







单台redis的缺点:
单台redis可能出现宕机现象
单台redis的内存受限
redis分片:
优点:
可以实现动态扩容 ;
如果单台redis出现问题则数据影响较小--其他redis中数据不丢失
缺点:
如果一台redis宕机则其他redis节点不能使用
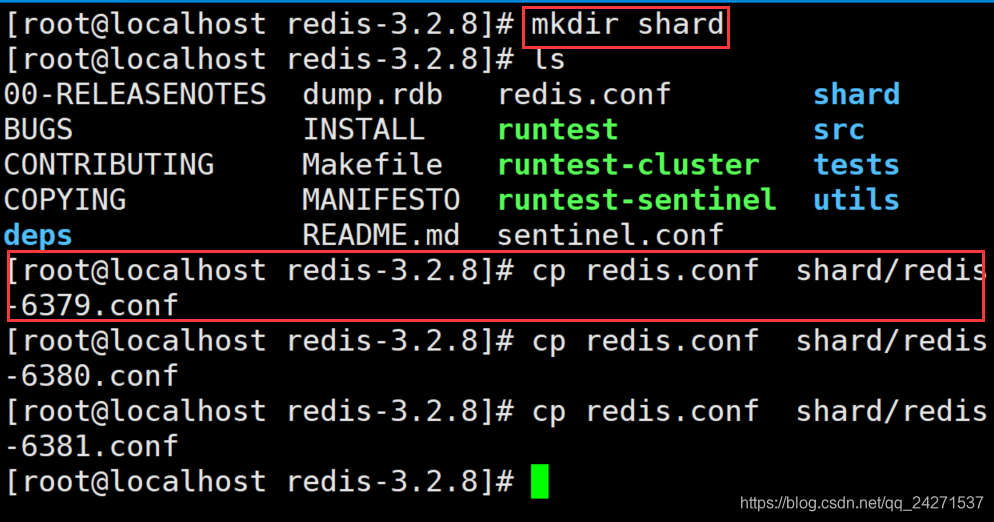
分片的搭建:
1、将原有redis关闭
redis-cli -p 6379 shutdown
2、复制多个redis配置文件
说明:在redis根目录下创建 shard文件夹
将redis.conf文件复制到shard文件夹下
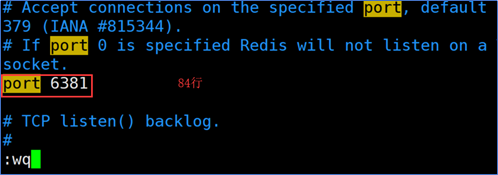
3、修改redis端口
分别修改6380-6381的端口号
4、启动多台redis

程序中分片的使用:
哈希一致性算法:
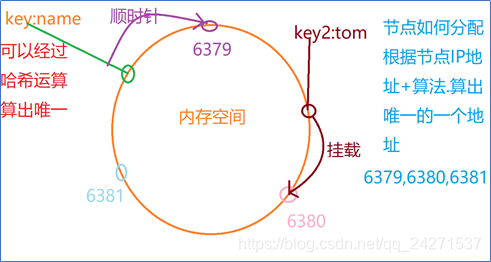
redis采用哈希一致性算法
特点:
1、分散性
为什么数据会落入不同的节点??
哈希一直算法中会根据key值算出唯一的一个物理地址,将数据保存在该地址中.
将redis的节点信息根据IP+算法算出唯一的一个物理地址.
Key值以顺时针方向寻找最近的redis节点进行挂载.
当获取数据时.首先根据key值计算出属于哪台redis节点,之后从该节点中get(key).
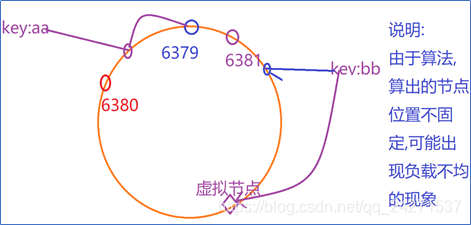
2、均衡性
当根据哈希运算的结果出现负载不均的现象时,会为当前负载较少的节点创建虚拟节点.作用是为了分担数据的压力.保证节点所管理的信息数量尽可能维持在1/N的水平.
3、单调性
单调性可以实现动态的数据扩容/动态数据挂载---redis节点增加或减少时
当redis中的节点出现宕机时,那么该节点中的数据全部从内存清空--重新挂载,那么剩余的节点会动态的进行哈希运算,剩余节点中的key值动态的实现数据挂载.
4、负载
spring整合分片:
spring/Redis_applicationContext-shard.xml
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:mvc="http://www.springframework.org/schema/mvc" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/mvc http://www.springframework.org/schema/mvc/spring-mvc-4.0.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd"> <!--每次都创建jedis对象性能较低 创建jedis连接池 --> <bean id="poolConfig" class="redis.clients.jedis.JedisPoolConfig"> <!--定义连接总数 --> <property name="maxTotal" value="${redis.maxTotal}"/> <!--定义最大闲置资源 --> <property name="maxIdle" value="${redis.maxIdle}"/> <!--定义是否自动连接 --> <property name="testOnBorrow" value="${redis.testOnBorrow}"/> </bean> <!--定义6379主机 public JedisShardInfo(String host, int port) --> <bean id="jedisShard1" class="redis.clients.jedis.JedisShardInfo"> <constructor-arg index="0" value="${redis.host1}" type="java.lang.String"/> <constructor-arg index="1" value="${redis.port1}" type="int"/> </bean> <!--定义6380主机 --> <bean id="jedisShard2" class="redis.clients.jedis.JedisShardInfo"> <constructor-arg index="0" value="${redis.host2}" type="java.lang.String"/> <constructor-arg index="1" value="${redis.port2}" type="int"/> </bean> <!--定义6381主机 --> <bean id="jedisShard3" class="redis.clients.jedis.JedisShardInfo"> <constructor-arg index="0" value="${redis.host3}" type="java.lang.String"/> <constructor-arg index="1" value="${redis.port3}" type="int"/> </bean> <!--定义分片连接池 final GenericObjectPoolConfig poolConfig, List<JedisShardInfo> shards--> <bean id="shardedJedisPool" class="redis.clients.jedis.ShardedJedisPool"> <constructor-arg index="0" ref="poolConfig"/> <constructor-arg index="1"> <list> <ref bean="jedisShard1"/> <ref bean="jedisShard2"/> <ref bean="jedisShard3"/> </list> </constructor-arg> </bean> </beans>
property/redis.properties
#最小空闲数 redis.minIdle=100 #最大空闲数 redis.maxIdle=300 #最大连接数 redis.maxTotal=1000 #客户端超时时间单位是毫秒 redis.timeout=5000 #最大建立连接等待时间 redis.maxWait=1000 #是否在从池中取出连接前进行检验,如果检验失败,则从池中去除连接并尝试取出另一个 redis.testOnBorrow=true redis.host1=192.168.126.151 redis.port1=6379 redis.host2=192.168.126.151 redis.port2=6380 redis.host3=192.168.126.151 redis.port3=6381
工具类
//实现分片的redis操作 @Autowired private ShardedJedisPool shardedJedisPool; public void set(String key,String value){ ShardedJedis jedis = shardedJedisPool.getResource(); jedis.set(key, value); shardedJedisPool.returnResource(jedis); } public String get(String key){ ShardedJedis jedis = shardedJedisPool.getResource(); String json = jedis.get(key); shardedJedisPool.returnResource(jedis); System.out.println("分片的操作完成!!!!"); return json; }

















 4271
4271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









