






使用Python解析HTML
在数据抓取和网页内容分析中,解析HTML是一个非常常见的任务。通过解析HTML,我们可以提取出所需的数据并进行进一步的处理或分析。Python提供了多种库来帮助我们完成这一任务,其中requests和lxml是非常常用的组合。
在这篇博客中,我们将学习如何使用requests库获取网页内容,并使用lxml库解析HTML,提取特定元素的内容。我们将通过一个具体的例子来展示如何从HTML文档中提取标题和表格中的数据。
为什么选择requests和lxml?
requests:用于发送HTTP请求,获取网页内容。它简单易用,适合初学者和专业人士。lxml:一个高效的XML和HTML解析库,支持XPath表达式,能够方便地提取所需的数据。
准备工作
在开始之前,请确保你的环境中已安装了requests和lxml库。如果尚未安装,可以通过以下命令进行安装:
pip install requests lxml
解析本地HTML文件示例
假设我们有一个名为html的本地HTML文件,其内容如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>测试页面</title>
</head>
<body>
<table border="1">
<thead>
<tr>
<th>姓名</th>
<th>年龄</th>
<th>城市</th>
</tr>
</thead>
<tbody>
<tr>
<td>张三</td>
<td>25</td>
<td>北京</td>
</tr>
<tr>
<td>李四</td>
<td>30</td>
<td>上海</td>
</tr>
<tr>
<td>王五</td>
<td>22</td>
<td>广州</td>
</tr>
</tbody>
</table>
</body>
</html>
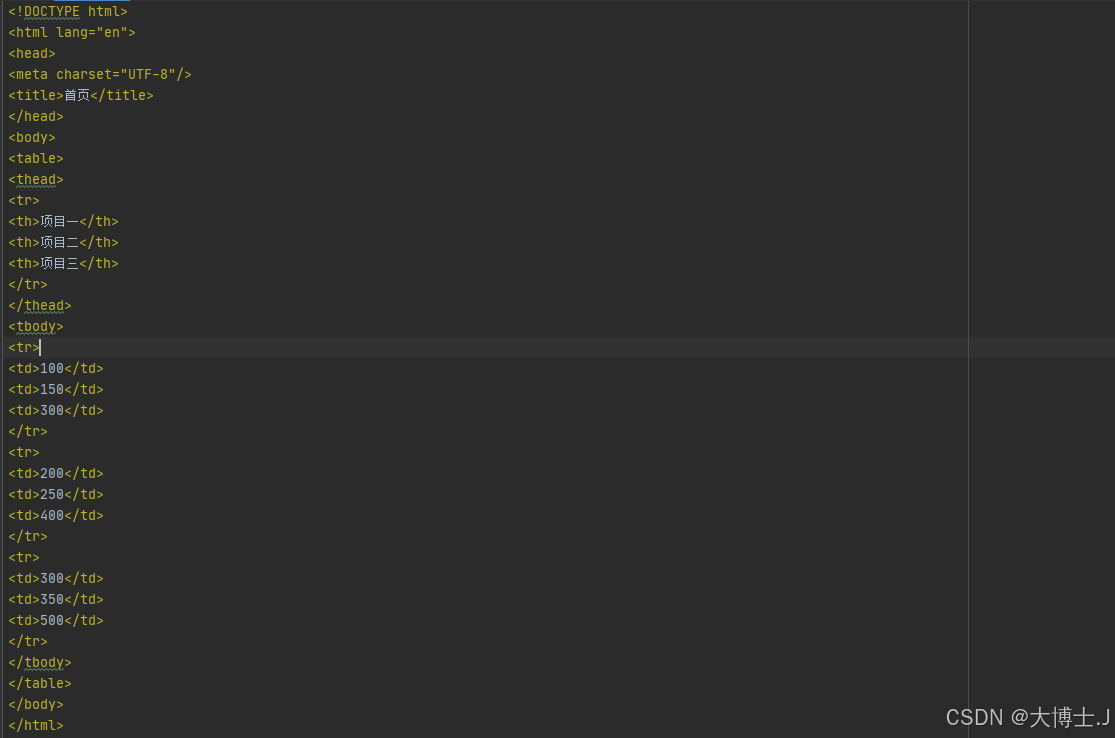
我们将编写一个Python脚本来解析这个HTML文件,提取标题和表格中的数据。
步骤1:导入必要的库
首先,我们需要导入requests和lxml.etree模块:
import requests
from lxml import etree
步骤2:定义解析函数
接下来,我们定义一个函数jiexi_html(),用于解析HTML文件并提取所需的数据:
def jiexi_html():
file_path = 'html' # 假设这是本地HTML文件的路径
tree = etree.parse(file_path)
# 提取<title>标签的内容
title = tree.xpath('//title/text()')
print(f"页面标题: {title[0]}")
# 提取表格标题(<th>标签的内容)
table_title = tree.xpath('//thead/tr/th/text()')
print("表格标题:", table_title)
# 提取表格数据(<td>标签的内容)
table_tr = tree.xpath('//tbody/tr')
tr_td_text = []
# 遍历每一行<tr>元素
for tr in table_tr:
# 获取该行中的所有<td>元素的文本内容
tr_td = tr.xpath('./td/text()')
dist = {"name": tr_td[0], "age": tr_td[1], "city": tr_td[2]}
tr_td_text.append(dist)
print("表格数据:", tr_td_text)
步骤3:调用解析函数
最后,我们在主程序中调用jiexi_html()函数:
if __name__ == "__main__":
jiexi_html()
完整的代码如下:
import requests
from lxml import etree
# 解析HTML测试
def jiexi_html():
file_path = 'html' # 假设这是本地HTML文件的路径
tree = etree.parse(file_path)
# 提取<title>标签的内容
title = tree.xpath('//title/text()')
print(f"页面标题: {title[0]}")
# 提取表格标题(<th>标签的内容)
table_title = tree.xpath('//thead/tr/th/text()')
print("表格标题:", table_title)
# 提取表格数据(<td>标签的内容)
table_tr = tree.xpath('//tbody/tr')
tr_td_text = []
# 遍历每一行<tr>元素
for tr in table_tr:
# 获取该行中的所有<td>元素的文本内容
tr_td = tr.xpath('./td/text()')
dist = {"name": tr_td[0], "age": tr_td[1], "city": tr_td[2]}
tr_td_text.append(dist)
print("表格数据:", tr_td_text)
if __name__ == "__main__":
jiexi_html()
运行上述代码后,你将看到如下输出:
页面标题: 测试页面
表格标题: ['姓名', '年龄', '城市']
表格数据: [{'name': '张三', 'age': '25', 'city': '北京'}, {'name': '李四', 'age': '30', 'city': '上海'}, {'name': '王五', 'age': '22', 'city': '广州'}]
自动化获取并解析网页
除了解析本地HTML文件外,我们还可以使用requests库自动获取网页内容并进行解析。以下是修改后的示例,展示了如何从网络上获取HTML内容并解析它:
修改后的解析函数
def jiexi_html_from_web(url):
# 发送HTTP请求获取网页内容
response = requests.get(url)
if response.status_code != 200:
print(f"请求失败,状态码: {response.status_code}")
return
# 解析网页内容
tree = etree.HTML(response.content)
# 提取<title>标签的内容
title = tree.xpath('//title/text()')
print(f"页面标题: {title[0]}")
# 提取表格标题(<th>标签的内容)
table_title = tree.xpath('//thead/tr/th/text()')
print("表格标题:", table_title)
# 提取表格数据(<td>标签的内容)
table_tr = tree.xpath('//tbody/tr')
tr_td_text = []
# 遍历每一行<tr>元素
for tr in table_tr:
# 获取该行中的所有<td>元素的文本内容
tr_td = tr.xpath('./td/text()')
dist = {"name": tr_td[0], "age": tr_td[1], "city": tr_td[2]}
tr_td_text.append(dist)
print("表格数据:", tr_td_text)
调用解析函数
假设我们要解析的网页URL为http://example.com/test.html,可以在主程序中调用jiexi_html_from_web()函数:
if __name__ == "__main__":
url = "http://example.com/test.html"
jiexi_html_from_web(url)
结语
通过这篇博客,我们学习了如何使用requests和lxml库解析HTML文件并提取所需的数据。这些工具为我们提供了强大的功能,使我们能够轻松地从网页中提取信息并进行进一步的处理或分析。
希望这篇博客能够帮助你更好地理解和应用这些技术。你可以根据自己的需求扩展和完善这些示例,比如处理更复杂的HTML结构,或者结合其他库(如pandas)进行数据分析。欢迎分享你的成果和心得!
注意:请确保遵循所有相关的法律和规定,在实际生产环境中谨慎使用此类工具。如果你有任何问题或建议,欢迎在评论区留言交流!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









