






 本文介绍了如何使用Canal监控MySQL数据库的binlog并借助Kafka进行实时推送。首先,你需要在MySQL服务器上开启binlog并创建Canal用户。接着,下载并安装Canal,配置相关参数,如设置serverMode为kafka,指定Kafka服务器地址等。完成配置后启动Canal,最后启动Kafka消费者以接收数据库变更消息。
本文介绍了如何使用Canal监控MySQL数据库的binlog并借助Kafka进行实时推送。首先,你需要在MySQL服务器上开启binlog并创建Canal用户。接着,下载并安装Canal,配置相关参数,如设置serverMode为kafka,指定Kafka服务器地址等。完成配置后启动Canal,最后启动Kafka消费者以接收数据库变更消息。
参考资料:
参考文章 https://gper.club/articles/7e7e7f7ff3g59gc6g6d
https://gper.club/articles/7e7e7f7ff3g59gc6g6d
canal官网 https://github.com/alibaba/canal
环境准备:
- 要有本服务器可访问的MySQL服务,远程的请检查是否已经开启了MySQL远程访问,如果没有,参考
- 因为本文是canal结合Kafka,监控MySQL的binlog,并进行数据库变化的推送,所以必须有可使用的Kafka
- 没有Kafka的参考:Kafka单节点(推荐),或者Kafka集群
- 还需要Java8,及以上的JDK环境
canal安装及配置:
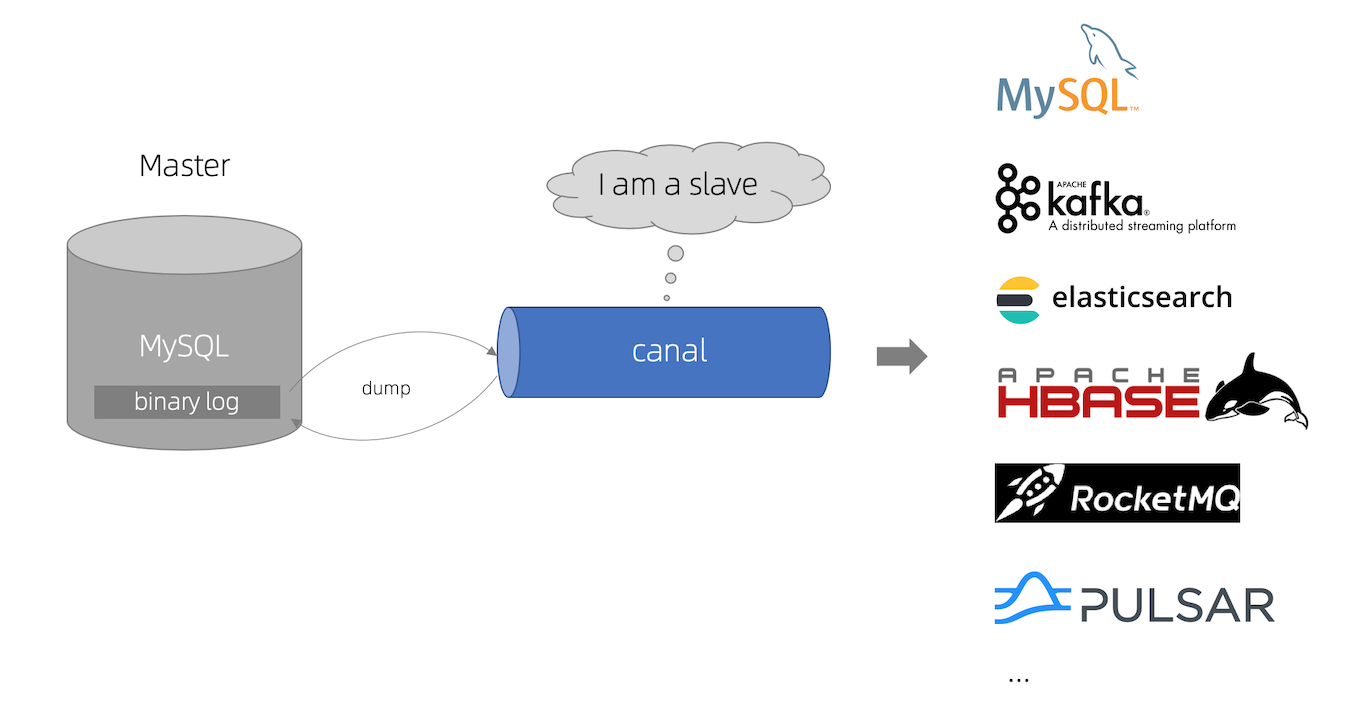
在基础环境部署好后,就开始安装canal
1. 在目标数据库上创建用户和数据库
- 首先需要在数据库上开启binlog,且binlog-format必须是ROW
- 找到MySQL的配置文件,默认路径是:/etc/my.cnf
vim /etc/my.cnf
- 在配置文件中添加下面语句
log-bin=/usr/local/mysql/data/mysql-bin
binlog-format=ROW
server_id=1
- 然后进入到MySQL,mysql -u root -p,输入密码登录
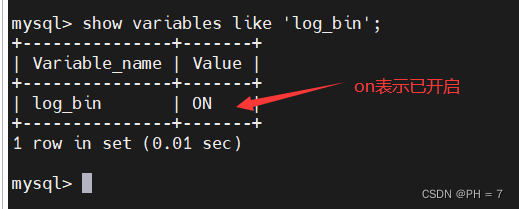
- 查看是否开启binlog
show variables like 'log_bin';
- 然后启动或重启MySQL服务 ()
# 启动MySQL
sudo service mysqld start
# 重启MySQL
sudo service mysqld restart
# 查看MySQL状态
sudo service mysqld status
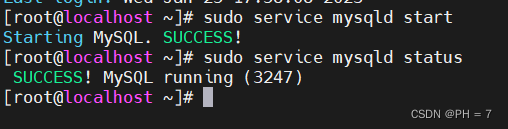
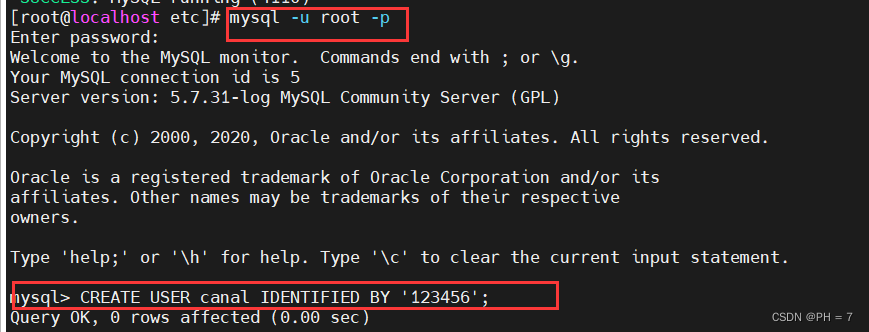
- 然后再进入到数据库中,mysql -u root -p ,创建用户和数据库
# 创建canal专用的用户,用于访问master获取binlog
CREATE USER canal IDENTIFIED BY '123456';
- 给canal用户分配查询和复制的权限
先检查权限是否开启
# 查看已创建的数据库
show databases;
# 选择MySQL数据库use mysql
# 查看root用户是否开启
select user,host,grant_priv from user;
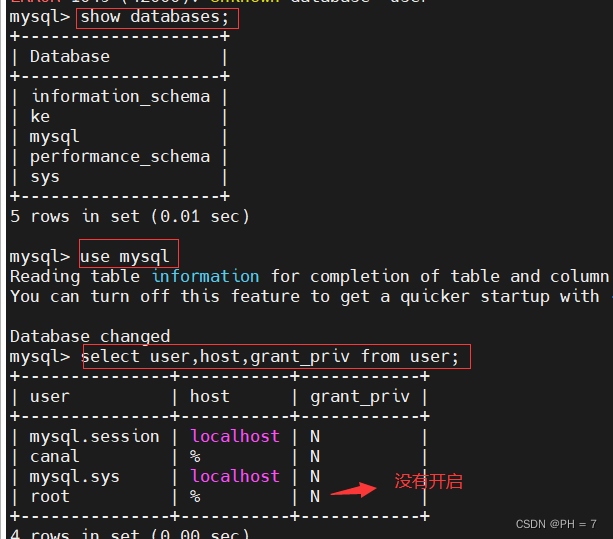
如果root显示是N,则需要开启
UPDATE user set Grant_priv='Y' where user='root' and `Host`='%';
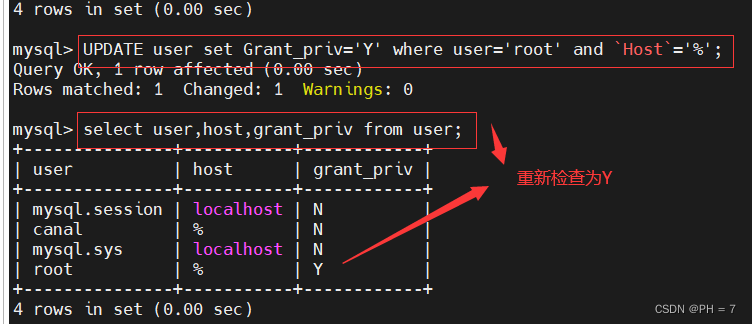
刷新权限
flush privileges;

给canal用户分配查询和复制的权限
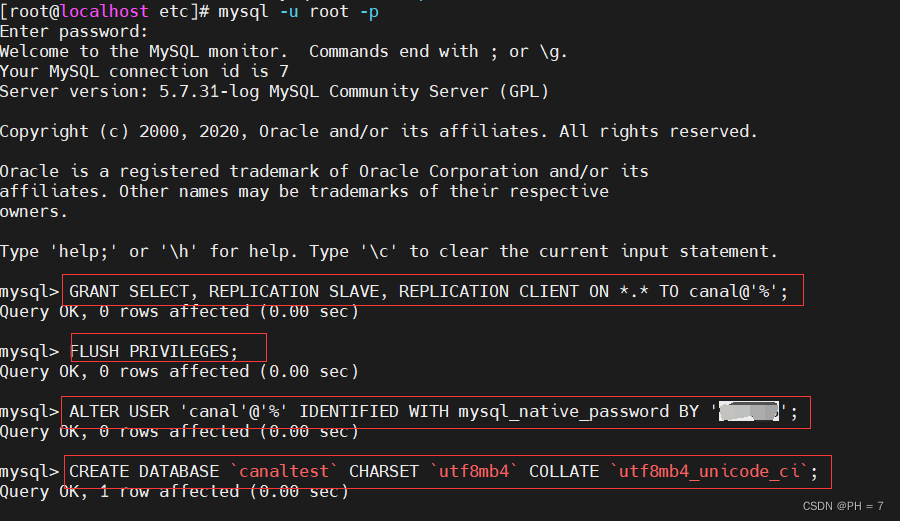
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO canal@'%';

- 刷新权限
FLUSH PRIVILEGES;
- 配置密码
ALTER USER 'canal'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
- 创建测试数据库
CREATE DATABASE `canaltest` CHARSET `utf8mb4` COLLATE `utf8mb4_unicode_ci`;
CTRL+Z进行退出
2. 下载安装canal
- 以安装目录:/usr/local/soft/canal为例
用目前稳定版本1.1.4
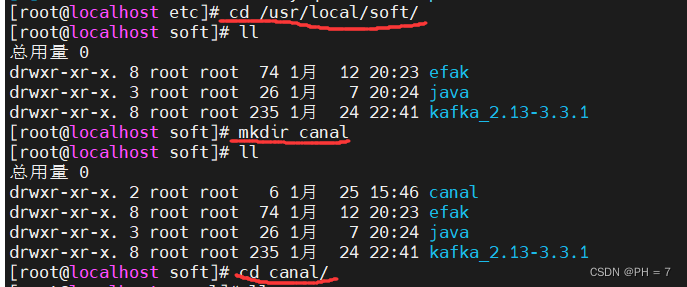
cd /usr/local/soft/
mkdir canal
cd canal
- 然后在canal目录中下载canal的安装包,有两种方式
(1). 本地下载好后再上传到服务器中的 /usr/local/soft/canal 目录(特别推荐)
访问网址
https://github.com/alibaba/canal/releases/download/canal-1.1.4/canal.deployer-1.1.4.tar.gz
将下载好的tar包上传至创建的目录 /usr/local/soft/canal
(2). 执行以下命令进行下载(不推荐,经常下载失败)
wget https://github.com/alibaba/canal/releases/download/canal-1.1.4/canal.deployer-1.1.4.tar.gz
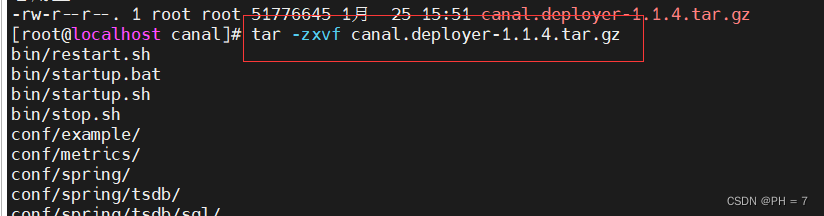
- 下载好后,进行解压
tar -zxvf canal.deployer-1.1.4.tar.gz
- 配置相应的配置项
在canal目录下,执行
vim conf/canal.properties
添加如下配置
canal.serverMode=kafka
canal.mq.servers = 192.168.44.160:9092

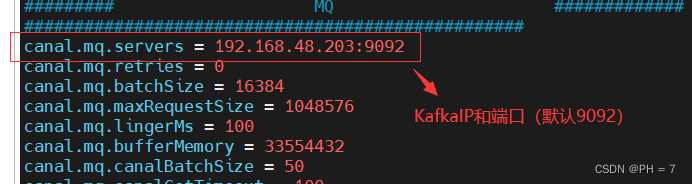
保存退出
在canal目录下执行
vim /usr/local/soft/canal/conf/example/instance.properties
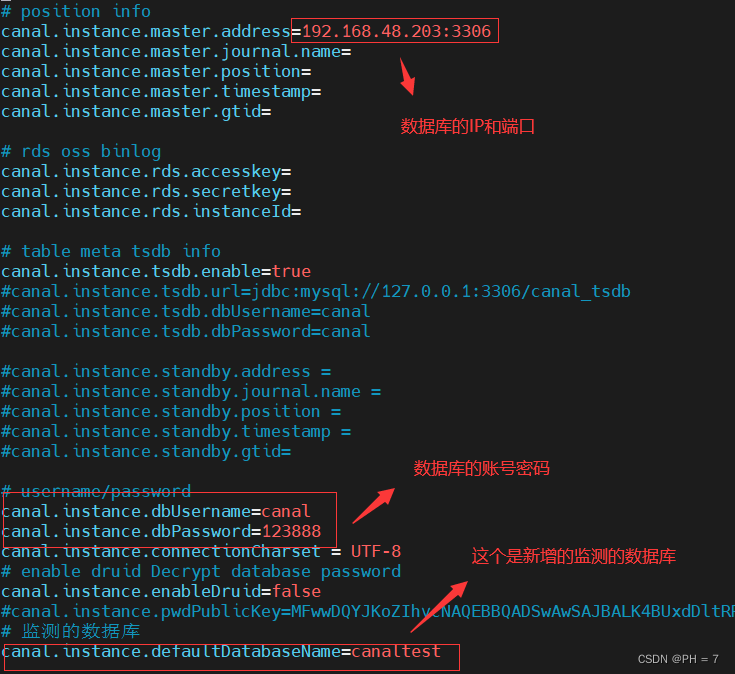
修改或添加如下配置
canal.instance.master.address=192.168.44.121:3306
canal.instance.dbUsername=canal
canal.instance.dbPassword=123456
# 新增
canal.instance.defaultDatabaseName=canaltest
# 这个topic会自动创建
canal.mq.topic=canal-topic

- 启动Kafka,如果不会参考
- 进入到bin目录,启动canal
cd bin
sh startup.sh
# 查看实例日志
tail -100f /usr/local/soft/canal/logs/canal/canal.log

3. 启动Kafka消费者,消费我们配置好的 canal-topic
在Kafka服务器上的安装目录下的bin目录,执行以下语句,消费canal-topic

4.在canaltest数据库随便建一张表,做增删改的操作,Kafka的canal-topic消费者就能接收到数据变化的消息
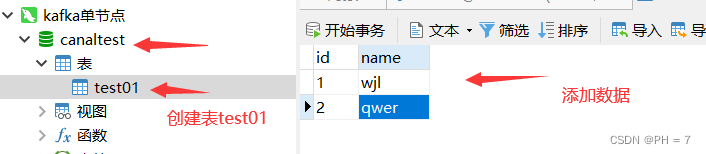

- 我们可以利用这个技术,进行数据库的动态监测


















 382
382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











