







网络的属性和随机图模型
网络的关键属性
这里的属性主要是针对无向图而言
(1)度数分布 Degree Distribution P ( k ) P(k) P(k)
一个随机选择的节点的度数为
k
k
k的概率,称之为度数分布。
P
(
k
)
=
N
k
N
P(k) =\frac{N_k} { N}
P(k)=NNk
其中
N
k
N_k
Nk = 度数为
k
k
k的节点数量。
- 归一化直方图

对于有向图而言,度数分布将分为入度分布(in-)和出度分布(out-degree distribution)
(1)路径长度 Path length h h h
路径Path
每个节点都与下一个节点相连的节点序列。
A path is a sequence of nodes in which each
node is linked to the next one.
P
n
=
i
0
,
i
1
,
i
2
,
i
3
,
.
.
.
,
i
n
P_n = {i_0,i_1,i_2,i_3,...,i_n}
Pn=i0,i1,i2,i3,...,in
P
n
=
(
i
0
,
i
1
)
,
(
i
1
,
i
2
)
,
(
i
2
,
i
3
)
,
.
.
.
,
(
i
n
−
1
,
i
n
)
P_n = {(i_0,i_1),(i_1,i_2),(i_2,i_3),...,(i_{n-1},i_n)}
Pn=(i0,i1),(i1,i2),(i2,i3),...,(in−1,in)
一个路径可以与自己相交,也可以多次穿过相同的边。

(2)距离 Distance(shortest path,geodesic)
两点之间的距离是指两点之间最短路径所经过的边的数量。如果两点是非连通的,通常定义其距离为无穷大(或零)。

对于有向图而言,路径需要根据路径的方向。结果导致两点之间距离是不对称。

直径
是图中任意两点的距离的最大值。直径不能很好的反映图的性质,人们跟倾向于使用平均路径长度
平均路径长度 Average path length
应用于连通图或者一个强连通有向图。
h
‾
=
1
2
E
m
a
x
∑
i
,
j
≠
i
h
i
j
\overline{h} = \frac{1}{2E_{max}}\sum_{i,j\ne i} h_{ij}
h=2Emax1i,j=i∑hij
其中
h
i
j
h_{ij}
hij是节点
i
i
i到
j
j
j之间的距离,
E
m
a
x
E_{max}
Emax 是边的最大数量(所有成对节点)=
n
(
n
−
1
)
/
2
n(n-1)/2
n(n−1)/2。
- 通常情况下只计算连通的成对节点,这样就可以忽略“无限长”的路径。
- 这个也可以用于测量一张图的(强)连通组件。
(3)聚类系数 Clustering Coefficient C C C
描述
i
i
i的邻居如何连接其他节点。
C
i
=
2
e
i
k
i
(
k
i
−
1
)
C_i = \frac{2e_i}{k_i(k_i-1)}
Ci=ki(ki−1)2ei
其中
k
i
k_i
ki为节点
i
i
i的度,
e
i
e_i
ei是节点
i
i
i的邻居之间的边的数量(如下图中中间的图,
e
i
e_i
ei=3,这个3是来自外围一圈的3条边),%k_i(k_i-1)%是
k
i
k_i
ki邻居的最大边数。

需要注意的是,
C
i
∈
[
0
,
1
]
C_i \in [0,1]
Ci∈[0,1]。
聚类系数在度数为0或1的节点上没有定义。
平均聚类系数 Average Clutering Coefficient
C
=
1
N
∑
i
N
C
i
C = \frac{1}{N}\sum^N_iC_i
C=N1i∑NCi

(4)连通性 Connectivity
连通性用最大连通组件(largest connected component)的大小来描述。即两个顶点能够通过路径连通的最大集合。
寻找连通组件的方法
- 从随机节点开始,执行广度优先搜索(BFS)。
- 标记BFS访问过的节点。
- 如果所有节点都被访问了,那么这个网络是连通图。
- 否则寻找没有访问过的节点,重新执行广度优先搜索。

现实网络的属性
- MSN Messenger



度分布

在这个直方图中,分布表现不明显,所以转换为log-log度数分布

聚类

C k = 1 N k ∑ i : k i = k C i C_k = \frac{1}{N_k}\sum_{i:k_i=k}C_i Ck=Nk1∑i:ki=kCi ,average of C i C_i Ci of nodes i i i of degree k k k。
连通组件

直径

- MSN的关键参数总结

PPI 网络对比
protein & protein interaction network

Erdos-Renyi随机图模型 (Random Graph Model)
两个变体(variants)
- G n p G_np Gnp :在有 n n n个节点的无向图,每个节点对 ( u , e ) (u,e) (u,e)是否有边的概率是 p p p。
-
G
n
m
G_nm
Gnm:在有
n
n
n个节点的无向图中,有
m
m
m条边,边是从候选集中随机挑选的。
需要注意的是, n n n和 p p p并不能判定唯一的图。(图是一个随机的过程的结果)。在相同的 n n n和 p p p下可以实现不同的图。

度数分布
P
(
k
)
=
(
n
−
1
k
)
p
k
(
1
−
p
)
n
−
1
−
k
P(k) = \bigl( \begin{matrix}n-1 \\ k\end{matrix}\bigl) p^k(1-p)^{n-1-k}
P(k)=(n−1k)pk(1−p)n−1−k
其中,
P
(
k
)
P(k)
P(k)表示具有
k
k
k度的节点的概率。这里的
k
k
k的取值是从
[
0
,
n
−
1
]
[0,n−1]
[0,n−1]。
直观的理解是,一个节点
a
a
a的度为
k
k
k可能性是在剩下的
n
−
1
n-1
n−1个节点中选取
k
k
k个节点与节点
a
a
a相连接的,对应
(
n
−
1
k
)
p
k
\bigl( \begin{matrix}n-1 \\ k\end{matrix}\bigl) p^k
(n−1k)pk,另外的节点都是与节点
a
a
a不连接的,对应
(
1
−
p
)
n
−
1
−
k
(1-p)^{n-1-k}
(1−p)n−1−k。

这是典型的二项式分布,所以根据二项分布的期望和方差公式可以得出,
k
k
k的期望:
k
‾
=
p
(
n
−
1
)
\overline k = p(n-1)
k=p(n−1)
k
k
k的方差:
σ
2
=
p
(
1
−
p
)
(
n
−
1
)
\sigma^2 = p(1-p)(n-1)
σ2=p(1−p)(n−1)
值得注意的是,通过将
σ
\sigma
σ和
k
‾
\overline k
k进行比值得到
σ
k
‾
=
[
1
−
p
p
1
n
−
1
]
2
≈
1
(
n
−
1
)
1
/
2
\frac {\sigma}{\overline k} = \left[ \frac{1-p}{p}\frac{1}{n-1}\right]^2 \approx \frac{1}{(n-1)^{1/2}}
kσ=[p1−pn−11]2≈(n−1)1/21
我们可以直观地看到,当
n
n
n不断扩大的时候
σ
k
‾
\frac {\sigma}{\overline k}
kσ会变得越来越小,这是对应的P(k)-k的分布图会越来越集中,说明越来越多节点的度都接近
k
‾
\overline k
k。
聚类系数
G
n
p
G_{np}
Gnp下的聚类系数
聚集系数的计算公式是:
C
i
=
2
e
i
k
i
(
k
i
−
1
)
C_i =\frac{ 2e_i}{k_i(k_i-1)}
Ci=ki(ki−1)2ei
在第一课中已经提到过,
e
i
e_i
ei是邻居之间边的数量。更具随机图
G
n
p
G_{np}
Gnp的定义,我们可以得出
e
i
e_i
ei的期望
E
[
e
i
]
=
p
k
i
(
k
i
−
1
)
2
E[e_i] = p\frac{k_i(k_i-1)}{2}
E[ei]=p2ki(ki−1)
其中
k
i
(
k
i
)
−
1
2
\frac{k_i(k_i)-1}{2}
2ki(ki)−1是邻居之间所可能有的所有边,
p
p
p为边连接的概率。
将
E
[
e
i
]
E[e_i]
E[ei]带入计算后可以得到期望的聚类系数为:
E
[
C
i
]
=
p
⋅
k
i
(
k
i
−
1
)
k
i
(
k
i
−
1
)
=
p
=
k
‾
n
−
1
≈
k
‾
n
E[C_i] = \frac {p \cdot k_i(k_i-1)}{k_i(k_i-1)} = p = \frac{\overline k}{n-1} \approx \frac{\overline k}{n}
E[Ci]=ki(ki−1)p⋅ki(ki−1)=p=n−1k≈nk
我们得到,如果
k
‾
\overline k
k固定的话,随着
n
n
n的增长,聚合系数就越来越小。
路径长度
计算路径长度需要引入一个扩展系数 α \alpha α,其定义为对于 G ( V , E ) G(V,E) G(V,E),如果 ∀ S ⊆ V : S 的 离 去 边 的 数 量 ≥ α ⋅ m i n ( ∣ S ∣ , ∣ V \ S ∣ ) \forall S \subseteq V : S的离去边的数量 \geq \alpha \cdot min(|S|,|V\backslash S |) ∀S⊆V:S的离去边的数量≥α⋅min(∣S∣,∣V\S∣)。等同于 α = m i n S ⊆ V = S 的 离 去 边 的 数 量 m i n ( ∣ S ∣ , ∣ V \ S ∣ ) \alpha =\underset{S \subseteq V }{min} = \frac { S的离去边的数量}{min(|S|,|V\backslash S |)} α=S⊆Vmin=min(∣S∣,∣V\S∣)S的离去边的数量
对于一个带有 n n n个节点的图,在带有扩展系数 α \alpha α的情况下,网络的路径长度为 O ( ( l o g n ) / α ) O((log n)/ \alpha) O((logn)/α)。(这里是直接给出的,至于怎么计算,一头雾水)。
对于随机网络 G n p G_{np} Gnp,路径长度的期望就是 O ( l o g ( n ) / l o g ( n p ) ) O(log(n)/ log(np)) O(log(n)/log(np))。
对于固定的
k
‾
=
n
p
\overline k = np
k=np,分母变成了常数,就变成了
O
(
l
o
g
(
n
)
)
O(log(n ))
O(log(n))级别。模拟实验的结果如下,也证明了这个结论。

图连通性
由于随机图的连通性是概率的函数,所以图连通性会随概率
p
p
p的变化而改变。

可以看出,
p
p
p从0开始,是一个完全隔离的图,直到等于1,变成一个完全图。中间在平均度为1之后,开始出现超大连通元件。模拟仿真的结果也支持了这个规律。

G
n
p
随
机
网
络
与
M
S
N
网
络
对
比
G_{np}随机网络与MSN网络对比
Gnp随机网络与MSN网络对比
可以清晰的看到,现实的社交网络并不符合随机网络模型。
虽然随机网络的平均路径是比较短的,但聚合系数非常的低,这是由于随机网络假定的是大家都随机的和世界上其他人交朋友。但真实的网络具有“本地”结构:1.三角组合(朋友的朋友也是我的朋友)2.有高聚合系数但直径很小。
研究意义
- 其他网络的参考
- 帮助我们计算的量与真实数据对比。
- 帮助我们理解一个特性性质对一些随机过程结果有什么程度的影响
小世界模型 (The Small-World Model)
根据上文分析,我们可以知道,显示的社交网络是一个具有—高聚合系数、低平均路径长度特点的网络。那么我们能否通过一个模型来产生这样的图——高聚合系数、低平均路径长度(或者就是低图直径)。
高聚合系数图和低直径图
在介绍生成方法之前,需要介绍两种图:高聚合系数图和低直径图。在高聚合系数图(下图左)中,每个节点都于左右第二个节点相连来产生本地结构,得到了高聚合系数,但图的半径也很大;在低直径图(下图右)中,每个节点都随机与其他两个节点相连接来产生随机网络,得到了低直径,但聚合系数也很高。

在这里,聚合系数可以反映“本地性”;随机性来允许产生捷径链接(shortcuts)。
生成方法
小世界模型的生成分为两个步骤
- 构建一个低维常规格架(lattice)
这个格架是一个高聚合系数的格架,在这里的例子是用一个环来作为格架(上图左)。 - 重连:引入随机性(捷径)
添加或删去边来构造捷径来来连接lattice中远端的部分。每条边都有可能性 p p p将重点移到一个任一点。
这两个过程可以理解为随机选中一个点,如下图中的蓝点,然后选择它的其中一条边从连接临近节点变为连接其他任意一点。经过几次后就可以得到下图。
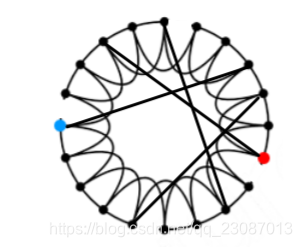
重连步骤的分析
需要注意的是,重连这个过程不是每条边都需要进行的。随着每条边重连的可能性不断提高(可以形象的理解为重连的次数增加),高内聚大直径图就会先变成高内聚小直径图,接着就会变成低内聚小直径图,整个变化过程入下图所示。
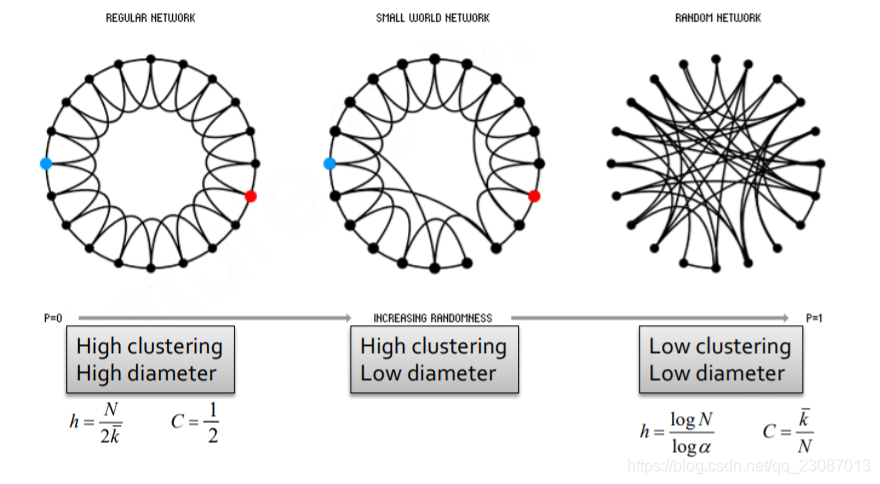
对重连可能性
p
p
p的变化进行实验,可以得到下图,左侧纵坐标为聚合系数,右侧纵坐标为平均路径长度。
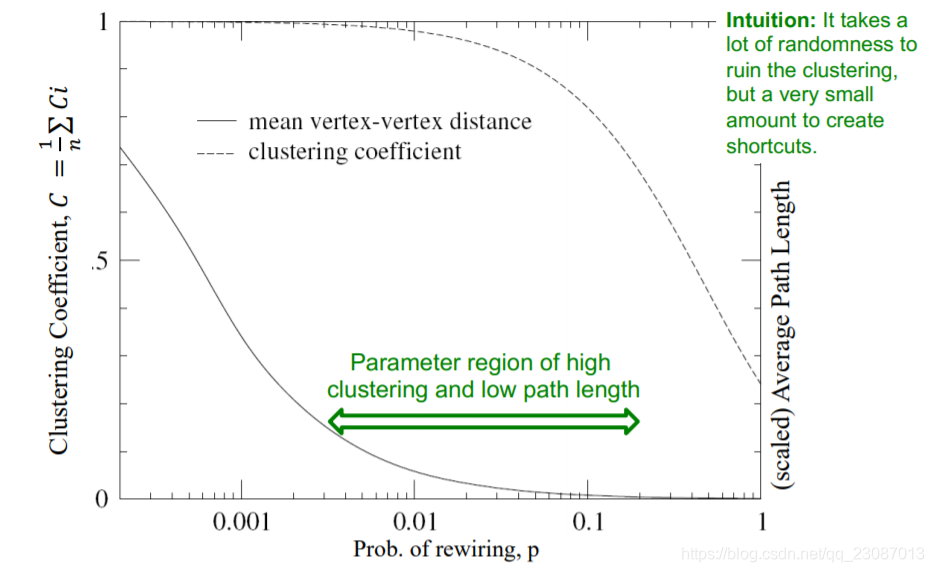
可以看到,随着
p
p
p的增大,图的聚合系数和平均路径长度都在发生变化,在一定的区间内,可以看看到一个高聚合大直径图变成了低聚合大直径图。
小世界模型分析
- 这个模型为我们洞悉了聚合与小世界之间的相互影响。
- 提取了许多真实网络的结构。
- 解释真实网络中出现高内聚的情况。
- 仍没有正确匹配到度分布。
小世界模型很好地模拟了现实中地一些网络,特别是社交网络。在重连步骤分析中,我们可以的得知了社交网络具有本地性的原因:一些随机的非熟人的社交关系带来了很短的路径长度。
Kroneck Graph Model
Kronck graph model主要解决的是生成大型的现实图的问题。
解决这个问题的关键思想是自我复制。模仿重复或者社增长。可以在下图中形象地得知这个过程。
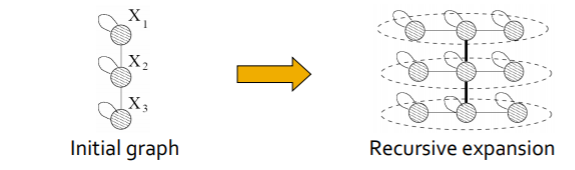
Kronecker算法则是利用了自我复制以及Kronecker乘法,可以高效地复构建出大型的网络。自我复制的过程可以简单的描述为下图的过程。另外,利用分布式的方法就可以创建超级大图。。过程如下图所。
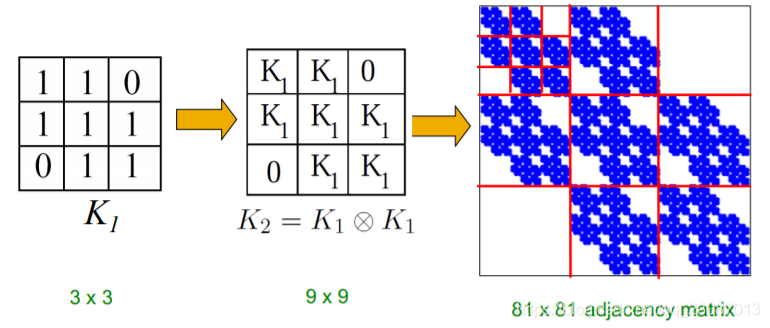
生成方式
Kronecker模型的生成方式是基于Kronecker乘法实现的。
kroneck乘法的具体形式可以由下图所示
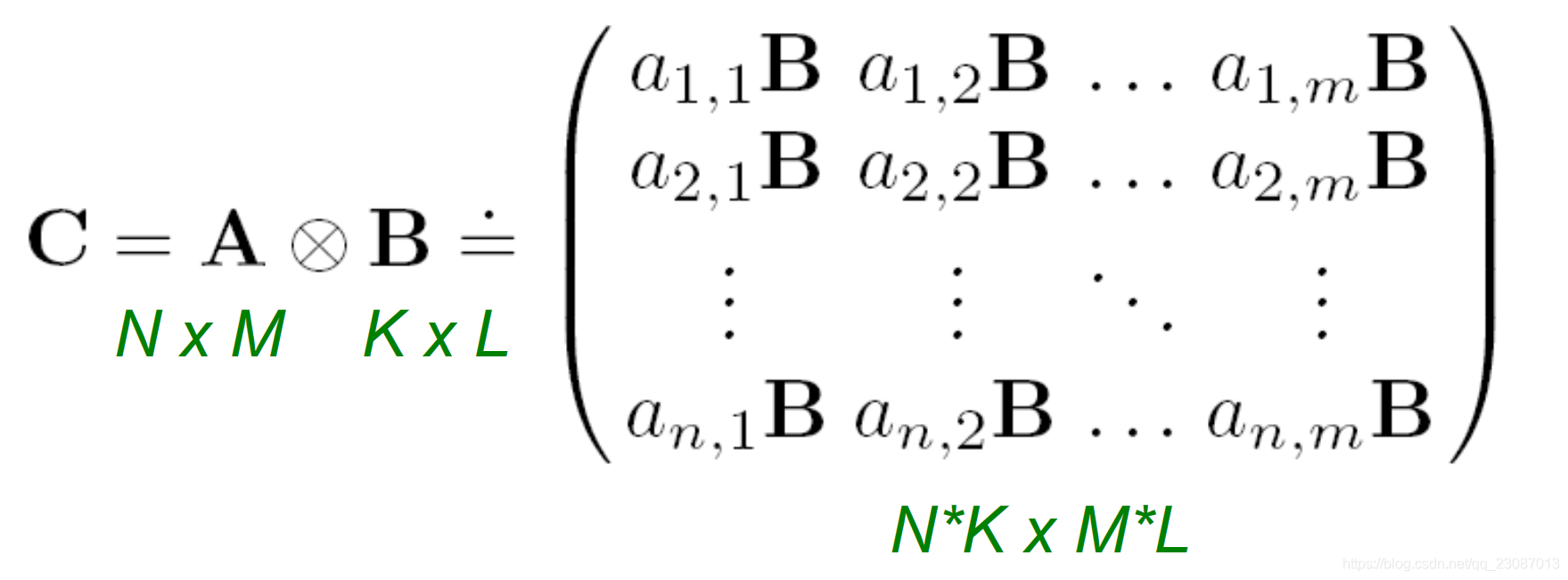
在这里
A
A
A和
B
B
B可以是两个大小不相同的矩阵。这个乘法可以看作
A
A
A中的每一项与
B
B
B相乘。
Kronecker图是通过在初始矩阵K上迭代Kronecker积的增长图序列(growing sequence of graphs)而得到的。

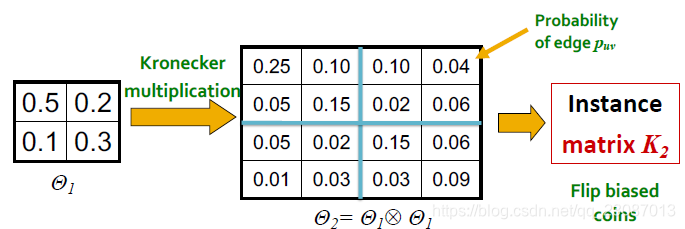
对初始图进行重复Kronecker乘法构造图只会受初始图的影响,是确定的,很难映射到现实网络。针对这一情况,需要对网络引入一些随机性。增加随机性的方法非常简单,只需要引入一个概率图。
- 创建一个 N 1 × N 1 N_1\times N_1 N1×N1的可能性矩阵 Θ 1 \Theta_1 Θ1。
- 使用 k k k次Kronecker乘法,生成矩阵 Θ k \Theta_k Θk。
- 对于 Θ k \Theta_k Θk中的每一项 p u v p_{uv} puv代表一条边 ( u , v ) (u,v) (u,v)生成的概率。
- 按照概率
p
u
v
p_{uv}
puv生成世界的邻接矩阵,生成最终的大图。
这个方法很优雅,但是当产生图很大的时候, 生成图所需要的运行时和内存都会变得非常大。
解决这个问题的方法是Drop边。具体的方法如下图

这个方法个人还不是很理解是如何进行drop的,我的理解是在生成的过程中,先估计需要生成的边,在进行乘法生成概率矩阵,然后生成后插入生成图中。这个过程减少了生成边的次数,对于低概率的就在生成就被drop掉了,不知道这个理解正不正确。
按照这个生成算法产生的图,经过比较仔细的调参,可以很好的和真实网络的特征相匹配。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









