






 本文介绍了一个关于Spark集群并发量的测试案例,通过不同程序设置来评估集群在同一时间内能运行的任务数量及其性能表现。
本文介绍了一个关于Spark集群并发量的测试案例,通过不同程序设置来评估集群在同一时间内能运行的任务数量及其性能表现。
https://blog.youkuaiyun.com/qq_43842093/article/details/131928114
一.安装docker
yum install docker
检查是否安装成功
docker --version
systemctl start docker二、安装Nginx
1、拉取nginx镜像文件
docker pull nginx
2、创建并运行nginx容器
docker run -d --name nginx -p 3344:80 nginx命令详解
| 参数 | 解释 |
|---|---|
| docker run | 启动一个镜像 |
| -d | 后台运行 |
| –name nginx | 表示为当前容器起一个别名 |
| -p 3344:80 | 表示将本机的3344端口映射到nginx镜像的80端口 |
查看正在运行的容器
docker ps

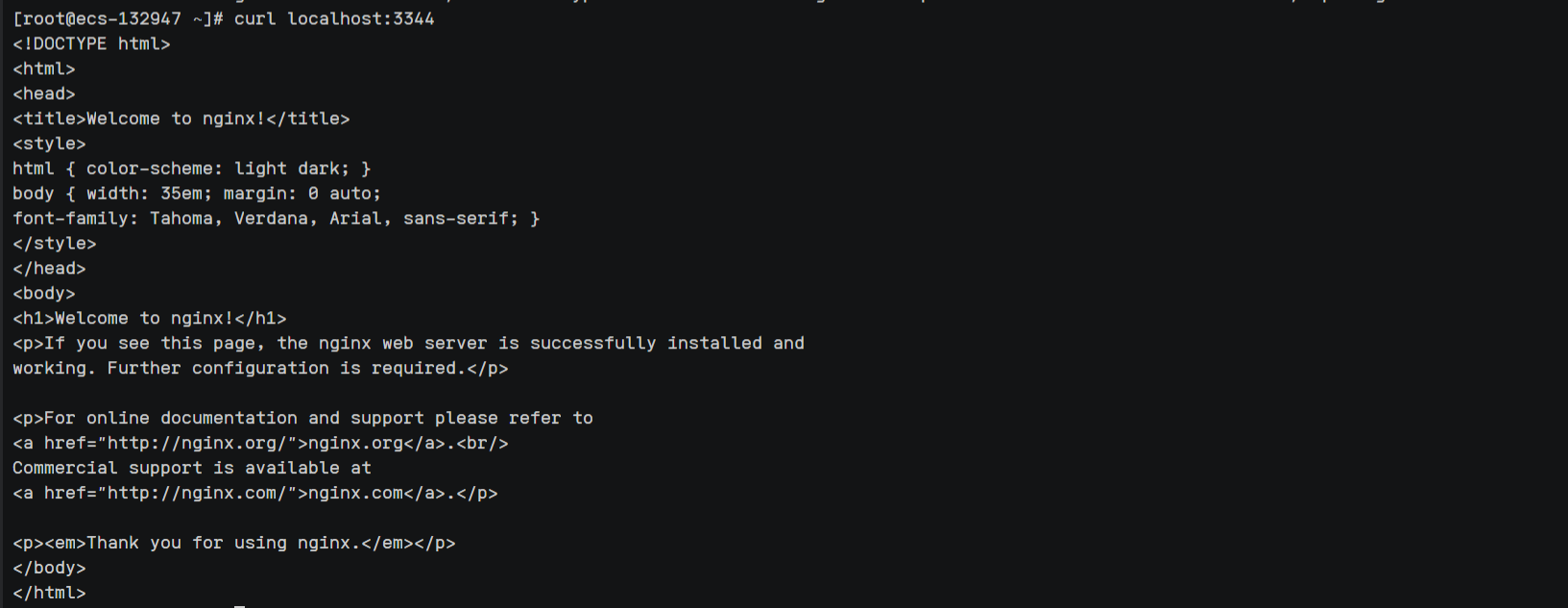
5、检查nginx是否部署成功
curl localhost:3344
6、创建挂载目录
mkdir -p /home/nginx/conf
mkdir -p /home/nginx/log
mkdir -p /home/nginx/html
7、将名为nginx容器中的相应文件copy到刚创建的管理目录中
# 将容器nginx.conf文件复制到宿主机
docker cp nginx:/etc/nginx/nginx.conf /home/nginx/conf/nginx.conf
# 将容器conf.d文件夹下内容复制到宿主机
docker cp nginx:/etc/nginx/conf.d /home/nginx/conf/conf.d
# 将容器中的html文件夹复制到宿主机
docker cp nginx:/usr/share/nginx/html /home/nginx/
# 将容器中的log文件夹复制到宿主机
docker cp nginx:/var/log/nginx /home/nginx/log
8、停止名为nginx的容器
docker stop nginx
9、删除名为nginx的容器
docker rm nginx
10、重启名为nginx容器并作目录挂载
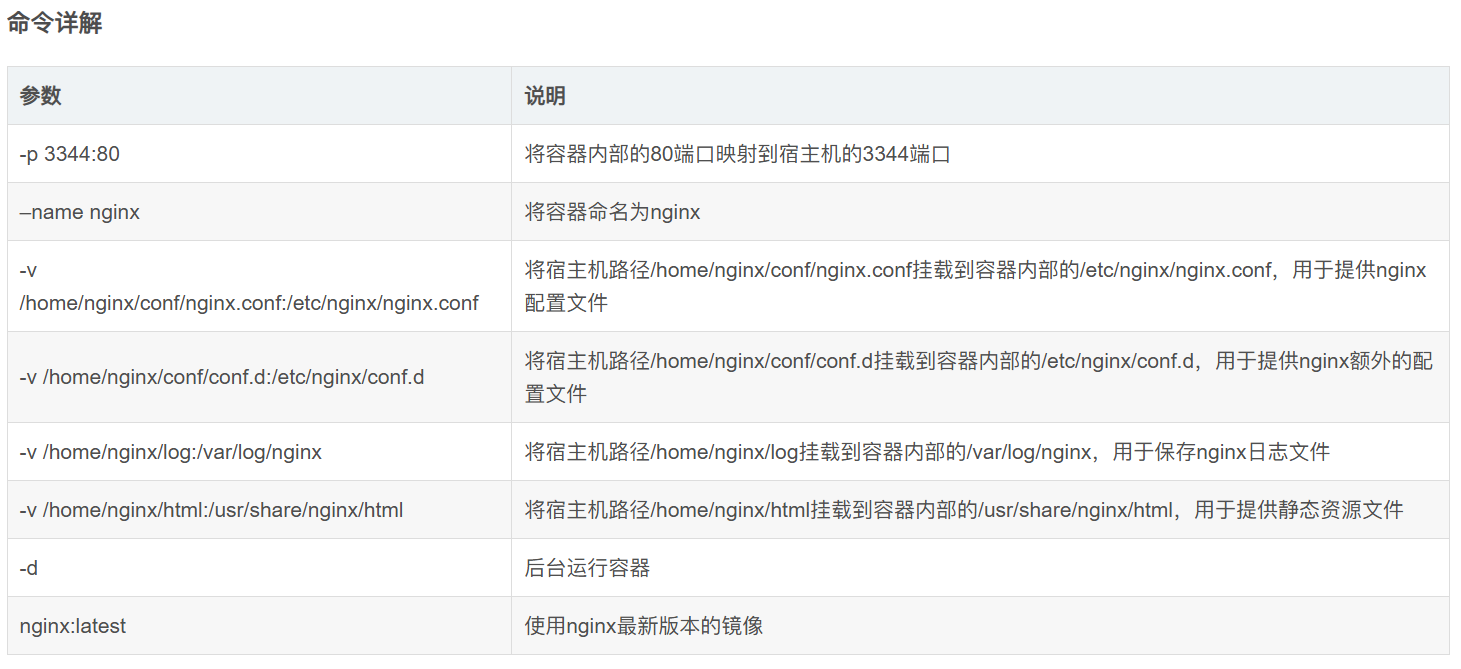
docker run -p 3344:80 --name nginx -v
/home/nginx/conf/nginx.conf:/etc/nginx/nginx.conf -v
/home/nginx/conf/conf.d:/etc/nginx/conf.d -v /home/nginx/log:/var/log/nginx -v
/home/nginx/html:/usr/share/nginx/html -d nginx:latest
11、检查容器运行正常
docker ps

12、检查是否部署成功
curl localhost:3344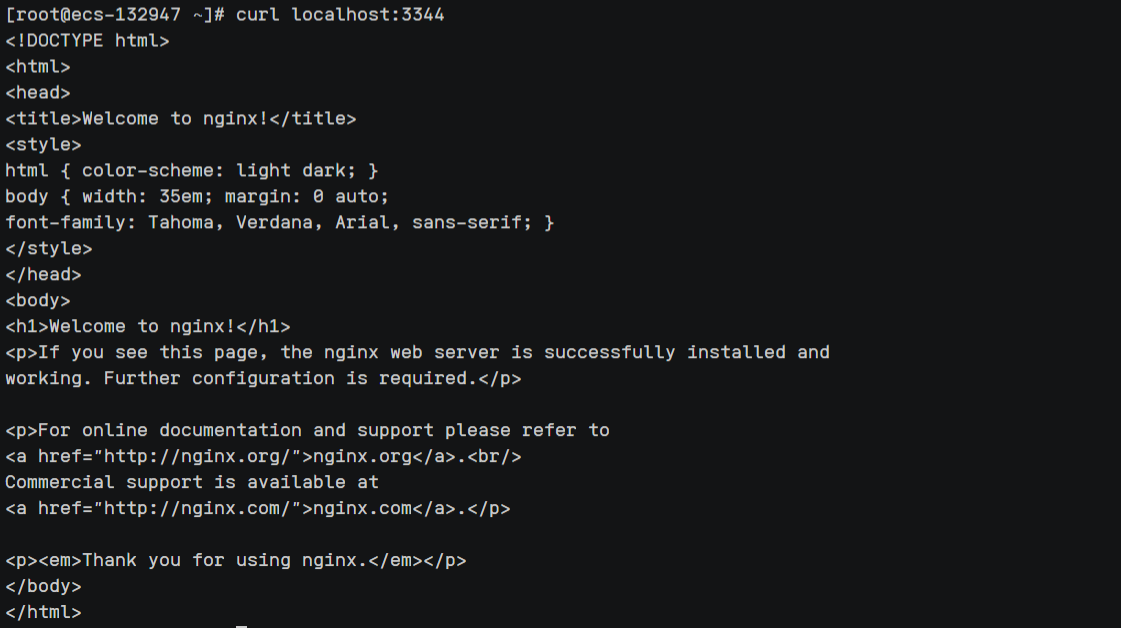
三、安装Mysql
1、下拉mysql镜像文件
docker pull mysql #默认最新版本
docker pull mysql:xxx #指定版本号2、启动mysql容器
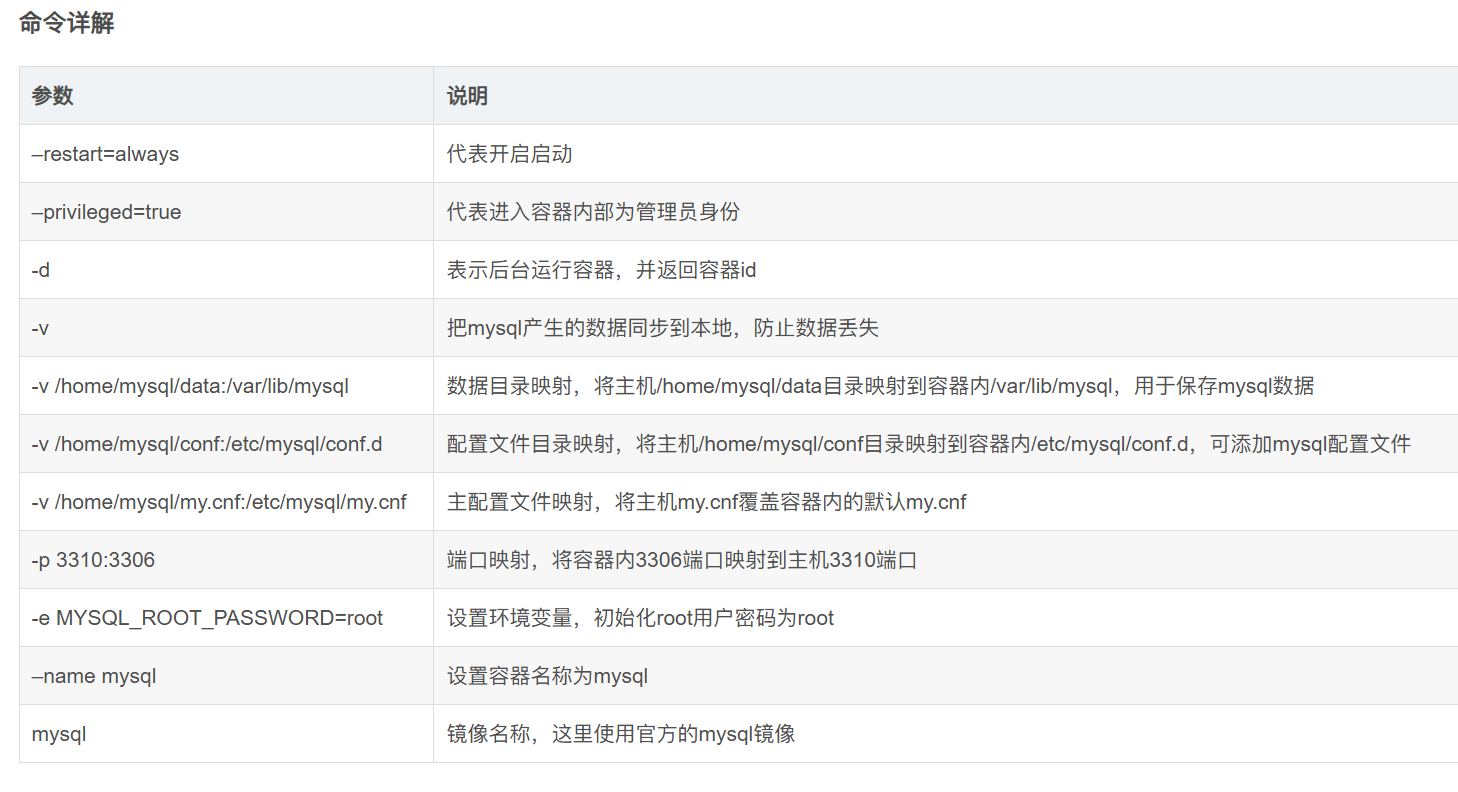
docker run --restart=always --privileged=true -d -v
/home/mysql/data:/var/lib/mysql -v /home/mysql/conf:/etc/mysql/conf.d -v
/home/mysql/my.cnf:/etc/mysql/my.cnf -p 3310:3306 --name mysql -e
MYSQL_ROOT_PASSWORD=root mysql
3、查看正在运行的容器
docker ps

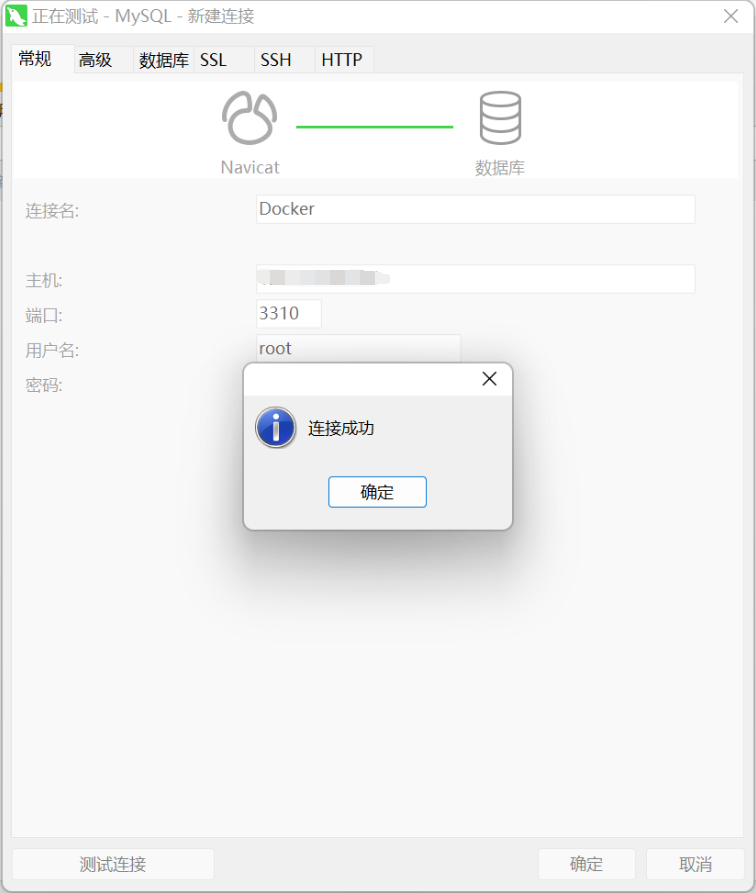
4、测试数据库连接
四、部署SpringBoot项目
1、整合后端成Jar包(mvn package)并编写Dockerfile文件(无后缀名)

2、Dockerfile内容详解
2、Dockerfile内容详解
FROM openjdk:8 #工程java版本
COPY *.jar /app.jar #将所有的jar包整合为app.jar
EXPOSE 9099 #暴露后端端口号
ENTRYPOINT ["java","-jar","app.jar"] #执行jar包
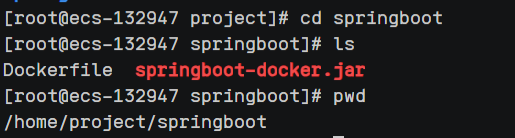
3、上传这两个文件到Linux服务器的同一个文件夹当中,务必放在一起!
4、构建镜像
docker build -t api . #点千万别漏了,这里取名镜像为api,可以随便取名!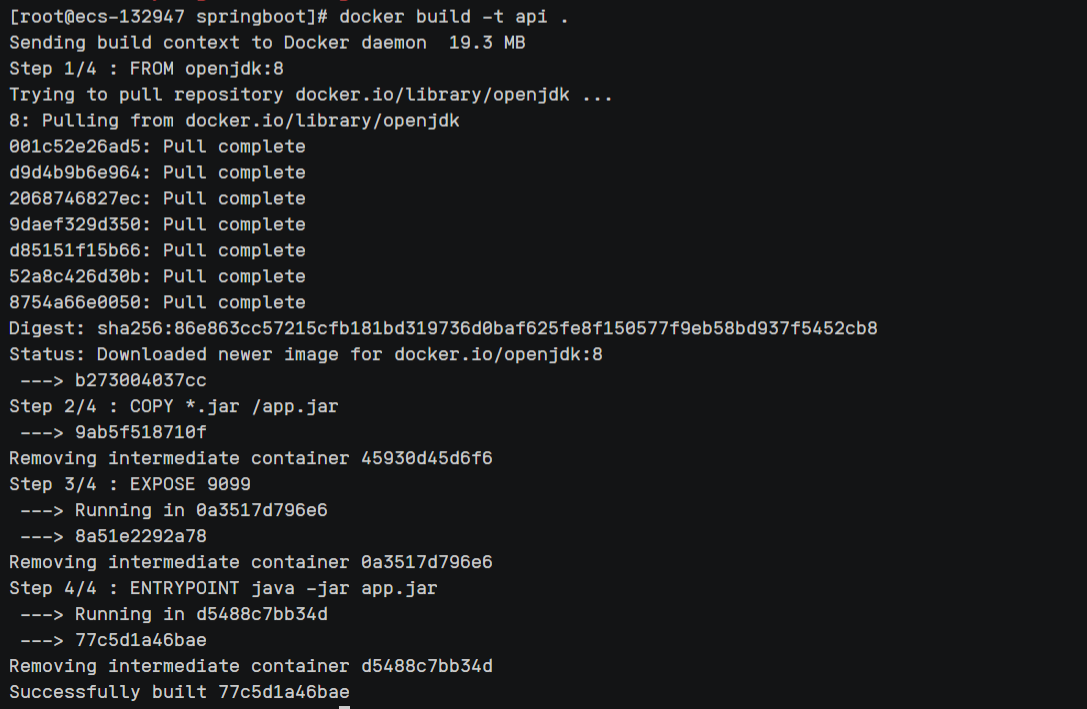
5、查看当前镜像
docker images

6、创建一个新的容器并运行
docker run -d -p 9090:9090 --name httapi api命令详解
| 参数 | 含义 |
|---|---|
| -p 9090:9090 | 将外部9090端口映射到容器内部的9090端口 |
| httapi | 自定义容器名字 |
| api | 镜像名字 |
7、查看正在运行的容器
docker ps
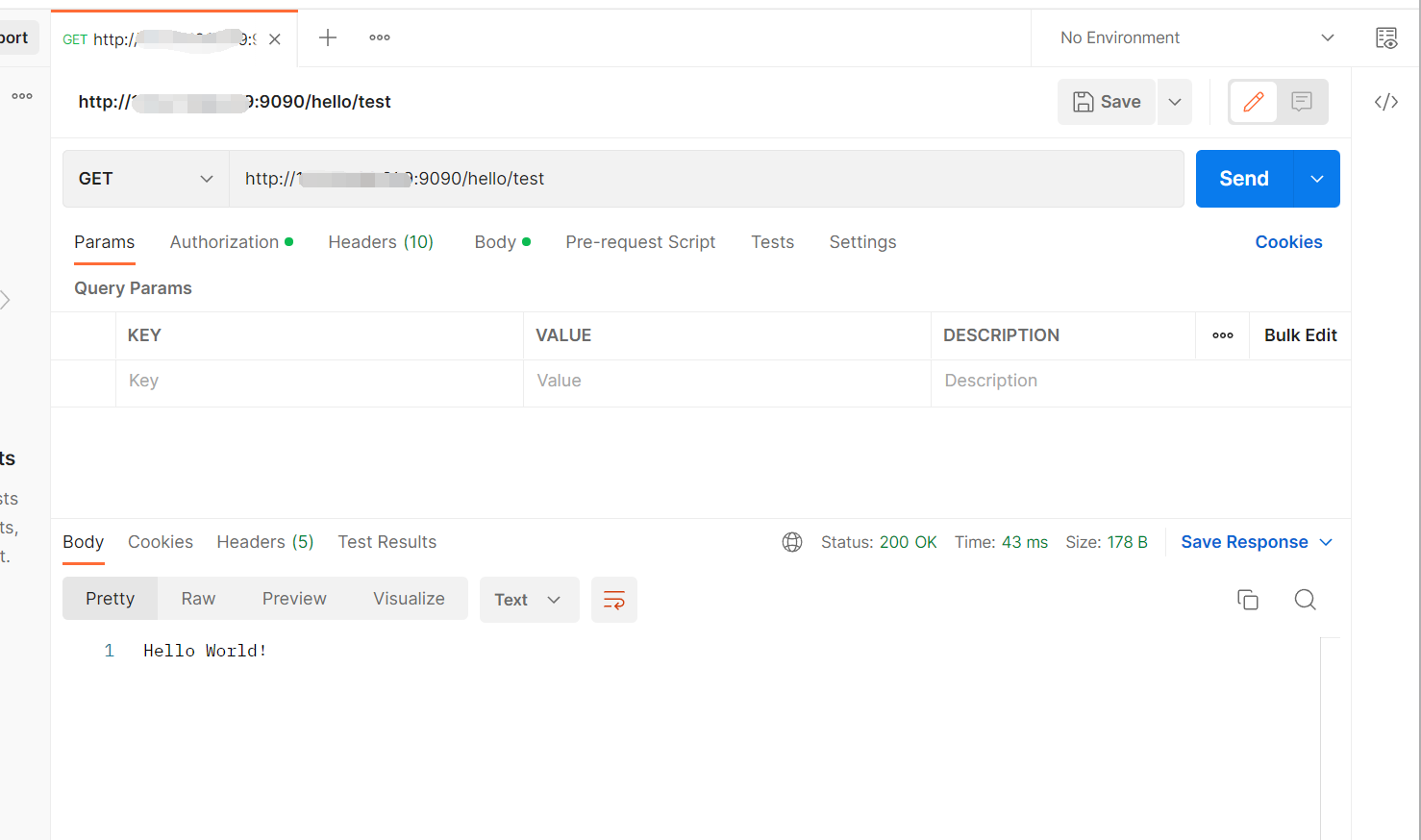
8、使用postman测试接口
五、部署Vue项目
1、打包Vue工程(npm run build命令)并同时编写default.conf文件和Dockerfile文件

2、default.conf文件和Dockerfile文件详细
default.conf配置
server {
listen 80;
server_name ip地址; # 修改为docker服务宿主机的ip
location / {
root /usr/share/nginx/html;
index index.html index.htm;
try_files $uri $uri/ /index.html =404;
}
location /api/ {
proxy_pass http://ip:端口/;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
Dockerfile配置
# 基础镜像使用Nginx
FROM nginx
# 作者
MAINTAINER htt
# 添加时区环境变量,亚洲,上海
ENV TimeZone=Asia/Shanghai
# 将前端dist文件中的内容复制到nginx目录
COPY dist /usr/share/nginx/html/
# 用本地的nginx配置文件覆盖镜像的Nginx配置
COPY default.conf /etc/nginx/conf.d
# 暴露端口
EXPOSE 80
3、上传这三个文件到Linux服务器的同一个文件夹当中,务必放在一起!
4、构建镜像
docker build -t vue . #点千万别漏了,这里取名镜像为vue,可以随便取名!5、查看当前镜像
docker images
6、创建一个新的容器并运行
docker run -d -p 8088:80 --name httvue vue7、查看正在运行的容器
docker ps

8、访问前端页面并测试接口
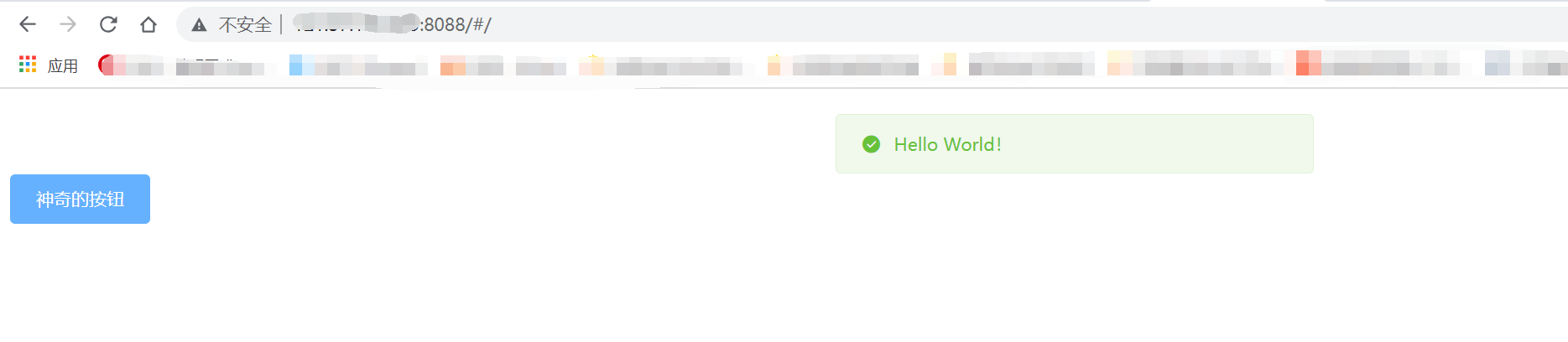
使用docker-compose
简单来说,docker-compose 是一个用于定义和运行多容器 Docker 应用程序的工具。
-
docker run命令的问题:当您使用docker run启动一个容器时,您需要在命令行中输入所有参数(端口映射、卷挂载、环境变量等)。这很繁琐,且不易重复和版本控制。 -
docker-compose的解决方案:它允许您使用一个 YAML 格式的配置文件(通常是docker-compose.yml)来声明式地定义您的应用程序所需的所有服务、网络、卷等。然后,用一个简单的命令(docker-compose up)就能根据配置启动整个应用栈。
安装docker-compose
sudo curl -L https://get.daocloud.io/docker/compose/releases/download/1.25.1/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
安装完后赋予可执行权限
sudo chmod +x /usr/local/bin/docker-compose
检查是否安装成功
docker-compose --version三、编写Dockfile文件
#依赖jdk8环境
FROM openjdk:8
#对外暴露8085
EXPOSE 8085
#复制server-1.0-SNAPSHOT到docker容器中并命名为app.jar
ADD server-1.0-SNAPSHOT.jar app.jar
#执行命令
RUN bash -c 'touch /app.jar'
ENTRYPOINT ["java", "-jar", "/app.jar", "--spring.profiles.active=pro"]
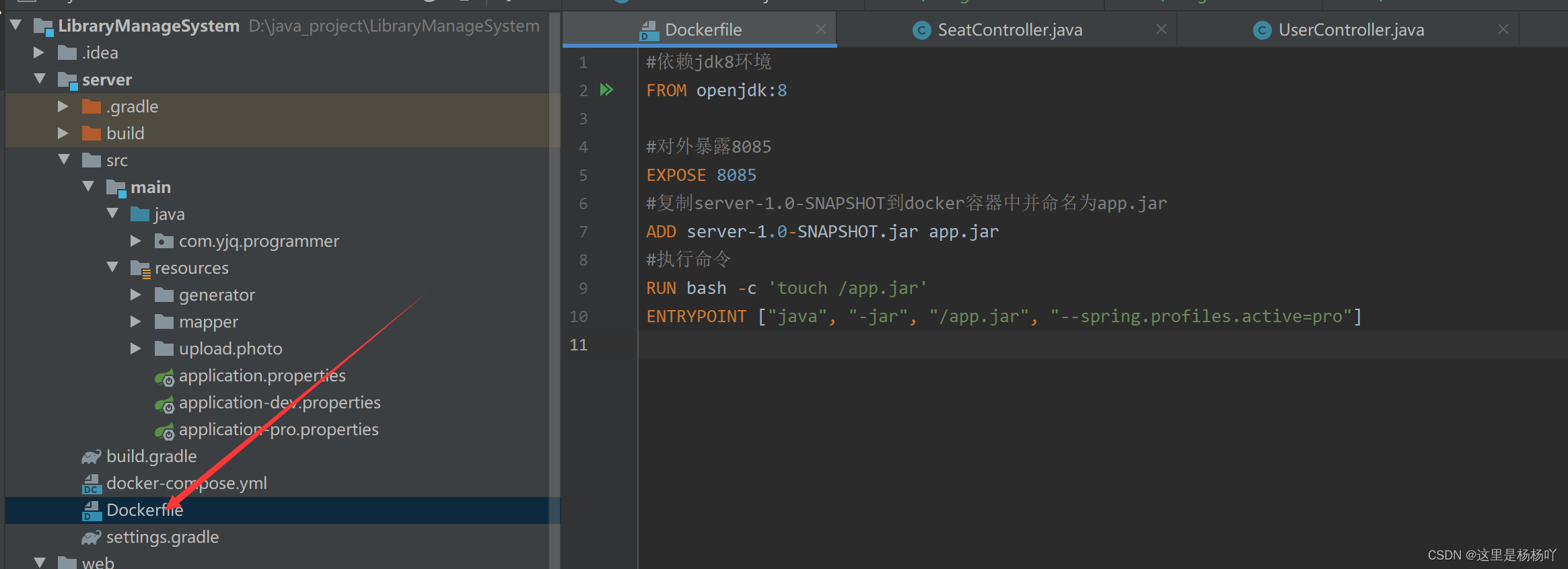
四、编写docker-compose.yml文件
version: "3"
services:
nginx: # 服务名称,用户自定义
image: nginx:latest # 镜像版本
ports:
- 80:80 # 暴露端口
volumes: # 挂载
- /root/nginx/html:/usr/share/nginx/html
- /root/nginx/nginx.conf:/etc/nginx/nginx.conf
privileged: true # 这个必须要,解决nginx的文件调用的权限问题
mysql:
image: mysql:5.7.27
ports:
- 3306:3306
environment: # 指定用户root的密码
- MYSQL_ROOT_PASSWORD=admin
redis:
image: redis:latest
server:
image: server:latest
build: . # 表示以当前目录下的Dockerfile开始构建镜像
ports:
- 8085:8085
depends_on: # 依赖与mysql、redis,其实可以不填,默认已经表示可以
- mysql
- redis
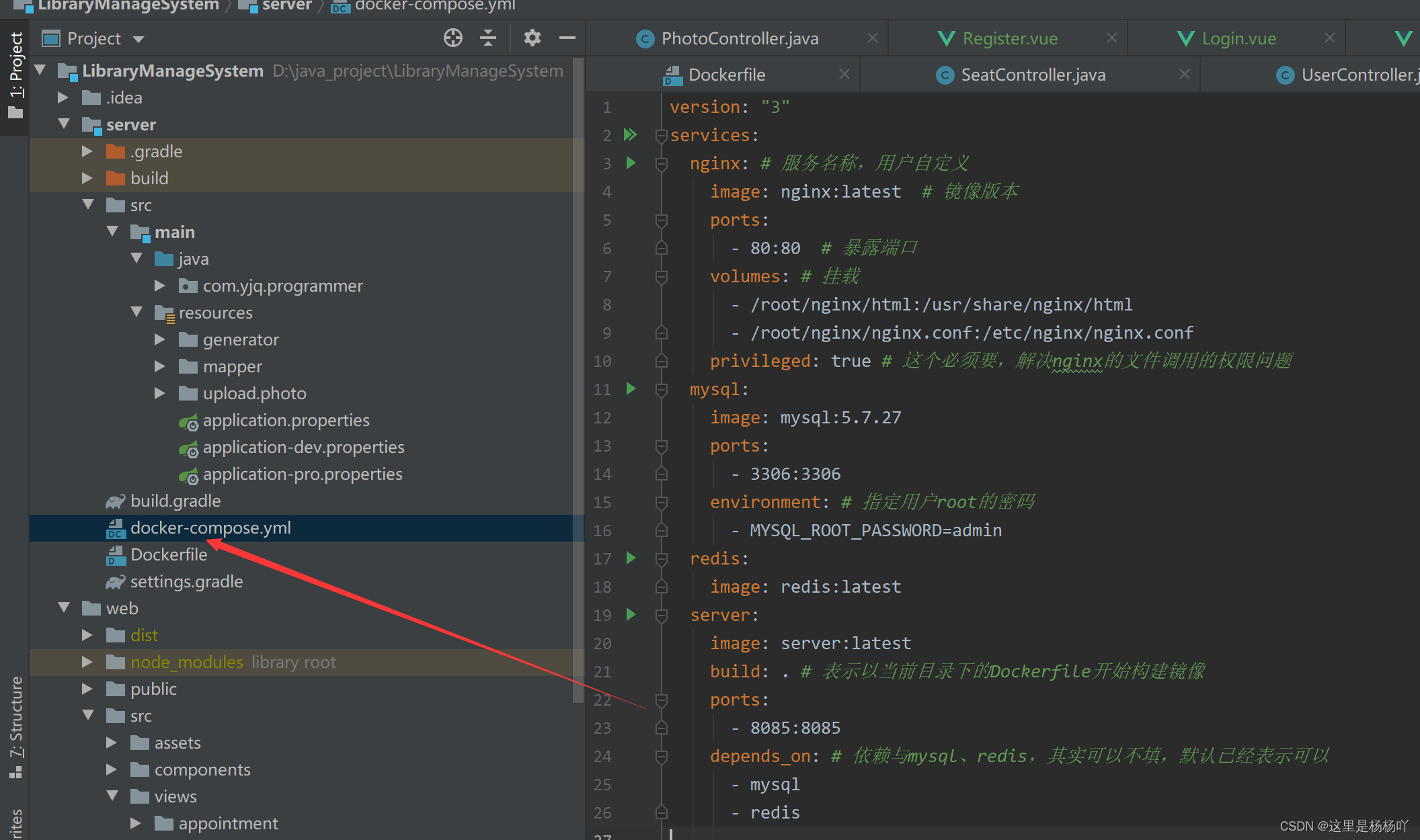
配置文件中MySQL和Redis的IP地址要改成docker-compose.yml文件中的服务名称。
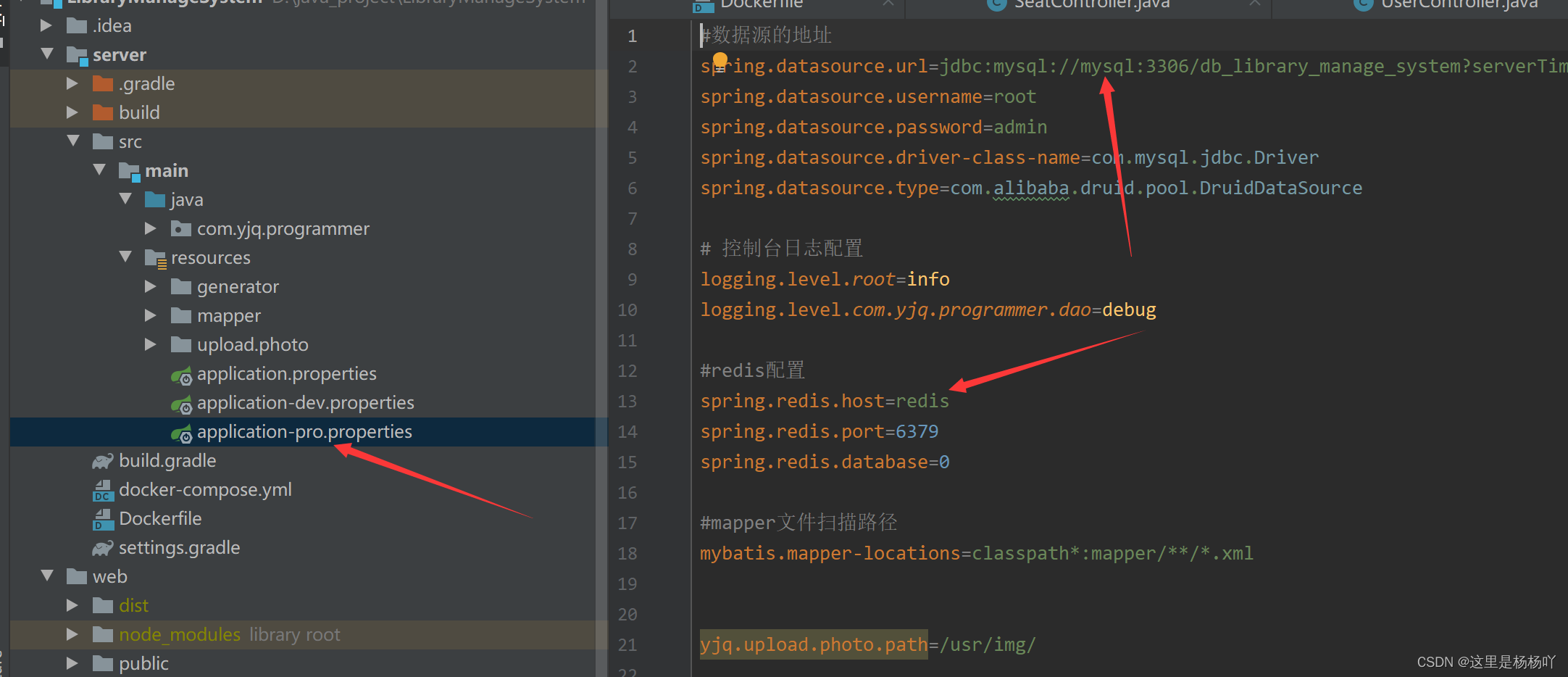
五、编写Nginx的配置文件nginx.conf
现在宿主机创建html目录和nginx.conf文件

编写配置文件nginx.conf
#user root;
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen 80;
server_name 101.132.143.220;
location / {
root /usr/share/nginx/html;
try_files $uri $uri/ /index.html;
index index.html index.htm;
}
location /api/ {
proxy_pass http://101.132.143.220:8085;
proxy_redirect default;
rewrite ^/api/(.*) /$1 break;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
六、部署前端
前端Vue项目打包
npm run build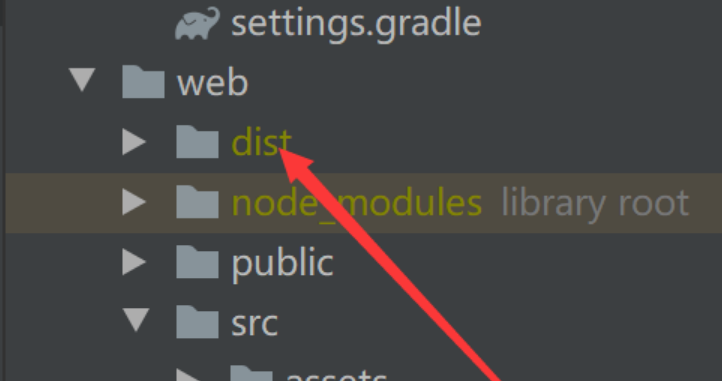
把dist目录下的所有文件放到我们刚才创建的html目录下
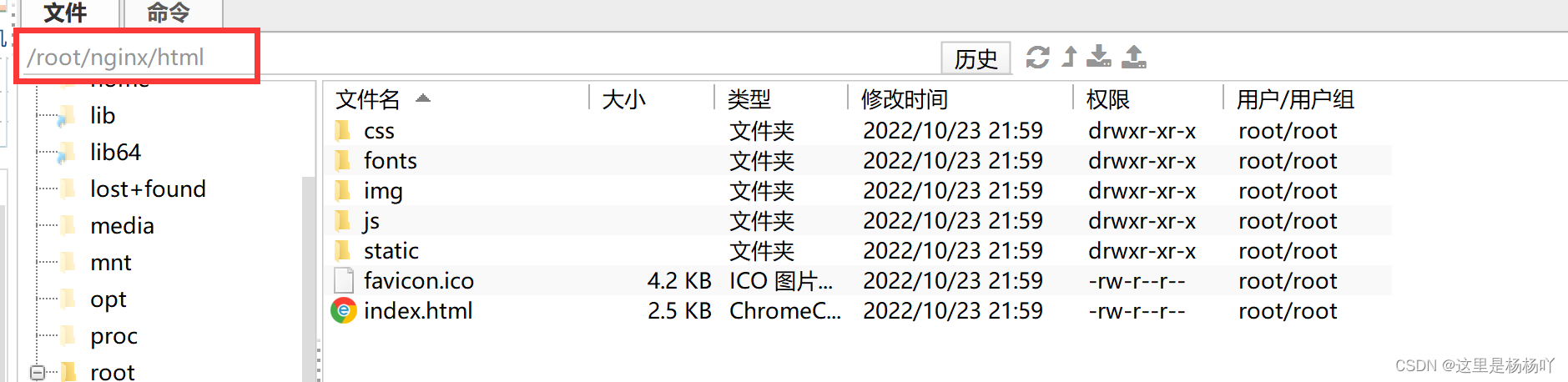
七、部署后端
先将后端打成jar包,然后上传到云服务器上,同时Dockfile文件和docker-compose.yml文件也要上传到云服务器上。

输入命令编排启动服务
docker-compose up -d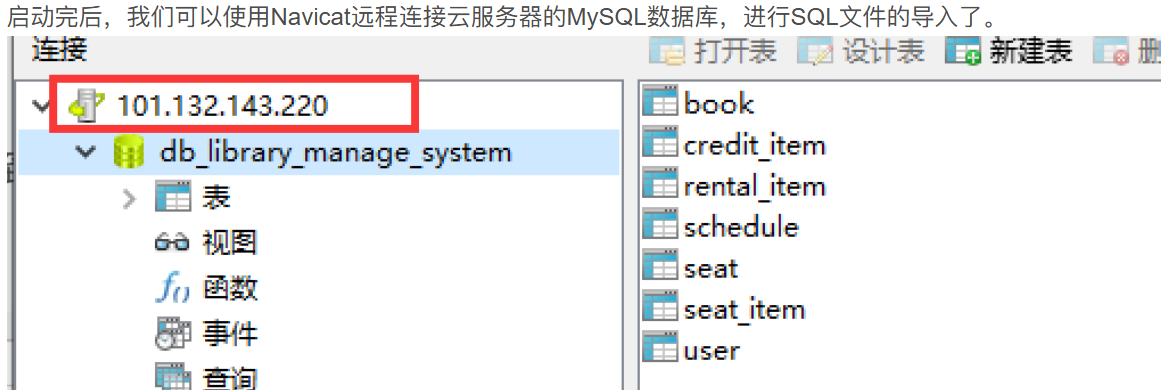


















 1054
1054




 到【灌水乐园】发言
到【灌水乐园】发言









