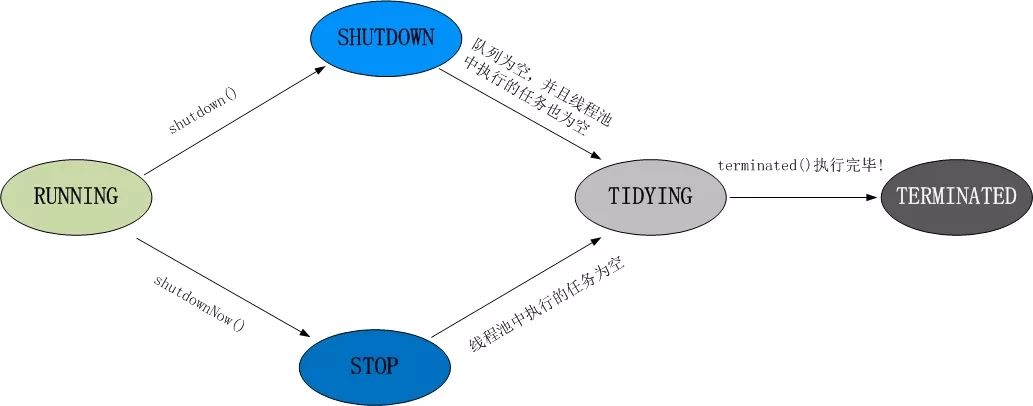
13. 线程池都有哪些状态?
线程池有5种状态:Running、ShutDown、Stop、Tidying、Terminated。
14.线程池中 submit()和 execute()方法有什么区别?
-
接收的参数不一样
-
submit有返回值,而execute没有
-
submit方便Exception处理
public class ThreadTest {
public static void main(String[] args) {
ExecutorService pool = Executors.newFixedThreadPool(4);
/**
* execute(Runnable x) 没有返回值。可以执行任务,但无法判断任务是否成功完成。
*/
pool.execute(new RunnableThread("Task1"));
/**
* submit(Runnable x) 返回一个future。可以用这个future来判断任务是否成功完成。请看下面:
*/
Future future = pool.submit(new RunnableThread("Task2"));
try {
if(future.get()==null){//如果Future's get返回null,任务完成
System.out.println("任务完成");
}
} catch (InterruptedException e) {
} catch (ExecutionException e) {
//否则我们可以看看任务失败的原因是什么
System.out.println(e.getCause().getMessage());
}
}
static class RunnableThread implements Runnable{
private String taskName;
public RunnableThread(final String taskName) {
this.taskName = taskName;
}
@Override
public void run() {
System.out.println("Runnable======");
}
}
}
15. 在 java 程序中怎么保证多线程的运行安全?
线程安全在三个方面体现:
-
原子性:提供互斥访问,同一时刻只能有一个线程对数据进行操作,(atomic,synchronized);
-
可见性:一个线程对主内存的修改可以及时地被其他线程看到,(synchronized,volatile);
-
有序性:一个线程观察其他线程中的指令执行顺序,由于指令重排序,该观察结果一般杂乱无序,(happens-before原则)。
16.多线程锁的升级原理是什么?
在Java中,锁共有4种状态,级别从低到高依次为:无状态锁,偏向锁,轻量级锁和重量级锁状态,这几个状态会随着竞争情况逐渐升级。锁可以升级但不能降级。
锁升级的图示过程:
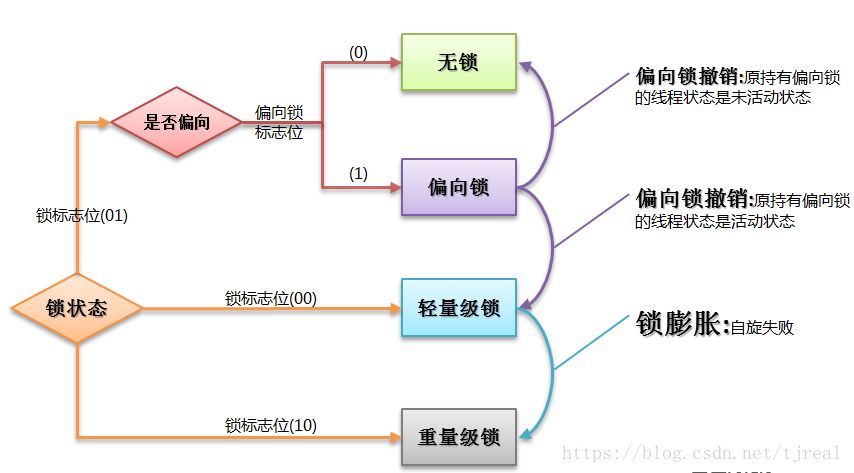
17.什么是死锁?
死锁是指两个或两个以上的进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。是操作系统层面的一个错误,是进程死锁的简称,最早在 1965 年由 Dijkstra 在研究银行家算法时提出的,它是计算机操作系统乃至整个并发程序设计领域最难处理的问题之一。
18.怎么防止死锁?
死锁的四个必要条件:
-
互斥条件:进程对所分配到的资源不允许其他进程进行访问,若其他进程访问该资源,只能等待,直至占有该资源的进程使用完成后释放该资源
-
请求和保持条件:进程获得一定的资源之后,又对其他资源发出请求,但是该资源可能被其他进程占有,此事请求阻塞,但又对自己获得的资源保持不放
-
不可剥夺条件:是指进程已获得的资源,在未完成使用之前,不可被剥夺,只能在使用完后自己释放
-
环路等待条件:是指进程发生死锁后,若干进程之间形成一种头尾相接的循环等待资源关系
这四个条件是死锁的必要条件,只要系统发生死锁,这些条件必然成立,而只要上述条件之 一不满足,就不会发生死锁。
19.说一下 synchronized 底层实现原理?
synchronized可以保证方法或者代码块在运行时,同一时刻只有一个方法可以进入到临界区,同时它还可以保证共享变量的内存可见性。
Java中每一个对象都可以作为锁,这是synchronized实现同步的基础:
-
普通同步方法,锁是当前实例对象
-
静态同步方法,锁是当前类的class对象
-
同步方法块,锁是括号里面的对象
20.为什么要使用克隆?
想对一个对象进行处理,又想保留原有的数据进行接下来的操作,就需要克隆了,Java语言中克隆针对的是类的实例。
21.如何实现对象克隆?
1). 实现Cloneable接口并重写Object类中的clone()方法;
2). 实现Serializable接口,通过对象的序列化和反序列化实现克隆,可以实现真正的深度克隆,代码如下:
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
public class MyUtil {
private MyUtil() {
throw new AssertionError();
}
@SuppressWarnings("unchecked")
public static <T extends Serializable> T clone(T obj) throws Exception {
ByteArrayOutputStream bout = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bout);
oos.writeObject(obj);
ByteArrayInputStream bin = new ByteArrayInputStream(bout.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bin);
return (T) ois.readObject();
// 说明:调用ByteArrayInputStream或ByteArrayOutputStream对象的close方法没有任何意义
// 这两个基于内存的流只要垃圾回收器清理对象就能够释放资源,这一点不同于对外部资源(如文件流)的释放
}
}
import java.io.Serializable;
/**
* 人类
*/
class Person implements Serializable {
private static final long serialVersionUID = -9102017020286042305L;
private String name; // 姓名
private int age; // 年龄
private Car car; // 座驾
public Person(String name, int age, Car car) {
this.name = name;
this.age = age;
this.car = car;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Car getCar() {
return car;
}
public void setCar(Car car) {
this.car = car;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + ", car=" + car + "]";
}
}
/**
* 汽车类
*/
class Car implements Serializable {
private static final long serialVersionUID = -5713945027627603702L;
private String brand; // 品牌
private int maxSpeed; // 最高时速
public Car(String brand, int maxSpeed) {
this.brand = brand;
this.maxSpeed = maxSpeed;
}
public String getBrand() {
return brand;
}
public void setBrand(String brand) {
this.brand = brand;
}
public int getMaxSpeed() {
return maxSpeed;
}
public void setMaxSpeed(int maxSpeed) {
this.maxSpeed = maxSpeed;
}
@Override
public String toString() {
return "Car [brand=" + brand + ", maxSpeed=" + maxSpeed + "]";
}
}
class CloneTest {
public static void main(String[] args) {
try {
Person p1 = new Person("郭靖", 33, new Car("Benz", 300));
Person p2 = MyUtil.clone(p1); // 深度克隆
p2.getCar().setBrand("BYD");
// 修改克隆的Person对象p2关联的汽车对象的品牌属性
// 原来的Person对象p1关联的汽车不会受到任何影响
// 因为在克隆Person对象时其关联的汽车对象也被克隆了
System.out.println(p1);
} catch (Exception e) {
e.printStackTrace();
}
}
}
注意:基于序列化和反序列化实现的克隆不仅仅是深度克隆,更重要的是通过泛型限定,可以检查出要克隆的对象是否支持序列化,这项检查是编译器完成的,不是在运行时抛出异常,这种是方案明显优于使用Object类的clone方法克隆对象。让问题在编译的时候暴露出来总是好过把问题留到运行时
22.说一下 session 的工作原理?
其实session是一个存在服务器上的类似于一个散列表格的文件。里面存有我们需要的信息,在我们需要用的时候可以从里面取出来。类似于一个大号的map吧,里面的键存储的是用户的sessionid,用户向服务器发送请求的时候会带上这个sessionid。这时就可以从中取出对应的值了。
23.如何避免 sql 注入?
-
PreparedStatement(简单又有效的方法)
-
使用正则表达式过滤传入的参数
-
字符串过滤
-
JSP中调用该函数检查是否包函非法字符
-
JSP页面判断代码
24.get 和 post 请求有哪些区别?
-
GET在浏览器回退时是无害的,而POST会再次提交请求。
-
GET产生的URL地址可以被Bookmark,而POST不可以。
-
GET请求会被浏览器主动cache,而POST不会,除非手动设置。
-
GET请求只能进行url编码,而POST支持多种编码方式。
-
GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。
-
GET请求在URL中传送的参数是有长度限制的,而POST么有。
-
对参数的数据类型,GET只接受ASCII字符,而POST没有限制。
-
GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。
-
GET参数通过URL传递,POST放在Request body中。
25.线程池七大参数分别是什么?
线程池七大参数分别是corePoolSize、maximumPoolSize、keepAliveTime、unit、workQueue、threadFactory、handler
(1)corePoolSize:线程池中常驻核心线程数
(2)maximumPoolSize:线程池能够容纳同时执行的最大线程数
(3)keepAliveTime:多余的空闲线程存活时间
(4)unit:keepAliveTime的时间单位
(5)workQueue:任务队列,被提交但尚未执行的任务
(6)threadFactory:表示生成线程池中的工作线程的线程工厂
(7)handler:拒绝策略,表示当队列满了并且工作线程大于等于线程池的最大线程数(maximumPoolSize)时如何拒绝。

















 2741
2741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









