







 分位数回归用于研究因变量与自变量在不同分布位置的关系,特别是在离群值和非正态分布情况下,提供更稳健的估计。与均值回归相比,分位数回归能更好地描述被解释变量的条件分布。R语言中利用包实现分位数回归,通过设置不同分位数,可以分析解释变量对不同收入群体的影响。例如,在IQ与收入水平的关系中,分位数回归显示,对于高收入群体,IQ的边际效应更显著。
分位数回归用于研究因变量与自变量在不同分布位置的关系,特别是在离群值和非正态分布情况下,提供更稳健的估计。与均值回归相比,分位数回归能更好地描述被解释变量的条件分布。R语言中利用包实现分位数回归,通过设置不同分位数,可以分析解释变量对不同收入群体的影响。例如,在IQ与收入水平的关系中,分位数回归显示,对于高收入群体,IQ的边际效应更显著。
分位数回归(quantile regression)R实现
一、基本介绍
回归分析的主要目的:实证检验理论分析中因变量与自变量之间的关系。传统的均值回归,主要使用因变量的条件均值函数来描述在自变量每一个特定数值下的因变量的均值,从而揭示自变量与因变量的关系。
条件均值模型存在不足:当研究收入分配等问题时,我们可能主要关注的是处于分布低尾的穷人和分布高尾的富人等处于因变量非中心位置的情况,而 (1) 条件均值模型主要考虑的是因变量的均值,难以扩展到这种非中心位置,此时只能使用分位数模型进行估计。此外,(2) 条件均值模型经常受到离群值的困扰。在使用条件均值模型进行实证研究时,面对存在离群值的样本数据时,最常使用的方法是对数据进行缩尾,剔除离群值。然而,很多时候剔除离群值会导致对中心位置的测度具有误导性结论。尤其, (3) 条件均值模型假定残差项服从独立同分布、正态性、方差齐性等关键问题在现实中难以满足。
因此,提出了中位数模型替代条件均值模型。中位数是表示分布的中心位置,即0.5分位数。其他位置上的分位数则描述了一种分布的非中心位置。随着协变量的变化,分位数回归模型则强调了条件分位数的变化。由于所有分位数都是可用的,所以对任何预先决定的分布位置进行建模都是可能的。因此,可以对分布的任意非中心位置进行建模,可选的研究的问题也就变得更加广泛。例如贫困问题(对穷人进行研究)、收入分配问题(穷人与富人的收入),教育问题(好成绩与差成绩),税收问题(对穷人与富人的不同影响)等等。与条件均值模型相比,分位数回归则具有无法比拟的优势。
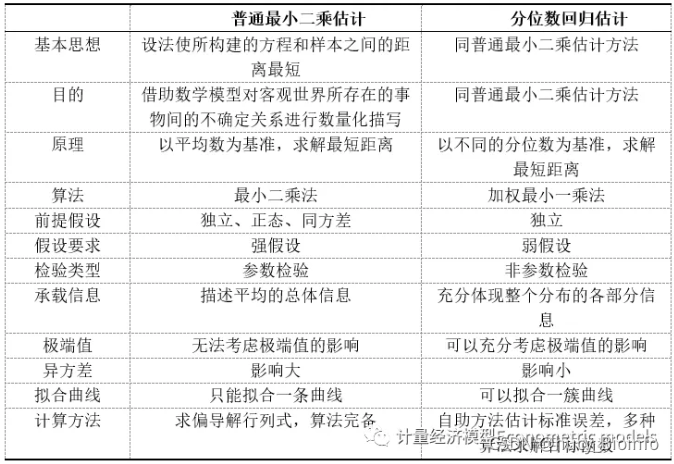
普通最小二乘估计(OLS)与分位数回归估计的异同:
分位数回归是估计一组回归变量X与被解释变量Y的分位数之间线性关系的建模方法。以往的回归模型实际上是研究被解释变量的条件期望。而人们也关心解释变量与被解释变量分布的中位数、分位数呈何种关系。它最早由Koenker和Bassett(1978)提出。
OLS回归估计量的计算是基于最小化残差平方。分位数回归估计量的计算也是基于一种非对称形式的绝对值残差最小化。其中,中位数回归运用的是最小绝对值离差估计(LAD,least absolute deviations estimator)。
分位数回归的优点:
(1) 能够更加全面的描述被解释变量条件分布的全貌,而不是仅仅分析被解释变量的条件期望(均值),也可以分析解释变量如何影响被解释变量的中位数、分位数等。不同分位数下的回归系数估计量常常不同,即解释变量对不同水平被解释变量的影响不同。
(2) 中位数回归的估计方法与最小二乘法相比,估计结果对离群值则表现的更加稳健,而且,分位数回归对误差项并不要求很强的假设条件,因此对于非正态分布而言,分位数回归系数估计量则更加稳健。
目前,分位数回归已经获得了巨大的发展,不仅可以进行简单的横断面数据的估计,而且还可以进行panel数据模型估计、干预效应模型估计、计数模型估计、因变量是区间值的logistic模型估计、工具变量估计等。
二、使用分位数回归的原因
大部分的计量模型都是在估计条件期望值,因为条件期望值是因变量最好的估计值。对于非连续变量,期望值本身已经能够很大程度上描述出随机变量的分布。但是对于连续变量,仅仅依靠期望值并不能完整描述出变量的分布形态。比如收入水平,中位数相比于平均数更有代表性。因为平均数容易受到异常值的影响,如果只考虑平均值,那么穷人就会被富人代表,一个国家的平均收入也许很高,但是这或许只能代表一小部分人,而中位数则能代表大部分普通人的真实收入。
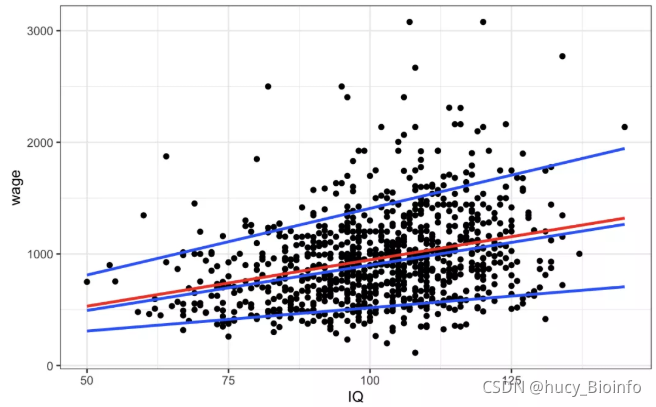
下面这幅散点图反映了个人智商水平(IQ)和收入水平(wage)之间的关系,其中红线就是使用 OLS 进行线性回归得到的,蓝线从上至下依次为 0.9 分位数、中位数、0.1 分位数的回归线。可以发现,对于前 10% 的收入群体,IQ 的增长对收入的边际效应更为明显。所以,使用分位数回归能够更加全面完整的分析因变量的条件分布。
三、R 语言实现分位数回归
R语言进行分位数回归需要quantreg包,其中, rq()函数的用法和 lm() 类似,但是多了一个设定分位数的参数 tau,这个参数可以接受单个值,也可以接受向量值。plot() 函数则可以绘制不同分位数回归的系数值的折线图,和 OLS 线性回归的系数值做比较。
本文使用wooldridgeR包的示例数据集 wage2 进行解释说明,回归的因变量是收入水平 wage ,IQ某种程度上可以指代受访者的个人能力,educ 表示受访者的受教育年限,married 和 black 都分类变量,取值 1 表示受访者分别为已婚和黑裔。
首先只采用 IQ 作为自变量进行回归,分位数选取 [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]。
library(tidyverse)
library(wooldridge)
library(quantreg)
library(AER)
### 查看分布
ggplot(data = wage2, ma 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1402
1402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











