









1、需求
1、爬取知乎话题为"如何看待xxx"的数据。
2、根据话题下的回答者分析他们的用户的信息,找到高质量答主的信息。
2、解析数据接口
使用chrome抓包。可知话题数据的接口为
https://www.zhihu.com/api/v4/search_v3?t=general&q=%E5%A6%82%E4%BD%95%E7%9C%8B%E5%BE%85&correction=1&offset={offset}&limit=20&lc_idx=0&show_all_topics=0
其中、offset控制起始数据的值、limit控制数据量、q=xxx控制话题名。
找到数据接口后单纯的访问,无法得到相关的数据。
使用requests加入对应的headers、cookies后,能够成功得到数据。可是对不同的页面,同一cookie会失效,因此,我比较了下两个页面的不同的cookie。发现不同cookie的主要不同字段在于x-zse-86这个参数。
因此,我们需要解析这个字段。详细的解析过程看:https://blog.youkuaiyun.com/weixin_40352715/article/details/107546166
我直接调用,并且成功返回了正确的x-zse-86参数。
然后构建对应的url。解析对应的页面,得到相应的结果。
3、对应的代码如下
import execjs
import hashlib
import pandas as pd
title = []
id_ = []
author = []
offset = 0
for i in range(10):
url = f"/api/v4/search_v3?t=general&q=%E5%A6%82%E4%BD%95%E7%9C%8B%E5%BE%85&correction=1&offset={offset}&limit=20&lc_idx=0&show_all_topics=0"
referer = "https://www.zhihu.com/search?type=content&q=%E5%A6%82%E4%BD%95%E7%9C%8B%E5%BE%85"
f = "+".join(["3_2.0", url, referer, '"AACSLMY7lBGPTo9fXdy2pmiGQ4ZVVUcqzC4=|1594785557"'])
fmd5 = hashlib.new('md5', f.encode()).hexdigest()
with open('g_encrypt.js', 'r') as f:
ctx1 = execjs.compile(f.read(), cwd=r'/usr/local/lib/node_modules')
encrypt_str = ctx1.call('b', fmd5)
headers = {
"referer": referer,
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36",
"cookie": 'd_c0="AACSLMY7lBGPTo9fXdy2pmiGQ4ZVVUcqzC4=|1594785557";',
"x-api-version": "3.0.91",
"x-zse-83": "3_2.0",
"x-zse-86": "1.0_%s" % encrypt_str,
}
print(headers)
r = requests.get("https://www.zhihu.com" + url, headers=headers)
# print(r.text)
for i in r.json()['data']:
try:
id_.append(i['object']['question']['id'])
author.append(i['object']['author']['name'])
title.append(i['object']['question']['name'])
print(i['object']['question']['name'])
except:
pass
offset += 20
time.sleep(5)
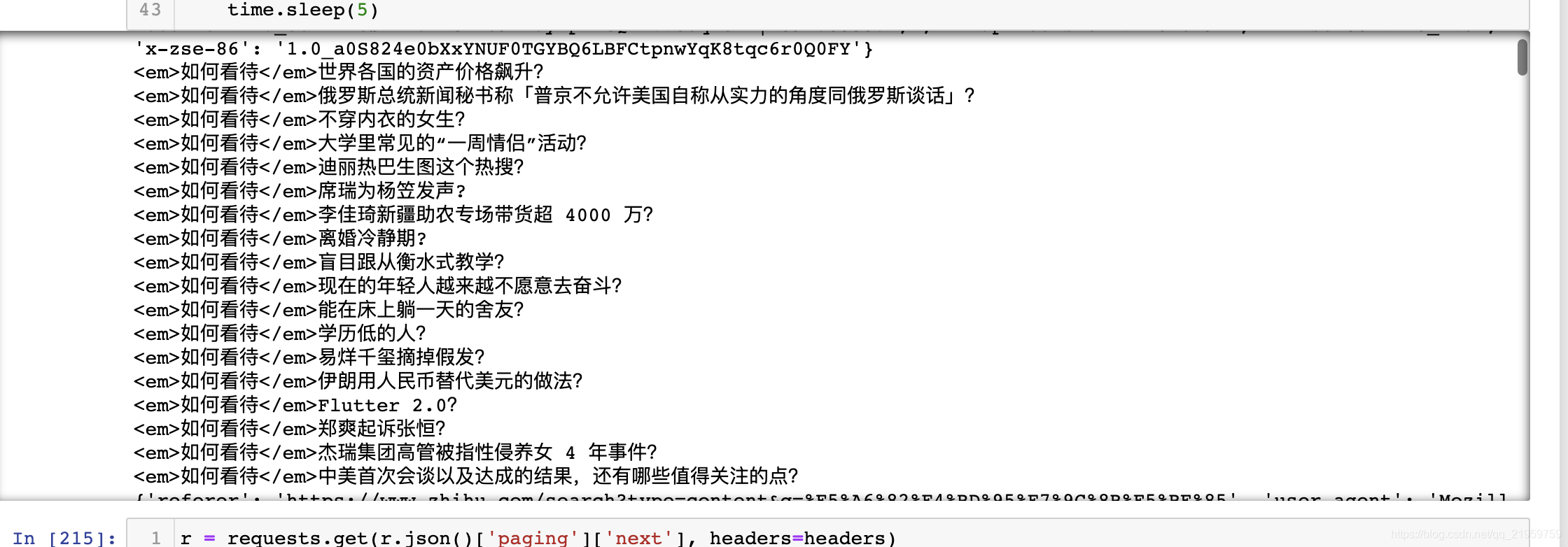
本文设置了10次循环爬取了接近200个对应的话题。(可自行设计储存到数据库中)
效果如下:
4、对应话题的答案
得到对应的话题之后,我们就可以遍历话题得到对应的答复了。
答案的接口:
'https://www.zhihu.com/api/v4/questions/{ids}/answers?include=data%5B*%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B*%5D.mark_infos%5B*%5D.url%3Bdata%5B*%5D.author.follower_count%2Cbadge%5B*%5D.topics%3Bdata%5B*%5D.settings.table_of_content.enabled&offset={ofset}&limit=20&sort_by=default&platform=desktop
其中offset控制起始值、ids为话题的id(如上述代码id_)
这个api不需要对cookie进行设置,可直接获取。因此、我们可以使用对线程批量爬取。
5、高质量答主的信息
API:https://api.zhihu.com/people/{id}
结果如下: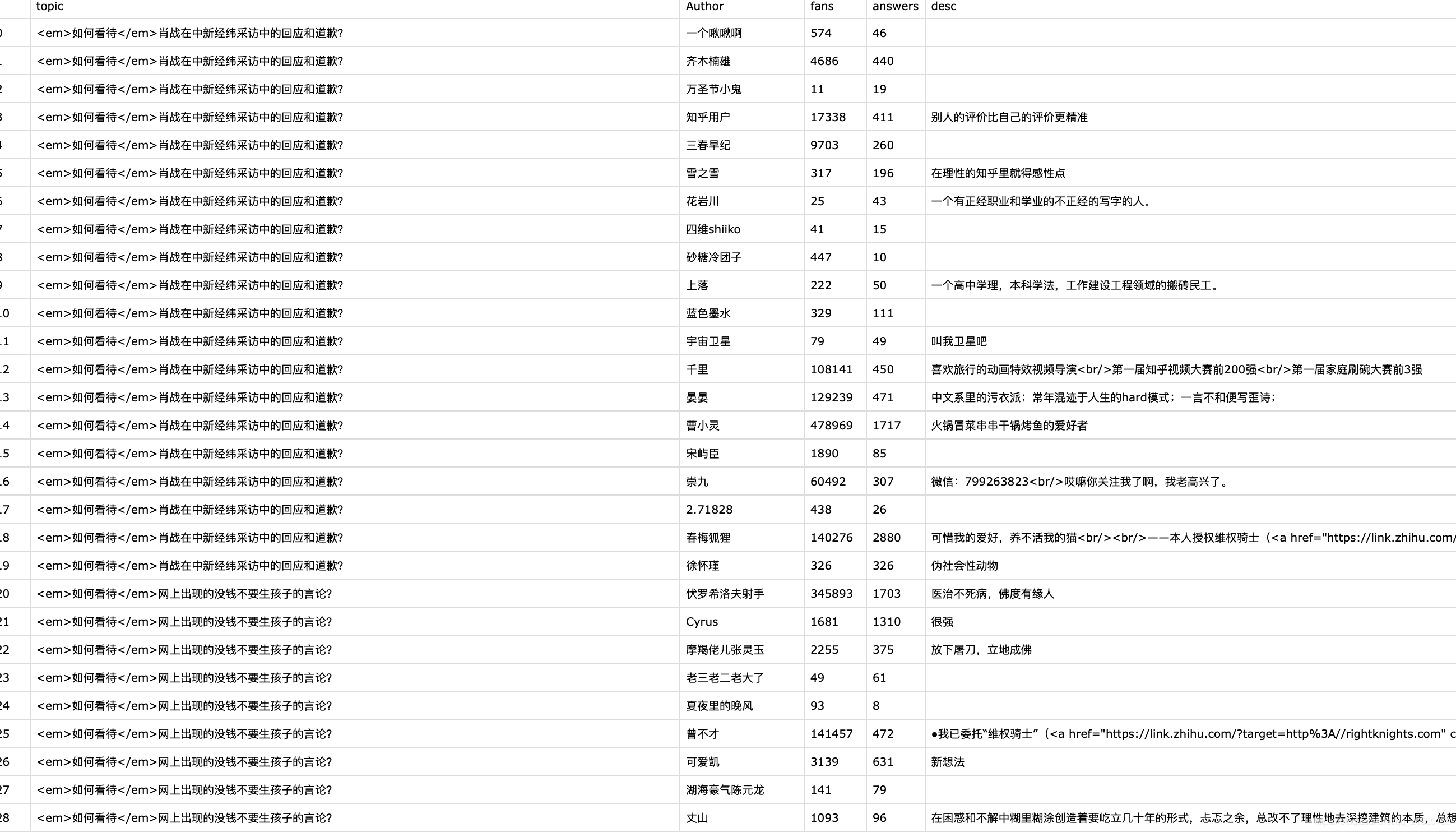
有需要代码和定制知乎爬虫的联系v:hzt990224

















 8246
8246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









