






昨天跟女朋友斗图
被狠狠挖苦了一番

额…… 那都不重要
于是想起来,老子最近学了爬虫
你很开心准备去安排她一波
我们准备下手的网站
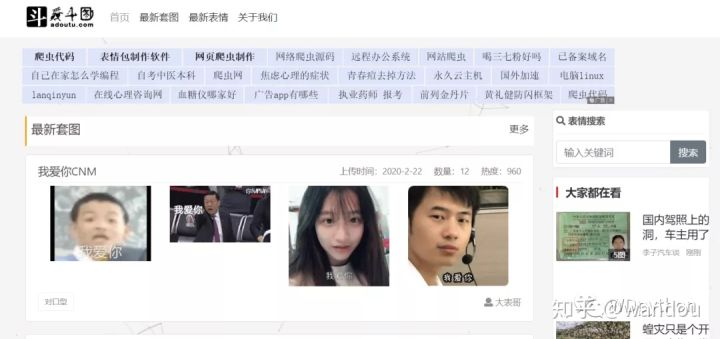
突然发现可以进行搜索
那我们就找“装逼”的相关图片
https://www.doutula.com/search?keyword=装逼
最后得到了这个链接
我们查看一下网页元素
这个就是图片链接 了
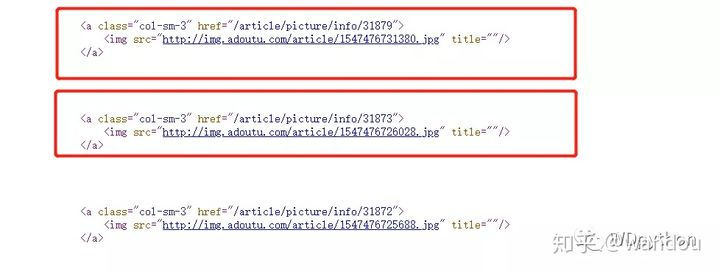
那就开始正则安排一下
pat = '<img src="(http://img.adoutu.com/picture/\w.*?)"'
import urllib.request
import urllib.parse
import re
#url = "https://www.doutula.com/search?keyword=盘他"
# 这里有中文,是不能识别的,我们需要重新编码一下
name = “装逼”
search = urllib.parse.quote(name)
url = "http://www.adoutu.com/search?keyword=" + search
data = urllib.request.urlopen(url).read().decode("utf-8")
pat = '<img src="(http://img.adoutu.com/picture/\w.*?.*?)"'
pic_url = re.compile(pat).findall(data)
for i in range(len(pic_url)):
str_ = pic_url[i][-4:]
# 图片有的后缀不一样我们截取出后缀
urllib.request.urlretrieve(pic_url[i], "F:\\斗图\\" + str(i) + str_)
# 保存出来ok l 我们来看一下成果
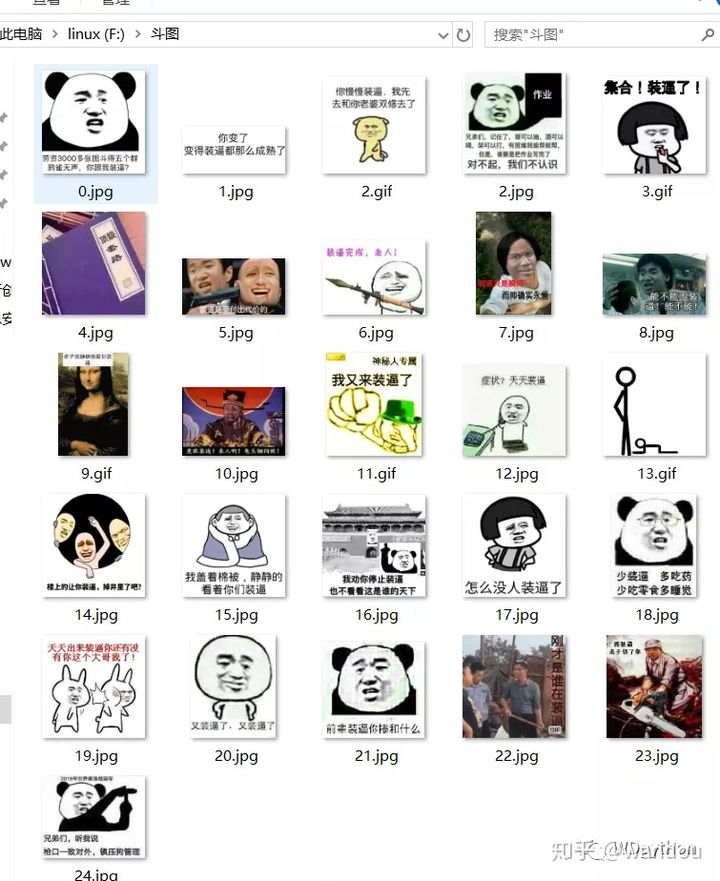
我们直接保存出来吧
于是你又加了个循环,
去爬了第二页,第三页
爽 的 不要

突然程序报错了
提示“对方服务器拒绝了你的访问”

心里一凉 卧槽ip被封了
你又突然想起来可以构建一个
ip代理池
于是开始盘他!

网上有很多免费的ip可以使用
但是不稳定
可能一会就不行了
所以你就花了几块钱买了1000ip
并通过官网提供的api来调用

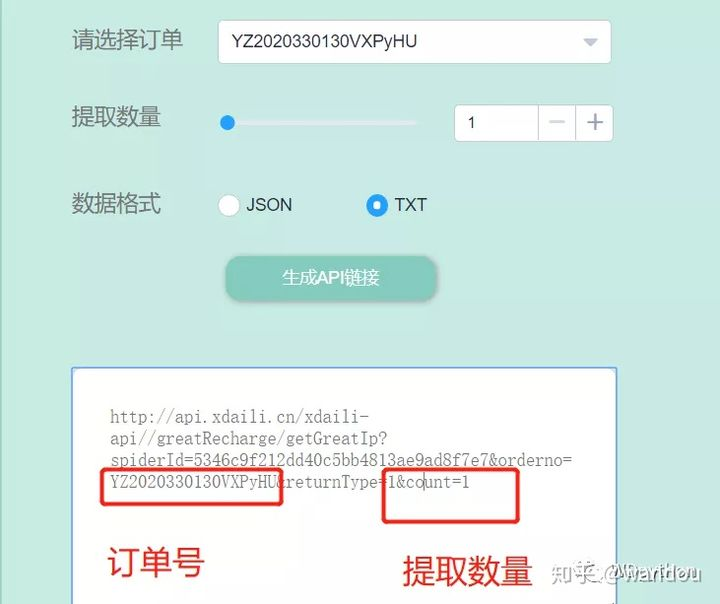
我们打开他的接口看一下结果
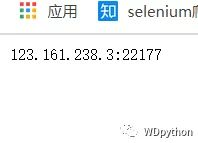
哦吼看来可以
那就开撸
我们怎么获取到接口返回的ip呢
ip= urllib.request.urlopen("http://api.xdaili.cn/xdaili-api//greatRecharge/getGreatIp?spiderId=5346c9f212dd40c5bb4813ae9ad8f7e7&orderno=YZ2020330130VXPyHU&returnType=1&count=1").read().decode("utf-8")
print(“当前ip:” + ip)打开读取一下就OK
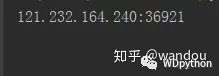
OK成功获取
然后生成一个代理对象proxy
proxy = urllib.request.ProxyHandler({"http": ip, "https": ip})使用ProxyHandlerc传入一个代理,这个代理是一个字典,字典的key是代理服务器能够接收的类型一般是http,https,值就是代理ip
opener = urllib.request.build_opener(proxy)build_opener 有什么作用
因为基本的urlopen()函数不支持验证,cookie,以及其他高级功能,所以需要使用build_opener 来创建自己的opener对象
然后我们就要进行使用代理ip进行访问了
url = "http://www.adoutu.com"
# 斗图网站
open = opener.open(url).read().decode("utf-8")
print(len(open))然后我们为了验证是否访问成功
我们输出一下我们斗图网站的字节数
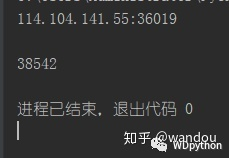
OK,访问成功了
我们为了访问的更加真实
我们伪装一下他的头部
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
}
request = urllib.request.Request(url=url, headers=headers)
# 封装一下
open = opener.open(request ).read().decode("utf-8")
# 我们在访问一下
print(len(open))
# 输出字节数
也成功了
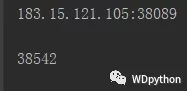
这样单次访问就OK了
我们就可以使用代理ip继续爬图了
于是我们的代码就撸好了
#coding:utf-8
import urllib.parse
import urllib.request
import re
ip_url = "http://api.xdaili.cn/xdaili-api//greatRecharge/getGreatIp?spiderId=5346c9f212dd40c5bb4813ae9ad8f7e7&orderno=YZ2020330130VXPyHU&returnType=1&count=1"
ip = urllib.request.urlopen(ip_url).read().decode("utf-8")
print("当前ip:" + ip)
proxy = urllib.request.ProxyHandler({"http": ip})
opener = urllib.request.build_opener(proxy)
name = "装逼"
search = name
search = urllib.parse.quote(search)
url = "http://www.adoutu.com/search?keyword=" + search
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
}
request = urllib.request.Request(url=url, headers=headers)
open = opener.open(request).read().decode("utf-8")
pat = '<img src="(http://img.adoutu.com/picture/\w.*?.*?)"'
try:
pic_url = re.compile(pat).findall(open)
for i in range(len(pic_url)):
str_ = pic_url[i][-4:]
urllib.request.urlretrieve(pic_url[i], "F:\\斗图\\" + str(i) + str_)
except:
print("没有找到")
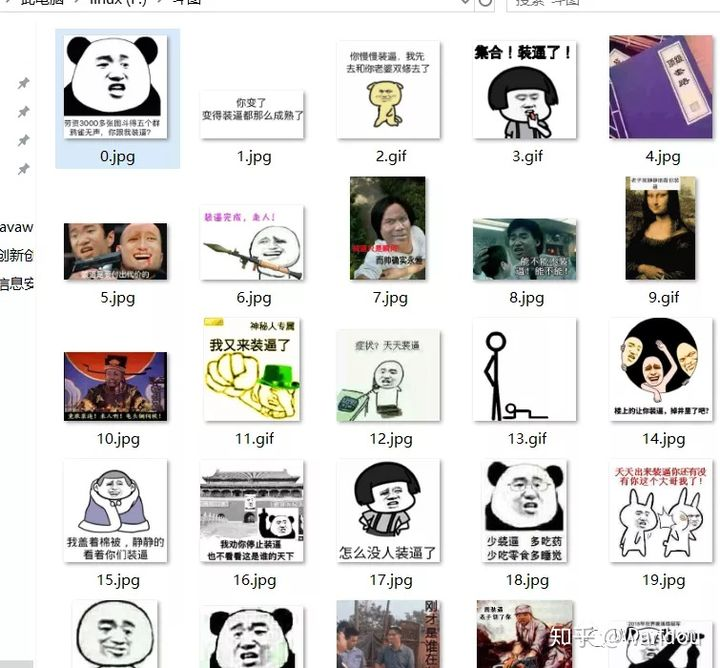

封我 ip 臭弟弟
一样安排 你
我们有了图片就可以整个微信机器人 啦
使用itchat 模块
到时候再说这个模块
实现可以发送词语然后发图
问斗图哪家强??


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









