






 本文详细介绍了在CentOS7环境下安装和配置Hadoop2.6.3的过程,包括环境准备、源码包下载、环境变量设置、用户和组的创建、主要配置文件的编辑、HDFS格式化、Hadoop启动、测试以及Python3调用Hadoop API的方法。
本文详细介绍了在CentOS7环境下安装和配置Hadoop2.6.3的过程,包括环境准备、源码包下载、环境变量设置、用户和组的创建、主要配置文件的编辑、HDFS格式化、Hadoop启动、测试以及Python3调用Hadoop API的方法。
一、centos7安装Hadoop2.6.3
1.环境准备
centos7中一般已经自带JDK
[root@wj ~]# java -version
openjdk version "1.8.0_102"
OpenJDK Runtime Environment (build 1.8.0_102-b14)
OpenJDK 64-Bit Server VM (build 25.102-b14, mixed mode)[root@localhost profile.d]# yum -y install java-1.8.0-openjdk*
Centos7关闭防火墙
查看状态: systemctl status firewalld
开机禁用 : systemctl disable firewalld
开机启用 : systemctl enable firewalld
Centos7 关闭selinux服务
[root@wj ~]# setenforce 1
[root@wj ~]# getenforce
Enforcing
[root@wj ~]# setenforce 0
[root@wj ~]# getenforce
Permissive新建bdapps目录
[root@wj ~]# mkdir /bdapps/
并将源码包上传到linux上,我这里是传到 /bdapps/下
3.解压源码包
[root@wj ~]# ls hadoop-2.6.2
[root@wj ~]# tar -zxvf /home/zhanggen/Desktop/hadoop-2.6.2.tar.gz -C /bdapps/
4.设置Java和Hadoop相关环境变量
[root@wj ~]#vi /etc/profile.d/hadoop.sh
export HADOOP_PREFIX=/bdapps/hadoop
export PATH=$PATH:${HADOOP_PREFIX}/bin:${HADOOP_PREFIX}/sbin
export HADOOP_YARN_HOME=${HADOOP_PREFIX}
export HADOOP_MAPPRED_HOME=${HADOOP_PREFIX}
export HADOOP_COMMON_HOME=${HADOOP_PREFIX}
export HADOOP_HDFS_HOME=${HADOOP_PREFIX}
使环境变量生效:
[root@wj ~]# source /etc/profile.d/hadoop.sh
新建用户和组,并授权
[root@wj ~]# groupadd hadoop
[root@wj ~]# useradd -g hadoop hadoop[root@wj ~]# mkdir -pv /data/hadoop/hdfs/{nn,dn,snn}
[root@wj ~]# chown -R hadoop:hadoop /data/hadoop/hdfs/[root@wj ~]# cd /bdapps/hadoop/
[root@wj ~]# mkdir logs
[root@wj ~]# chown -R hadoop:hadoop ./*5.Hadoop主要配置文件(/bdapps/hadoop-2.6.2/etc/hadoop)
(1)core-site.xml
针对NameNode IP地址 、端口(默认为8020)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://0.0.0.0:8020</value>
<final>false</final>
</property>
</configuration>
(2)hdfs-site.xml
针对HDFS相关的属性,每一个数据块的副本数量、NN和DA存储数据的目录 step6中创建的目录。
<configuration>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>0.0.0.0:50075</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/hadoop/hdfs/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/hadoop/hdfs/dn</value>
</property>
<property>
<name>fs.checkpoint.dir</name>
<value>file:///data/hadoop/hdfs/snn</value>
</property>
<property>
<name>fs.checkpoint.edits.dir</name>
<value>file:///data/hadoop/hdfs/snn</value>
</property>
</configuration>
(3)mapred-site.xml(指定使用yarn)如果没有参照mapred-site.xml.template新建一个
指定MapReduce是单独运行 还是运行在yarn之上,Hadoop2肯定是运行在yarn之上的;见 二、Hadoop的运行模型
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>(4)yarn-site.xml
yarn-site.xml 用于配置YARN进程及YARN的相关属性,首先需要指定ResourceManager守护进程的主机和监听的端口,对于伪分布式模型来讲,其主机为localhost,
默认的端口为8032;其次需要指定ResourceManager使用的scheduler,以及NodeManager的辅助服务。一个简要的配置示例如下所示:
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>0.0.0.0:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>0.0.0.0:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>0.0.0.0:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>0.0.0.0:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>0.0.0.0:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
</configuration>6.格式化HDFS
[root@wj hadoop]# cd /bdapps/hadoop-2.6.2/etc/hadoop
[root@wj hadoop]# hdfs namenode -format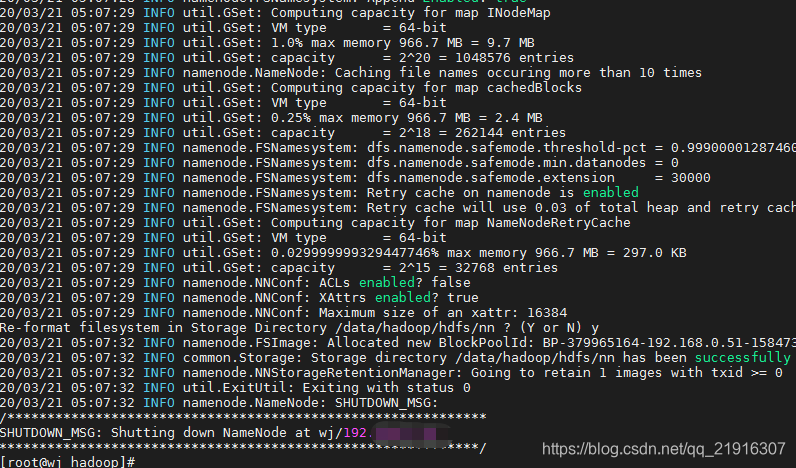
7.启动Hadoop
HDFS格式化完成之后就可以启动 去/bdapps/hadoop/etc/hadoop目录下启动Hadoop的5大守护进程了。
7.1.启动HDFS集群
HDFS有3个守护进程:namenode、datanode和secondarynamenode,他们都表示通过hadoop-daemon.sh脚本启动或停止。以hadoop用户执行相关命令;
[root@wj hadoop]# hadoop-daemon.sh start namenode
[root@wj hadoop]# hadoop-daemon.sh start secondarynamenode
[root@wj hadoop]# hadoop-daemon.sh start datanode
#jps命令:专门用于查看当前运行的java程序的
[root@wj hadoop]# jps
61392 NameNode
61602 Jps
61480 SecondaryNameNode
61532 DataNodeHDFS集群web访问接口:
http://主机ip:50070/dfshealth.html#tab-overview7.2启动yarn集群
切换成yarn用户:YARN有2个守护进程:resourcemanager和nodemanager,它们通过yarn-daemon.sh脚本启动或者停止。以hadoop用户执行相关命令即可。
[root@wj hadoop]# yarn-daemon.sh start resourcemanager
[root@wj hadoop]# yarn-daemon.sh start nodemanager
[root@wj hadoop]# jps
61803 ResourceManager
62043 NodeManager
62142 Jpsyarn集群web访问接口:
http://主机ip:8088/cluster8.测试
使用Hadoop自带的 hadoop-mapreduce-examples-2.6.2.jar,执行MapReduce任务是否可以正常执行,如果可以就意味着安装成功了。
新建文件:
[root@wj hadoop]# hdfs dfs -mkdir -p /test/a.txt
[root@wj mapreduce]# cd /bdapps/hadoop-2.6.2/share/hadoop/mapreduce
[root@wj mapreduce]# yarn jar hadoop-mapreduce-examples-2.6.2.jar wordcount /test/a.txt /test/a.out
[root@wj mapreduce]# hdfs dfs -ls /test/a.out
Found 2 items
-rw-r--r-- 1 hdfs supergroup 0 2019-03-01 14:09 /test/a.out/_SUCCESS
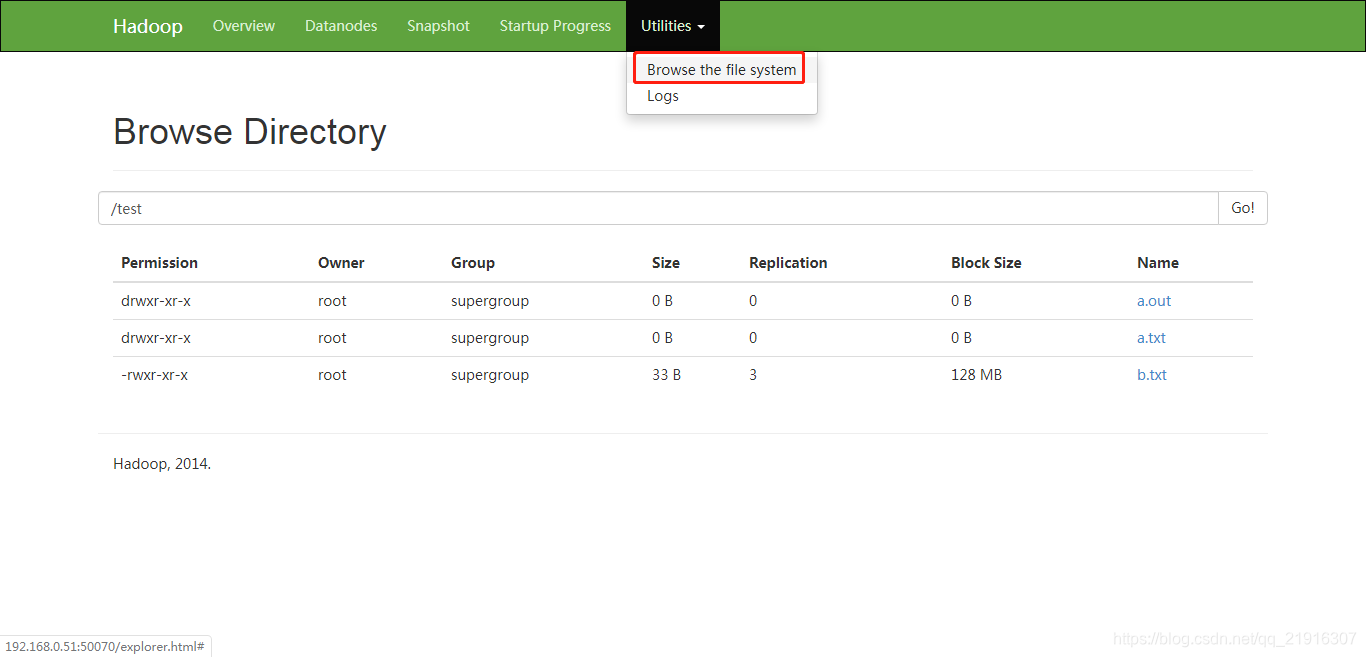
-rw-r--r-- 1 hdfs supergroup 54 2019-03-01 14:09 /test/a.out/part-r-00000可访问http://主机ip:50070/dfshealth.html#tab-overview,可以看到/tetst/路径下多出了a.out和a.txt文件,即文件上传成功
9.Python3调用Hadoop的API
安装pyhdfs
pip install pyhdfs -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
py文件如下:
import pyhdfs
fs = pyhdfs.HdfsClient(hosts='自己hadoop主机所在的ip,50070',user_name='root') #user_name就linux用户,我这里是root
fs.get_home_directory()#返回这个用户的根目录
fs.get_active_namenode()#返回可用的namenode节点
path='/test/'
file='a.txt'
file_name=path+file
#在上传文件之前,请修改本地 host文件 192.168.226.142 localhost C:\WINDOWS\system32\drivers\etc\host
print('路径已经存在') if fs.exists(path) else fs.mkdirs(path)
print('文件已存在') if fs.exists(path+file) else fs.copy_from_local('c.txt',path+file,) #上传本地文件到HDFS集群
fs.copy_to_local(path+file, 'zhanggen.txt')# 从HDFS集群上copy 文件到本地
fs.listdir(path) #以列表形式['a.out', 'a.txt'],返回指定目录下的所有文件
response=fs.open(path+file) #查看文件内容
print(response.read())
fs.append(file_name,'Thanks myself for fighting ',) #在HDFS集群的文件里面添加内容
response=fs.open(file_name) #查看文件内容
print(response.read())
print(fs.get_file_checksum(file_name)) #查看文件大小
print(fs.list_status(path))#查看单个路径的状态
print(fs.list_status(file_name))#查看单个文件状态注意:如果fs.append(file_name,'Thanks myself for fighting ',)这一句报错,参考https://blog.youkuaiyun.com/qq_39132578/article/details/79210033 中的第5点


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









