




 本文介绍了如何使用Python进行文件名批量重命名、添加序号、根据Excel清单进行操作,以及不同编码间的转换,提升文件管理效率。
本文介绍了如何使用Python进行文件名批量重命名、添加序号、根据Excel清单进行操作,以及不同编码间的转换,提升文件管理效率。
一、准备工作
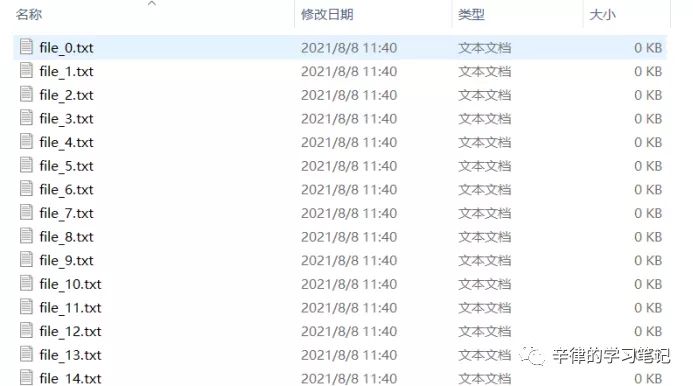
为了用于实验,我们使用代码生成 200 个 txt 文件,代码如下。
for i in range(0, 200):
file_name = f'file_{i}.txt'
f = open(f'./file/{file_name}', mode='w')
f.close()运行结果:
二、制作 excel 的文件清单
1、思路
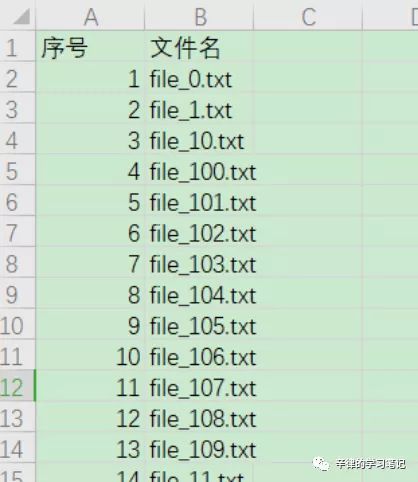
获取文件名,并将序号和文件名写入 excel。
2、openpyxl 安装
本文使用 openpyxl 库进行 excel 操作,使用 pip 进行安装。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple openpyxl3、代码
from openpyxl import load_workbook
import os
# 获取file路径所有txt文件
def find_txt(path):
filenames = []
filename_listdir = os.listdir(path)
for filename in filename_listdir:
if filename.find('txt') != -1:
filenames.append(filename)
return filenames
# 生成文件清单
def add_data(excel_path, filenames):
# 判断excel文件是否存在
if os.path.exists(excel_path) is False:
print(excel_path + ' 文件不存在,请重试')
exit()
excel_file = load_workbook(excel_path) # 打开excel文件
excel_sheet = excel_file['Sheet1'] # 选择Sheet1
# 增加表头
excel_sheet.cell(row=1, column=1, value='序号') # 序号
excel_sheet.cell(row=1, column=2, value='文件名') # 文件名
# 添加文件名
count = 1
for i in filenames[0:]:
count = count + 1
excel_sheet.cell(row=count, column=1, value=count - 1) # 序号
excel_sheet.cell(row=count, column=2, value=i) # 文件名
excel_file.save(excel_path)
# 文件所在文件夹
file_path = './file'
# 【文件清单.xlsx】路径
excel_path = os.getcwd() + '/file/文件清单.xlsx'
filenames = find_txt(file_path)
print(filenames)
add_data(excel_path, filenames)
print('Success!')运行结果:
三、文件的批量重命名
1、文件名批量增加序号
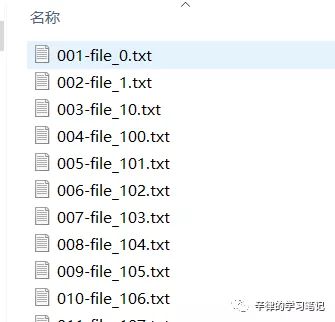
在文件整理统计时,经常要给文件名添加序号,在上面保存文件清单的过程,我们可以看到脚本的默认排序保存是按首位数字排序,在此我们可以通过补零来保证按数字大小排序。
1)重命名函数:
os.rename(name, new_name)
2)代码
import os
path = os.getcwd() + '\\file'
filenames = os.listdir(path)
a = 1
for filename in filenames:
if filename.find('txt') != -1:
old_dir = f'{path}\\{filename}'
if a < 10:
new_dir = f'{path}\\00{a}-{filename}'
elif a < 100:
new_dir = f'{path}\\0{a}-{filename}'
else:
new_dir = f'{path}\\{a}-{filename}'
os.rename(old_dir, new_dir)
a = a + 13)运行结果
2、文件名批量重命名成指定文件名
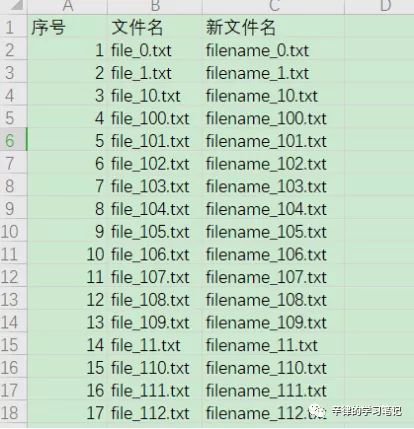
我们在制作文件清单后,可以使用excel进行便捷的文件名统一调整(如去空格,增加头尾字段等)。我们可以在excel中制作好修改后的文件名后,再批量将文件名重命名。
1)实验目标
如图:我们尝试将文件名改成新文件名(使用 excel 的将 file 替换成filename )。
2)代码
from openpyxl import load_workbook
import os
# 获取file路径文件名
def find_txt(path):
filenames = []
filename_listdir = os.listdir(path)
for filename in filename_listdir:
if filename.find('txt') != -1:
filenames.append(filename)
return filenames
# 批量重命名
def change_file_name(file_path, excel_path, filenames):
data = load_workbook(excel_path)
sheet = data['Sheet1']
for i in range(1, sheet.max_row + 1)[1:]:
for filename in filenames:
if filename == sheet.cell(i, 2).value:
old_dir = os.path.join(file_path, filename)
new_dir = os.path.join(file_path, sheet.cell(i, 3).value)
os.rename(old_dir, new_dir)
else:
pass
# 文件所在文件夹
file_path = './file'
# 【文件清单.xlsx】路径
excel_path = os.getcwd() + '/file/文件清单.xlsx'
filenames = find_txt(file_path)
print(filenames)
change_file_name(file_path, excel_path, filenames)
print('Success!')运行效果:
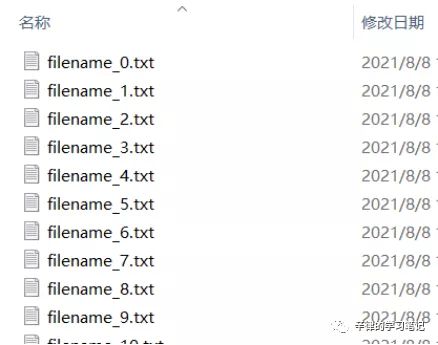
四、文件的批量删除
1、实验目标
我们在excel对文件名进行筛选后,将是否删除列为1的文件删除,保留为0的文件(如图)。
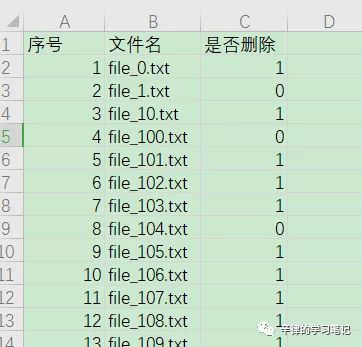
2、代码
from openpyxl import load_workbook
import os
# 获取file路径文件名
def find_txt(path):
filenames = []
filename_listdir = os.listdir(path)
for filename in filename_listdir:
if filename.find('txt') != -1:
filenames.append(filename)
return filenames
# 批量重命名
def change_file_name(file_path, excel_path, filenames):
data = load_workbook(excel_path)
sheet = data['Sheet1']
for i in range(1, sheet.max_row + 1)[1:]:
for filename in filenames:
if filename == sheet.cell(i, 2).value:
file_dir = os.path.join(file_path, filename)
delete_flag = sheet.cell(i, 3).value
if delete_flag:
os.remove(file_dir)
else:
pass
# 文件所在文件夹
file_path = './file'
# 【文件清单.xlsx】路径
excel_path = os.getcwd() + '/file/文件清单.xlsx'
filenames = find_txt(file_path)
print(filenames)
change_file_name(file_path, excel_path, filenames)
print('Success!')运行结果:标记文件已删除。

 https://zhuanlan.zhihu.com/p/441915312
https://zhuanlan.zhihu.com/p/441915312一、不同字符编码间的转换
windows 系统的默认编码是 GBK, 如果你把⼀段在 windows 系统上⽤ gbk 编码的字符发
送到 mac 电脑 上, mac 默认编码是 utf-8, 那这段⽂字是乱码显示的。 如何实现在 mac 上正常显示这段 gbk文本呢?
编码与解码
1.把任意编码转换成unicode的过程叫做解码
>>> s="卿云"
>>> s="卿云"#unicode格式
>>> s.encode("utf-8") #将其编码成utf-8
b'\xe5\x8d\xbf\xe4\xba\x91'
2.把unicode转换成的任意编码过程叫做编码
>>> s
'卿云'
>>> s.encode("utf-8").decode("utf-8")#把utf-8编码的字符在转化成unicode
'卿云'
3.
>>> s
'卿云'
>>> s.encode("utf-8") #将其编码成utf-8
b'\xe5\x8d\xbf\xe4\xba\x91
#会变成bytes字节格式,bytes字节类型是用16进制表示的,像\xe5这样两个16进制数是代表一个字节(因为一个16进制数占4位)
字节类型到底是什么
字节类型其实就是二进制数,只不过为了易于理解,常用16进制数表示。
# coding utf-8
import os
import chardet
# 获得所有java文件的路径,传入根目录路径
def find_all_file(path: str) -> str:
for root, dirs, files in os.walk(path):
for f in files:
if f.endswith('.java'):
fullname = os.path.join(root, f)
yield fullname
pass
pass
pass
# 判断是不是utf-8编码方式
def judge_coding(path: str) -> dict:
with open('utf.txt', 'rb') as f: # 删除就行
utf = chardet.detect(f.read()) # 同上
with open(path, 'rb') as f:
c = chardet.detect(f.read())
if c != utf: # 改为 c != 'utf-8'
return c
# 修改文件编码方式
def change_to_utf_file(path: str):
for i in find_all_file(path):
c = judge_coding(i)
if c:
change(i, c['encoding'])
print("{} 编码方式已从{}改为 utf-8".format(i, c['encoding']))
def change(path: str, coding: str):
with open(path, 'r', encoding=coding) as f:
text = f.read()
with open(path, 'w', encoding='utf-8') as f:
f.write(text)
# 查看所有文件编码方式
def check(path: str):
for i in find_all_file(path):
with open(i, 'rb') as f:
print(chardet.detect(f.read())['encoding'], ': ', i)
def main():
my_path = 'C:\\WorkSpace'
change_to_utf_file(my_path)
# check(my_path)
if __name__ == '__main__':
main()
import os
from chardet.universaldetector import UniversalDetector
def get_filelist(path):
"""
获取路径下所有csv文件的路径列表
"""
Filelist = []
for home, dirs, files in os.walk(path):
for filename in files:
if ".csv" in filename:
Filelist.append(os.path.join(home, filename))
return Filelist
def read_file(file):
"""
逐个读取文件的内容
"""
with open(file, 'rb') as f:
return f.read()
def get_encode_info(file):
"""
逐个读取文件的编码方式
"""
with open(file, 'rb') as f:
detector = UniversalDetector()
for line in f.readlines():
detector.feed(line)
if detector.done:
break
detector.close()
return detector.result['encoding']
def convert_encode2utf8(file, original_encode, des_encode):
"""
将文件的编码方式转换为utf-8,并写入原先的文件中。
"""
file_content = read_file(file)
file_decode = file_content.decode(original_encode, 'ignore')
file_encode = file_decode.encode(des_encode)
with open(file, 'wb') as f:
f.write(file_encode)
def read_and_convert(path):
"""
读取文件并转换
"""
Filelist = get_filelist(path=path)
fileNum= 0
for filename in Filelist:
try:
file_content = read_file(filename)
encode_info = get_encode_info(filename)
if encode_info != 'utf-8':
fileNum +=1
convert_encode2utf8(filename, encode_info, 'utf-8')
print('成功转换 %s 个文件 %s '%(fileNum,filename))
except BaseException:
print(filename,'存在问题,请检查!')
def recheck_again(path):
"""
再次判断文件是否为utf-8
"""
print('---------------------以下文件仍存在问题---------------------')
Filelist = get_filelist(path)
for filename in Filelist:
encode_info_ch = get_encode_info(filename)
if encode_info_ch != 'utf-8':
print(filename,'的编码方式是:',encode_info_ch)
print('--------------------------检查结束--------------------------')
if __name__ == "__main__":
"""
输入文件路径
"""
path = './'
read_and_convert(path)
recheck_again(path)
print('转换结束!')




















 171
171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











