




1、什么是多租户?
多租户是一种软件架构模式,通俗来讲,就是构建一套应用来服务多个用户,但又能确保一定的隔离性。区别于用户的概念,用户是资源的使用者,而租户一般对应一个组织或一类用户。通常数据权限、计算资源与租户直接绑定,而租户与用户又存在一定的映射关系,这样,用户就可以访问该租户所具备的资源。
多租户
在多租户的架构里,多个租户共享相同的服务器、基础设施,数据库可以是共享的也可以是隔离的,由于多租户必定在用户规模上比单租户来的大,所以多租户一般会有多个实例,共用一套实例代码。租户之间的数据隔离往往采用逻辑隔离的方式,即在代码和数据库层面隔离,所以安全性远没有单租户来的高。
还是举上面的栗子,马云、马化腾和刘强东三个人去租房子,他们因为家里经济困难所以勤工俭学,三个人决定合租一套三室一厅的房子,虽然每个人有自己的房间,但是家里的水电、厨房、卫生间和热水器都是大家一起公用的。隐私性肯定是没有单独自己租房子来的高。
2、为什么需要多租户?
多租户管理的优点在于降低了信息化建设和管理的成本,尤其是在大数据领域,随着数据量快速增长,数据集中化程度越来越高,企业内部对算力的需求也逐步增大,大量业务应用构建在统一的大数据平台之上,对资源的控制、对权限的控制也越来越越严格,各子公司、各部门、各业务线既有共享资源的需求、又希望通过一定的数据隔离和资源隔离技术来解决安全性和资源抢占的问题,所以多租户管理在大数据技术方案中已经变成了一个必选方案。
多租户可以用来干什么?
多租户可以让用户买到便宜并且部署快速、方便的软件服务
3、大数据的多租户管的是什么?
大数据的技术组件众多,但无外乎可以分为数据存储型的、数据查询型的、数据计算型的。所以多租户管理就是针对这些核心组件的权限、资源和配额进行管理。
- 存储型的,主要就是分布式存储系统HDFS,配额和目录权限管理;
- 数据查询型的,主要是hbase、hive,库、表、字段相关的scheme权限管理,以及相应的增删改查权限;
- 计算型的,主要是yarn,管理cpu和内存;
4、常见的大数据多租户方案设计
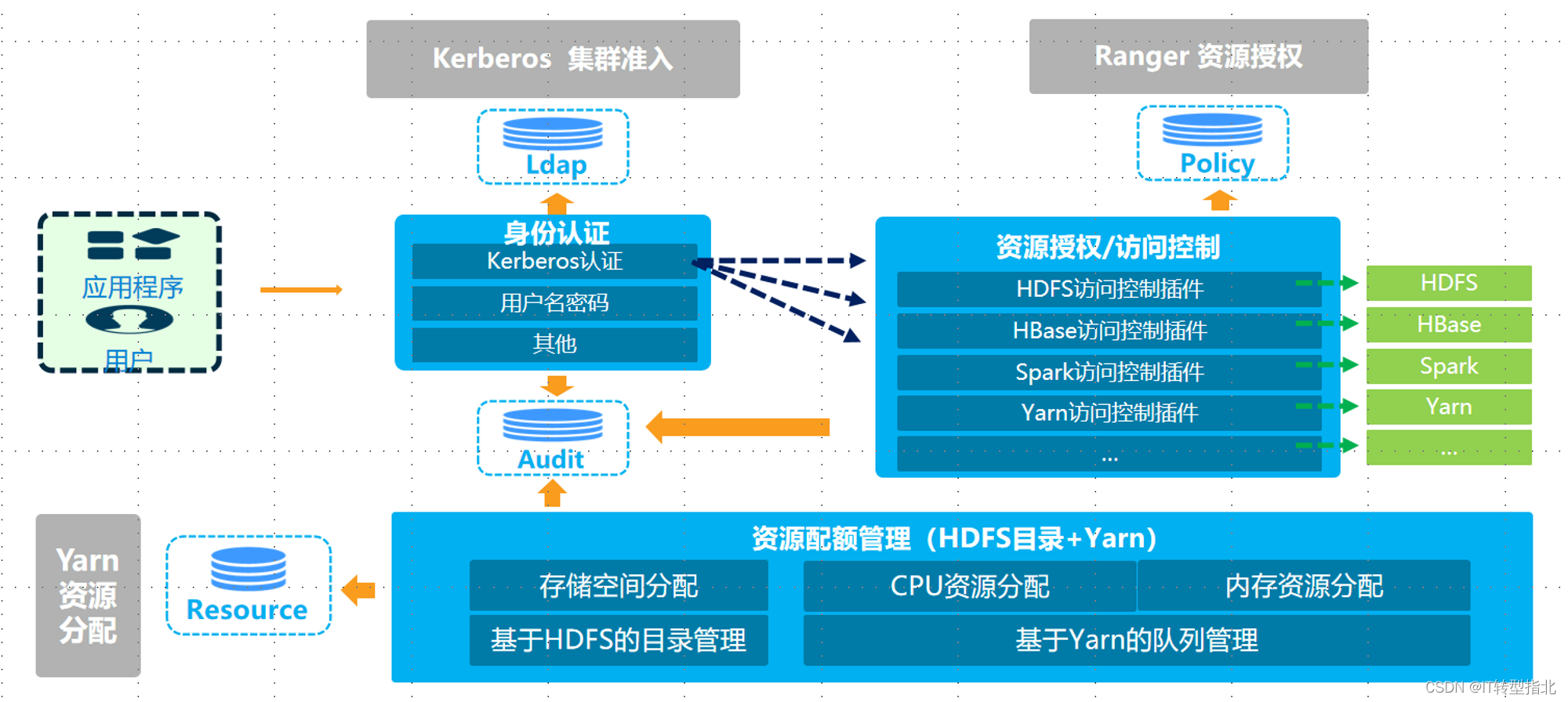
由于开源大数据技术的复杂性,每个组件的数据隔离、资源配额控制都大不相同,所以也就没有统一的产品或技术能完成多租户的管理,现在比较常用的是通过多套技术组合来实现。先看下常见需求:假设一个公司有一个大数据平台,上面有两个部门A、B,两个部门都希望有独享的计算资源,做到互不影响。又希望数据存储和查询做到隔离,避免数据泄露。从使用者角度讲,能满足他们的隔离性需求即可,这里面就包括数据的隔离性和资源的隔离性。但从提供者角度,也就是平台,还要考虑安全客户端的认证鉴权、统一用户中心管理、统一权限管理、用户操作审计等等一系列的管理方案,同时还要考虑资源的超卖问题(毕竟业务申请的资源都会虚高,所以适当的超卖是不影响的)。这里边涉及到的技术体系就包括Kerberos(统一认证)、Ranger权限管理(CDH提供的是Sentry)、Ldap(身份信息管理)、Yarn的队列机制等等
从平台层面,
第一步:先规划YARN的队列划分,可以考虑一个租户一个队列,通过给队列划分配额来控制队列资源,根据业务使用模式配置是否抢占。
第二步:编写ldif文件,将组织信息、用户信息等初始化到ldap内,相当于创建一个租户,ldap实现了身份信息管理。
第三步:kerberos会同步ldap内的用户,并针对每个租户生成一个票据,可以理解为令牌文件,用户只有在安全客户端上用这个令牌做认证,才能执行后续的平台操作。
第四步:在ranger中配置权限策略,ranger很强大, 可以通过plugin的方式适配几乎所有的核心大数据组件,来完成大数据组件的权限管理。ranger会从ldap同步身份信息(需要修改配置),将租户的身份信息与权限信息做关联,就完成了权限的管理。这里就包括yarn的队列权限、hive的库表字段权限、hbase的schema权限等等。
第五步:ranger还提供了审计功能,可以对提交到大数据平台的操作,包括hive的访问、hbase的访问、hdfs目录的访问等等做检索。记录的信息包括:时间、发起请求的主机IP、租户信息(ldap内的身份信息)、执行的操作(SQL或其他执行命令)、是否成功等信息。
从用户使用层面,只需要登录到主机上,将令牌做一个kinit,然后访问大数据平台资源,包括提交任务到队列、访问hive表。而不需要关心底层的细节,就已经实现了资源隔离和数据安全隔离。
二、一个多租户平台
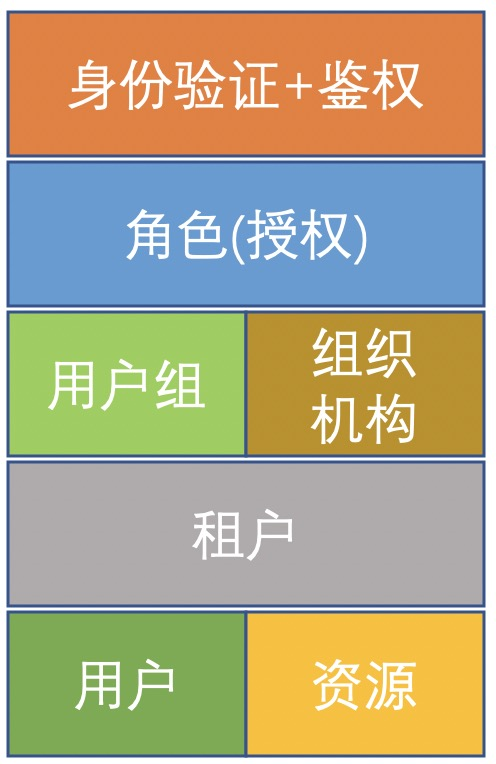
很多时候,我们需要有租户的概念,使用租户来分开用户的业务数据。譬如钉钉就是一个多租户系统,每家企业在钉钉里面都是一个租户。我们可以在用户之上增加租户模块,让租户和用户、资源(应用)建立多对多的关系。同时,用户组、组织机构和角色就都可以按租户进行区分了。
假设每个租户都有「管理员」这个角色,那么1万个租户在系统里面就会有1万个名字叫管理员的角色,只不过每个租户都只能看到自己的那个「管理员」角色罢了。如果A租户建立了一个「业务员」角色,那么B租户是没有这个角色的,他想要的话,必须自己去建立一个。
四、三者之间的关系:
1、租户可以有多个角色和用户
2、用户可以有多个角色和租户
3、角色赋予用户操作功能的权限
用户代表员工A, 他持有相关的信息,例如姓名、工号、电子邮箱等。
租户对应项目组。员工A可以同时属于不同的几个项目组。当员工A提出出差费用报销的请求时,必须指定他所属的项目组的一个。
而角色则规定了员工A在某一个项目组所拥有的权限,比如什么费用可以报销,什么不可以报销。


















 848
848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











