







 本文详细介绍了K-means聚类算法的工作原理,包括步骤、优点和缺点,以及k值的选择方法。此外,还讨论了初始点选择、数据归一化的重要性,以及K-means的适用性和不适用场景。最后,讲解了聚类效果的评估方法和空聚类的处理策略。
本文详细介绍了K-means聚类算法的工作原理,包括步骤、优点和缺点,以及k值的选择方法。此外,还讨论了初始点选择、数据归一化的重要性,以及K-means的适用性和不适用场景。最后,讲解了聚类效果的评估方法和空聚类的处理策略。
K-means面试题
1. 聚类算法(clustering Algorithms)介绍
聚类是一种无监督学习—对大量未知标注的数据集,按数据的内在相似性将数据集划分为多个类别,使类别内的数据相似度较大而类别间的数据相似度较小。
聚类算法可以分为原型聚类(k均值算法(K-means)、学习向量量化、(Learning Vector Quantization -LVQ)、高斯混合聚类(Mixture-of-Gaussian),密度聚类(DBSCAN),层次聚类(AGNES)等。
2. kmeans原理详解
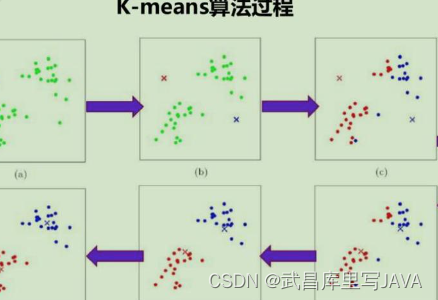
K-means是一种常见的聚类算法,也叫k均值或k平均。通过迭代的方式,每次迭代都将数据集中的各个点划分到距离它最近的簇内,这里的距离即数据点到簇中心的距离。
kmean步骤:
- 随机初始化k个簇中心坐标
- 计算数据集内所有点到k个簇中心的距离,并将数据点划分近最近的簇
- 更新簇中心坐标为当前簇内节点的坐标平均值
- 重复2、3步骤直到簇中心坐标不再改变(收敛了)
3. 优缺点及改进算法
优点:效率高、适用于大规模数据集
| 缺点 | 改进 | 描述 |
|---|---|---|
| k值的确定 | ISODATA | 当属于某个簇的样本数过少时把这个簇去除, 当属于某个簇的样本数过多、分散程度较大时把这个簇分为两个子簇 |
| 对奇异点敏感 | k-median | 中位数代替平均值作为簇中心 |
| 只能找到球状群 | GMM | 以高斯分布考虑簇内数据点的分布 |
| 分群结果不稳定 | K-means++ | 初始的聚类中心之间的相互距离要尽可能的远 |
4. k值的选取
K-means算法要求事先知道数据集能分为几群,主要有两种方法定义k。
-
手肘法:通过绘制k和损失函数的关系图,选拐点处的k值。
-
经验选取人工据经验先定几个k,多次随机初始化中心选经验上最适合的。
通常都是以经验选取,因为实际操作中拐点不明显,且手肘法效率不高。
5. K-means算法中初始点的选择对最终结果的影响
K-means选择的初始点不同获得的最终分类结果也可能不同,随机选择的中心会导致K-means陷入局部最优解。
6. 为什么在计算K-means之前要将数据点在各维度上归一化
因为数据点各维度的量级不同。
举个例子,最近正好做完基于RFM模型的会员分群,每个会员分别有R(最近一次购买距今的时长)、F(来店消费的频率)和M(购买金额)。如果这是一家奢侈品商店,你会发现M的量级(可能几万元)远大于F(可能平均10次以下),如果不归一化就算K-means,相当于F这个特征完全无效。如果我希望能把常客与其他顾客区别开来,不归一化就做不到。
7. K-means不适用哪些数据
- 数据特征极强相关的数据集,因为会很难收敛(损失函数是非凸函数),一般要用kernal K-means,将数据点映射到更高维度再分群。
- 数据集可分出来的簇密度不一,或有很多离群值(outliers),这时候考虑使用密度聚类。
8. K-means 中常用的距离度量
K-means中比较常用的距离度量是欧几里得距离和余弦相似度。
9. K-means是否会一直陷入选择质心的循环停不下来(为什么迭代次数后会收敛)?
从K-means的第三步我们可以看出,每回迭代都会用簇内点的平均值去更新簇中心,所以最终簇内的平方误差和(SSE, sum of squared error)一定最小。 平方误差和的公式如下:
L ( X ) = ∑ i = 1 k ∑ j ∈ C i ( x i j − x i ˉ ) 2 L(X) = \sum_{i=1}^{k}{\sum_{j\in C_i}{(x_{ij}-\bar{x_i})^2}} L(X)=i=1∑kj∈Ci∑(xij−xiˉ)2
10. 聚类和分类区别
- 产生的结果相同(将数据进行分类)
- 聚类事先没有给出标签(无监督学习)
11. 如何对K-means聚类效果进行评估
回到聚类的定义,我们希望得到簇内数据相似度尽可能地大&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 8125
8125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











