







数据分析与挖掘中常用Python库的介绍与实践案例
一、Python介绍
现在python一词对我们来说并不陌生,尤其是在学术圈,它的影响力远超其它任何一种编程语言, 作为一门简单易学且功能强大的编程语言,它拥有丰富的第三方库,在许多方面都有着广泛的应用,如网站开发、游戏开发、网络爬虫、数据分析、机器学习等。 (更多内容,可参阅程序员在旅途)
在数据分析方面,python拥有Numpy、SciPy、Pandas、Matplotlib等功能强大的模块可供使用。随着这些模块的逐步完善,python在科学领域的地位越来越重要,这其中包括科学计算、数学建模、数据挖掘等。因此,掌握这些模块的基本使用方法至关重要,下面就逐一介绍下。
二、常用库的使用示例
2.1 NumPy 库:
NumPy(官网)提供了N维数组功能以及对数据进行快速处理的能力,弥补了Python本身没有提供数组功能的缺陷。其提供了两种基本的对象:ndarray和ufunc。ndarray是存储单一数据类型的多维数组,而ufunc是能够对数组进行处理的函数(ufunc(通用函数)是一种对ndarray中的数据执行元素级运算的函数)。它也是SciPy、Pandas、Matplotlib的基础依赖库。
ndarray:N维数组对象(矩阵),所有元素数据类型必须是相同的。
ndarray属性:ndim属性,表示维度的个数;shape属性,表示各维度得大小;dtype属性,表示数据类型。
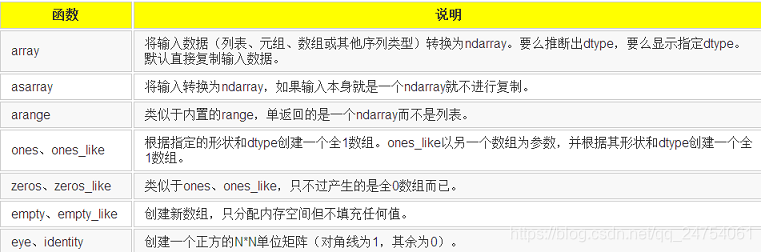
创建ndarray数组的函数如下图:
代码示例:
import numpy as np
# 一维数组示例
a = np.arra 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1734
1734

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









