







文章目录
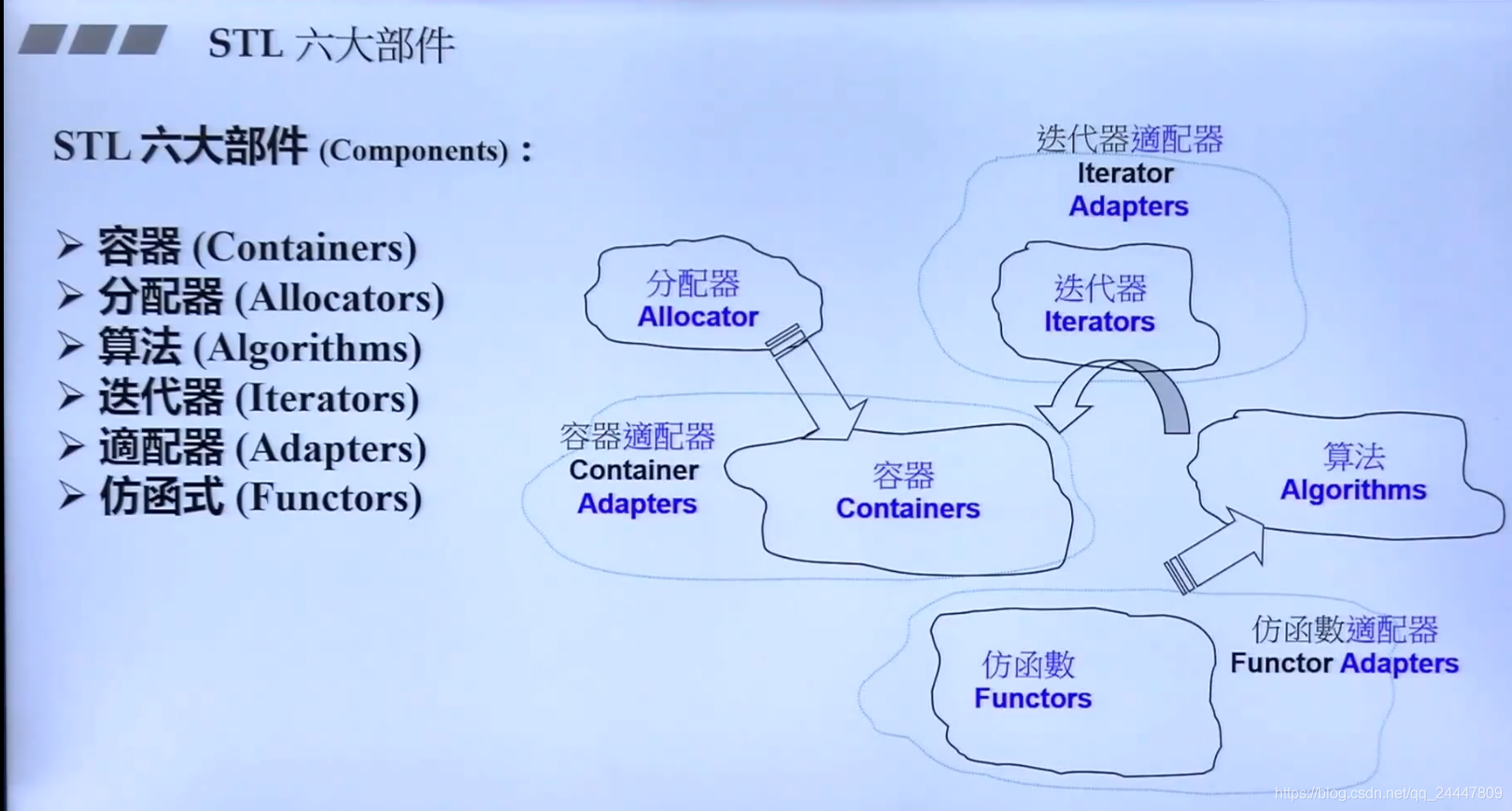
STL总体架构
迭代器iterator
无论是序列容器还是关联容器,最常做的操作无疑是遍历容器中存储的元素,而实现此操作,多数情况会选用“迭代器(iterator)”来实现。那么,迭代器到底是什么呢?
我们知道,尽管不同容器的内部结构各异,但它们本质上都是用来存储大量数据的,换句话说,都是一串能存储多个数据的存储单元。因此,诸如数据的排序、查找、求和等需要对数据进行遍历的操作方法应该是类似的。
既然类似,完全可以利用泛型技术,将它们设计成适用所有容器的通用算法,从而将容器和算法分离开。但实现此目的需要有一个类似中介的装置,它除了要具有对容器进行遍历读写数据的能力之外,还要能对外隐藏容器的内部差异,从而以统一的界面向算法传送数据。
这是泛型思维发展的必然结果,于是迭代器就产生了。简单来讲,迭代器和 C++ 的指针非常类似,它可以是需要的任意类型,通过迭代器可以指向容器中的某个元素,如果需要,还可以对该元素进行读/写操作。
常用的迭代器按功能强弱分为输入迭代器、输出迭代器、前向迭代器、双向迭代器、随机访问迭代器 5 种

测试各个迭代器的函数
//---------------------------------------------------
#include <iostream> // std::cout
#include <iterator> // std::iterator_traits
#include <typeinfo> // typeid
#include <forward_list>
#include<unordered_map>
#include<map>
#include<unordered_set>
namespace jj33
{
void _display_category(random_access_iterator_tag)
{
cout << "random_access_iterator" << endl;
}
void _display_category(bidirectional_iterator_tag)
{
cout << "bidirectional_iterator" << endl;
}
void _display_category(forward_iterator_tag)
{
cout << "forward_iterator" << endl;
}
void _display_category(output_iterator_tag)
{
cout << "output_iterator" << endl;
}
void _display_category(input_iterator_tag)
{
cout << "input_iterator" << endl;
}
template<typename I>
void display_category(I itr)
{
typename iterator_traits<I>::iterator_category cagy;
_display_category(cagy);
cout << "typeid(itr).name()= " << typeid(itr).name() << endl << endl;
//The output depends on library implementation.
//The particular representation pointed by the
//returned valueis implementation-defined,
//and may or may not be different for different types.
}
void test_iterator_category()
{
cout << "\ntest_iterator_category().......... \n";
display_category(array<int, 10>::iterator());
display_category(vector<int>::iterator());
display_category(list<int>::iterator());
display_category(forward_list<int>::iterator());
display_category(deque<int>::iterator());
display_category(set<int>::iterator());
display_category(map<int, int>::iterator());
display_category(multiset<int>::iterator());
display_category(multimap<int, int>::iterator());
display_category(unordered_set<int>::iterator());
display_category(unordered_map<int, int>::iterator());
display_category(unordered_multiset<int>::iterator());
display_category(unordered_multimap<int, int>::iterator());
display_category(istream_iterator<int>());
display_category(ostream_iterator<int>(cout, ""));
}
}
//---------------------------------------------------
迭代器传入参数
共5个必须参数,
参数1:iterator_category 标记迭代器种类,此例为输入迭代器
参数2:value_type 迭代器指向的数据类型
参数3:difference_type 数据类型之间的距离,
参数4:pointer 迭代器指向的数据类型指针
参数5:reference 迭代器指向的数据类型引用
下面是迭代器的定义源码
struct input_iterator_tag {};
struct output_iterator_tag {};
struct forward_iterator_tag : public input_iterator_tag {};
struct bidirectional_iterator_tag : public forward_iterator_tag {};
struct random_access_iterator_tag : public bidirectional_iterator_tag {};
template <class T, class Distance> struct input_iterator {
typedef input_iterator_tag iterator_category; //参数1:标记迭代器种类,此例为输入迭代器
typedef T value_type; //参数2:迭代器指向的数据类型
typedef Distance difference_type; //参数3:数据类型之间的距离,比如vector<int>中,int类型间隔为4
typedef T* pointer; //参数4:迭代器指向的数据类型指针
typedef T& reference; //参数5:迭代器指向的数据类型引用
};
//下面代码都遵循这种格式
struct output_iterator {
typedef output_iterator_tag iterator_category;
typedef void value_type;
typedef void difference_type;
typedef void pointer;
typedef void reference;
};
template <class T, class Distance> struct forward_iterator {
typedef forward_iterator_tag iterator_category;
typedef T value_type;
typedef Distance difference_type;
typedef T* pointer;
typedef T& reference;
};
template <class T, class Distance> struct bidirectional_iterator {
typedef bidirectional_iterator_tag iterator_category;
typedef T value_type;
typedef Distance difference_type;
typedef T* pointer;
typedef T& reference;
};
template <class T, class Distance> struct random_access_iterator {
typedef random_access_iterator_tag iterator_category;
typedef T value_type;
typedef Distance difference_type;
typedef T* pointer;
typedef T& reference;
};
算法algorithm
算法需要知道传入的迭代器信息,才能决定采取什么样的方式行动。

distance算法
以distance为例:假设传入的是vector< int> 的iterator
template <class InputIterator>
inline iterator_traits<InputIterator>::difference_type //返回迭代器的间隔距离
distance(InputIterator first, InputIterator last) { //遵循前闭后开标准
typedef typename iterator_traits<InputIterator>::iterator_category category;
//category代表迭代器种类,vector的是random_access_iterator_tag
//iterator_traits叫做萃取器,可以提取出iterator中的属性信息,详细见下
return __distance(first, last, category()); //构造一个临时对象category()
}
__distance有多个版本,根据传入的迭代器种类不同,执行不同函数
template <class InputIterator>
inline iterator_traits<InputIterator>::difference_type
__distance(InputIterator first, InputIterator last, input_iterator_tag) {
//实际因为继承关系(input_iterator_tag是老祖宗),所有不是random_access_iterator_tag的迭代器类型执行这个函数
iterator_traits<InputIterator>::difference_type n = 0;
while (first != last) { //像链表指针就只能一步步++找next节点,最后统计走过多少个节点n
++first; ++n;
}
return n;
}
template <class RandomAccessIterator>
inline iterator_traits<RandomAccessIterator>::difference_type
__distance(RandomAccessIterator first, RandomAccessIterator last,
random_access_iterator_tag) { //random_access_iterator_tag迭代器执行此函数
return last - first;
//能支持随机存储的迭代器,必然内存空间连续(deque虽然实际上不连续,但迭代器重载+-运算符,在计算表现中是连续的)
//一般是两个指针,相减自然得到两者距离
}
iterator_traits 萃取器
萃取器可以提取出iterator的相应属性,提供给算法
template <class Iterator> //根据传入的iterator得到算法必需的5个参数
struct iterator_traits {
typedef typename Iterator::iterator_category iterator_category;
typedef typename Iterator::value_type value_type;
typedef typename Iterator::difference_type difference_type;
typedef typename Iterator::pointer pointer;
typedef typename Iterator::reference reference;
};
template <class T>
struct iterator_traits<T*> { //偏特化版本,针对数据指针如迭代器是int*的情况
typedef random_access_iterator_tag iterator_category;
typedef T value_type;
typedef ptrdiff_t difference_type;
typedef T* pointer;
typedef T& reference;
};
template <class T>
struct iterator_traits<const T*> { //偏特化版本
typedef random_access_iterator_tag iterator_category;
typedef T value_type;
typedef ptrdiff_t difference_type;
typedef const T* pointer;
typedef const T& reference;
};
仿函数 Functor
有的算法有多个可用版本,可以加入自己的比较函数改变原来算法的执行效果


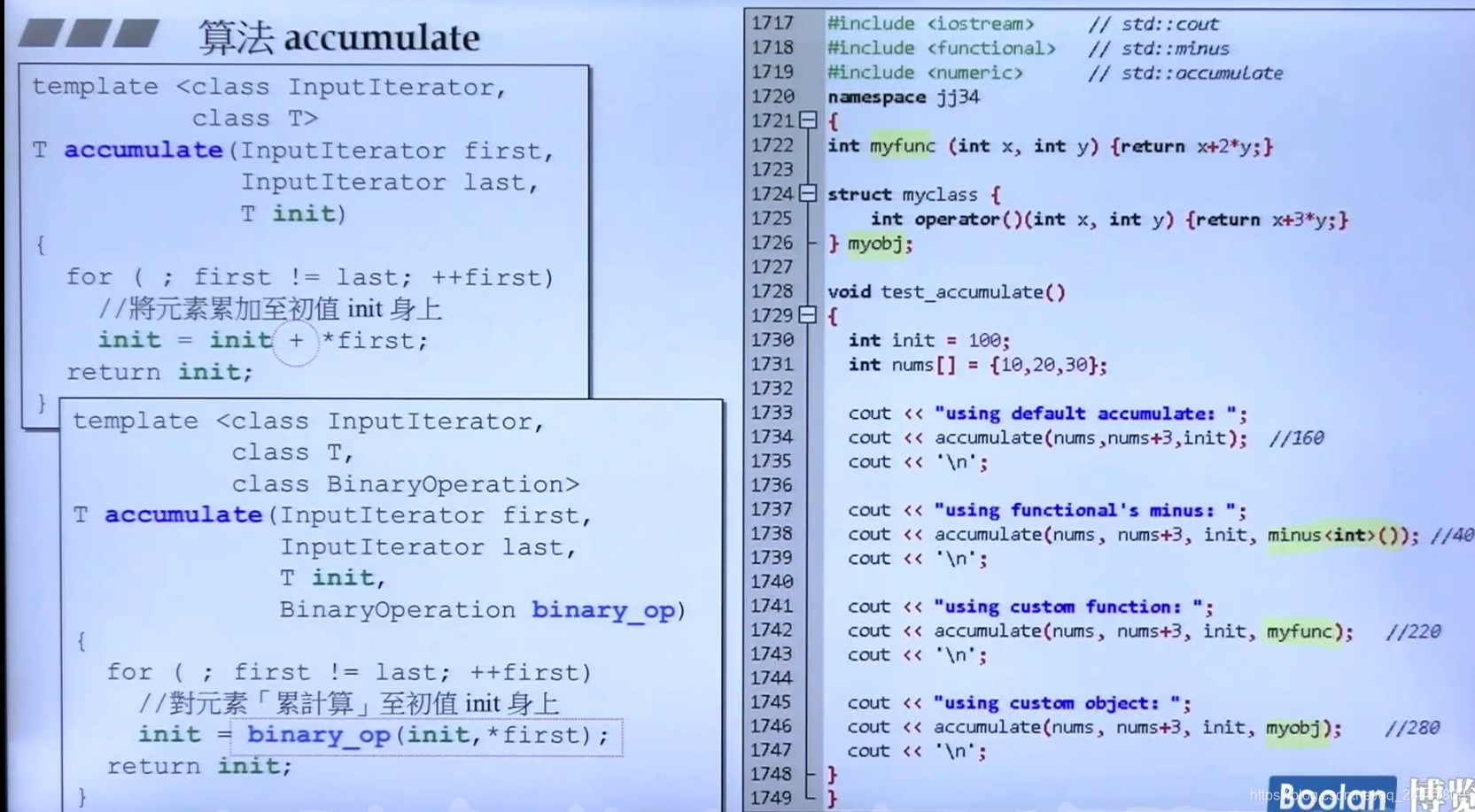
测试函数
#include<iostream>
#include <numeric>
int func(int x, int y)
{
return x + 2 * y;
}
struct testclass {
int operator()(int x, int y) { return x + 3 * y; };
}obj;
using namespace std;
int main()
{
int n = 100;
int num[] = { 10,40,60 };
cout << accumulate(num, num + 3,n,func);
return 0;
}
binary_function
(1)仿函数必须继承binary_function或者unary_function,因为在函数适配器中会针对父类中typedef的参数提问,详见下面的函数适配器解释。
(2)两个父类都是typedef,没有实际数据,所以子类继承没有额外空间开销。
(3)仿函数被称为函数对象,因为实际上是一个对象,表现的像个函数。

适配器adapters
本质上是一种中间工具,作为两边处理的一个桥梁,分为容器适配器、仿函数适配器、迭代器适配器
容器适配器
典型的比如set和map,作为一个中间过渡的适配器,所有的功能都是交给底层的红黑树去完成,其本质就是对红黑树容器的包装
以下是部分set源码
template <class Key, class Compare = less<Key>, class Alloc = alloc>
class set {
public:
// typedefs:
typedef Key key_type;
typedef Key value_type;
typedef Compare key_compare;
typedef Compare value_compare;
private:
typedef rb_tree<key_type, value_type,
identity<value_type>, key_compare, Alloc> rep_type; //红黑树申明
rep_type t; // red-black tree representing set //内部创建一颗红黑树
//....
iterator begin() const { return t.begin(); } //接口实现完全交给内部红黑树去做
iterator end() const { return t.end(); }
bool empty() const { return t.empty(); }
size_type size() const { return t.size(); }
}
函数适配器
总览图如下,其实也是对函数的封装处理,下面一一分析

less函数源码
其实是个函数类,继承了binary_function中的3个typedef,返回两个传入参数比较后的逻辑
template <class T>
struct less : public binary_function<T, T, bool> {
bool operator()(const T& x, const T& y) const { return x < y; }
};
template <class Arg1, class Arg2, class Result>
struct binary_function {
typedef Arg1 first_argument_type; //适配器会用到这些参数
typedef Arg2 second_argument_type;
typedef Result result_type;
};
1.函数总体解释
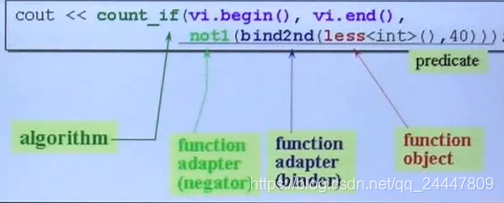
(1)count_if根据传入的判断函数统计整个区间内满足条件的个数,
(2)less见上面源码,返回参数比较后逻辑值
(3)bind2nd就是函数适配器,它把less< int >函数第二参数设为40,
(4)not1也是函数适配器,对结果取反。
(5)注意到less< int >(),括号中没有传入参数,怎么设置第二参数为40呢?看下面bind2nd的操作
2. bind2nd
一个辅助函数,可以帮我们自动推导传入的函数op对象的类Operation

(1)op就是传入的less< int>(),因为用了模板技术,Operation自动推导为less函数类
(2)less类继承了父类binary_function的 typedef,arg2_type代表Operation的第二参数类型,
这样做的好处提供一个报警功能,如果函数参数设置错误,比如设置为了40.5,在下面的arg2_type(x)中将会发生int(40.5),编译器会报出错误
typedef Arg2 second_argument_type; //代表第二参数,就是子类less的int类型
(3)数据包装后交给binder2nd,arg2_type(x)意思是创建一个临时对象,此例中是int(40)
3. binder2nd

(1)继续继承unary_function,所以它也能当仿函数使用,所以前面还能加个not1

(2)x是bind2nd传下来的op参数也就是less< int>() , y是参数arg2_type(40)就是40

(3)在pred中调用pred ( *first)函数时,就是在调用op(x,value),也就是调用less< int>( *first ,40)

4. not1

很简单,对传入的函数结果取反,本来的判断条件是小于40,!pred(x)后,变为不小于40,
迭代器适配器


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









