









 本文介绍Scrapy爬虫框架的基本概念、工作流程及安装方法。Scrapy是一款用于高效抓取网站数据并提取结构化数据的应用框架,通过异步网络处理提升爬取速度。文章涵盖依赖库安装、项目与爬虫创建、基本命令使用等内容。
本文介绍Scrapy爬虫框架的基本概念、工作流程及安装方法。Scrapy是一款用于高效抓取网站数据并提取结构化数据的应用框架,通过异步网络处理提升爬取速度。文章涵盖依赖库安装、项目与爬虫创建、基本命令使用等内容。
1.什么是scrapy
scrapy是一个为了爬取网站数据,提起结构性数据而编写的应用框架,我们只需要实现少量的代码,就能够快速的抓取数据。使用了异步网络框架,可以加快速度。
2.scrapy的工作流程
2.1之前的流程
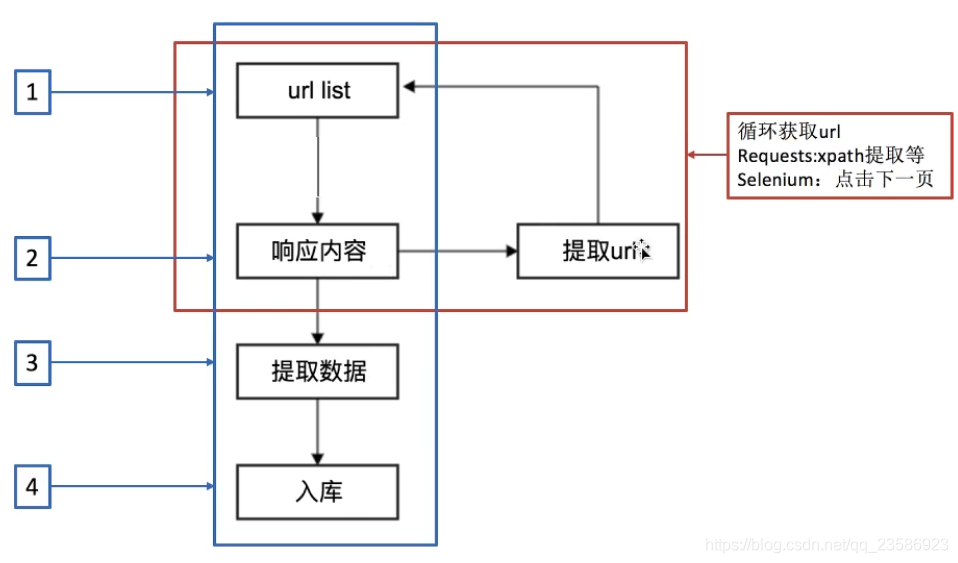
2.2另一种形式爬虫流程
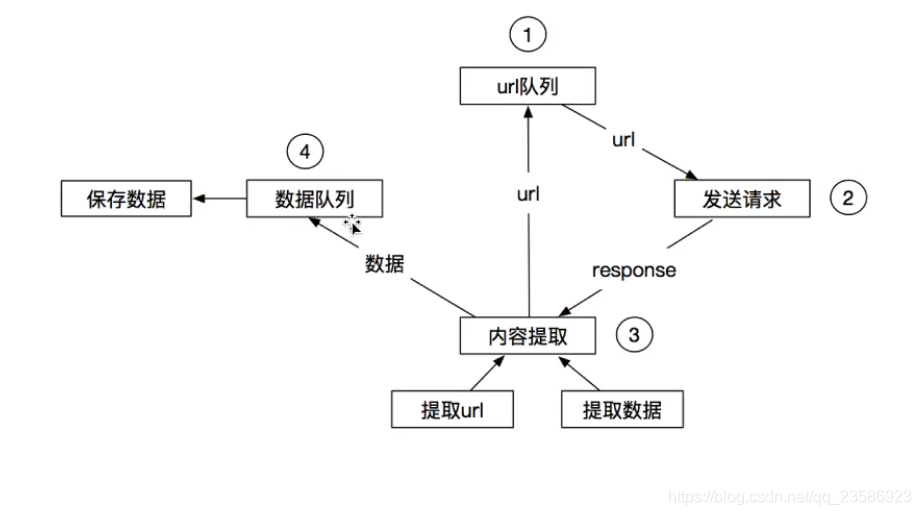
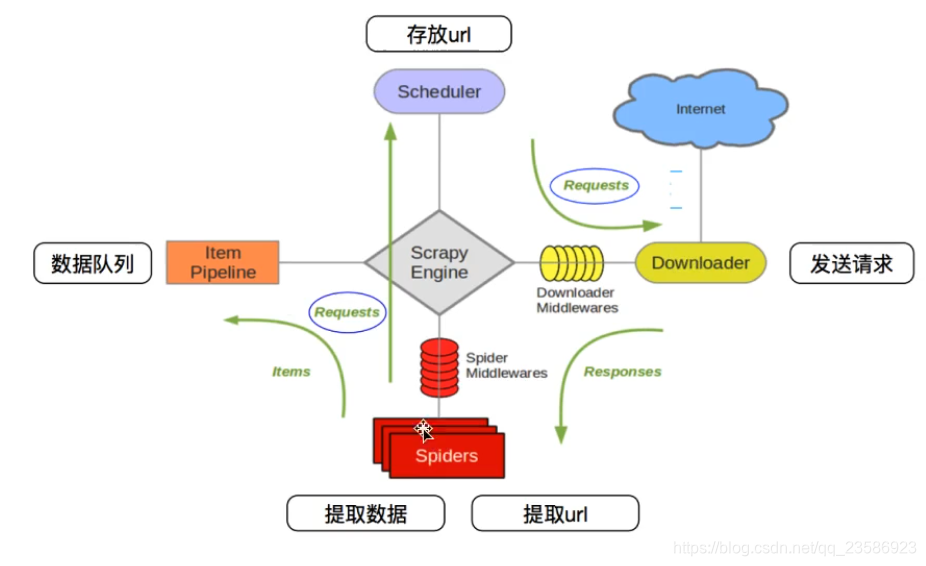
3.安装scrapy
3.1首先安装的是4个依赖库
lxml
pyOpenSSL
Twisted
PyWin32
3.2 执行安装screpy
pip3 install Scrapy4 .简单实用Scrapy
创建项目:scrapy startproject xxx
进入项目:cd xxx #进入某个文件夹下
创建爬虫:scrapy genspider xxx(爬虫名) xxx.com (爬取域)
生成文件:scrapy crawl xxx -o xxx.json (生成某种类型的文件)
运行爬虫:scrapy crawl XXX
列出所有爬虫:scrapy list
获得配置信息:scrapy settings [options]


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









