







 本文详细介绍了如何在生产环境中优化Docker镜像的制作过程,包括选择合适的基础镜像、检查镜像兼容性、记录缺失包、编写Dockerfile以及遵循最佳实践。通过这些步骤,可以有效减小镜像体积,提高部署效率。同时,文中列举了生产镜像制作的推荐操作,如使用明确Tag的FROM镜像、减少镜像层数、避免直接设置默认密码等,以增强镜像的安全性和可维护性。
本文详细介绍了如何在生产环境中优化Docker镜像的制作过程,包括选择合适的基础镜像、检查镜像兼容性、记录缺失包、编写Dockerfile以及遵循最佳实践。通过这些步骤,可以有效减小镜像体积,提高部署效率。同时,文中列举了生产镜像制作的推荐操作,如使用明确Tag的FROM镜像、减少镜像层数、避免直接设置默认密码等,以增强镜像的安全性和可维护性。
困境:平台上有几十个服务组件,每个个组件都是依托docker环境运行的,对外部署时,需要打包所有镜像实行部署,由于镜像多且镜像大,对部署来说拷贝转移数据的难度增加,为了降低部署的成本加快部署速度,我们决定对生产环境下的镜像进行重新制作,以达到镜像体积尽可能小的目标。以下会列出一个项目生产镜像制作的步骤以及docker镜像制作的一些推荐的操作。
1.生产镜像的制作
1.1镜像制作的步骤概览
1. 去官网找runtime镜像(runtime镜像只包含必须的包比devel镜像体积小)
https://hub.docker.com/search?q=
3. 进容器测试需要打包项目运行情况,记录镜像缺少的包环境
4. 编写Dockerfile在runtime镜像的基础上构建镜像
1.2 生产镜像制作实例
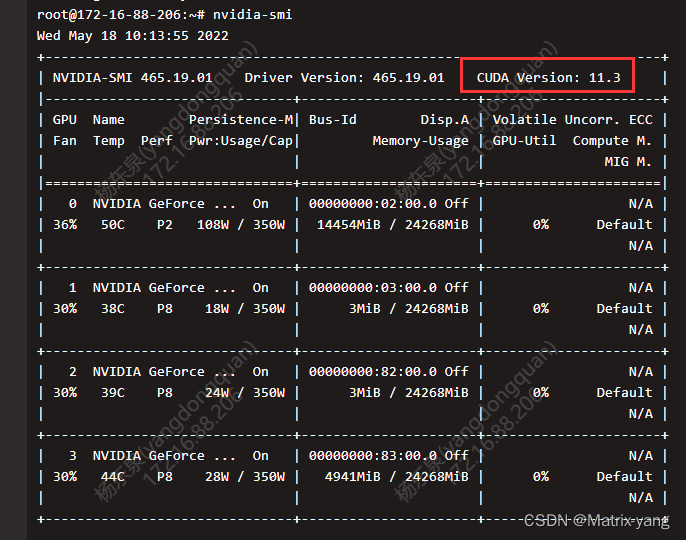
1. 查看当前生产镜像服务器的目标环境(主要目标环境的CUDA版本)
nvidia-smi
2. 去dockerhub官网找项目依赖的pytorch的官方镜像
搜索pytorch找到官方项目(一般是star最多的名字最相似的),点击tag页面
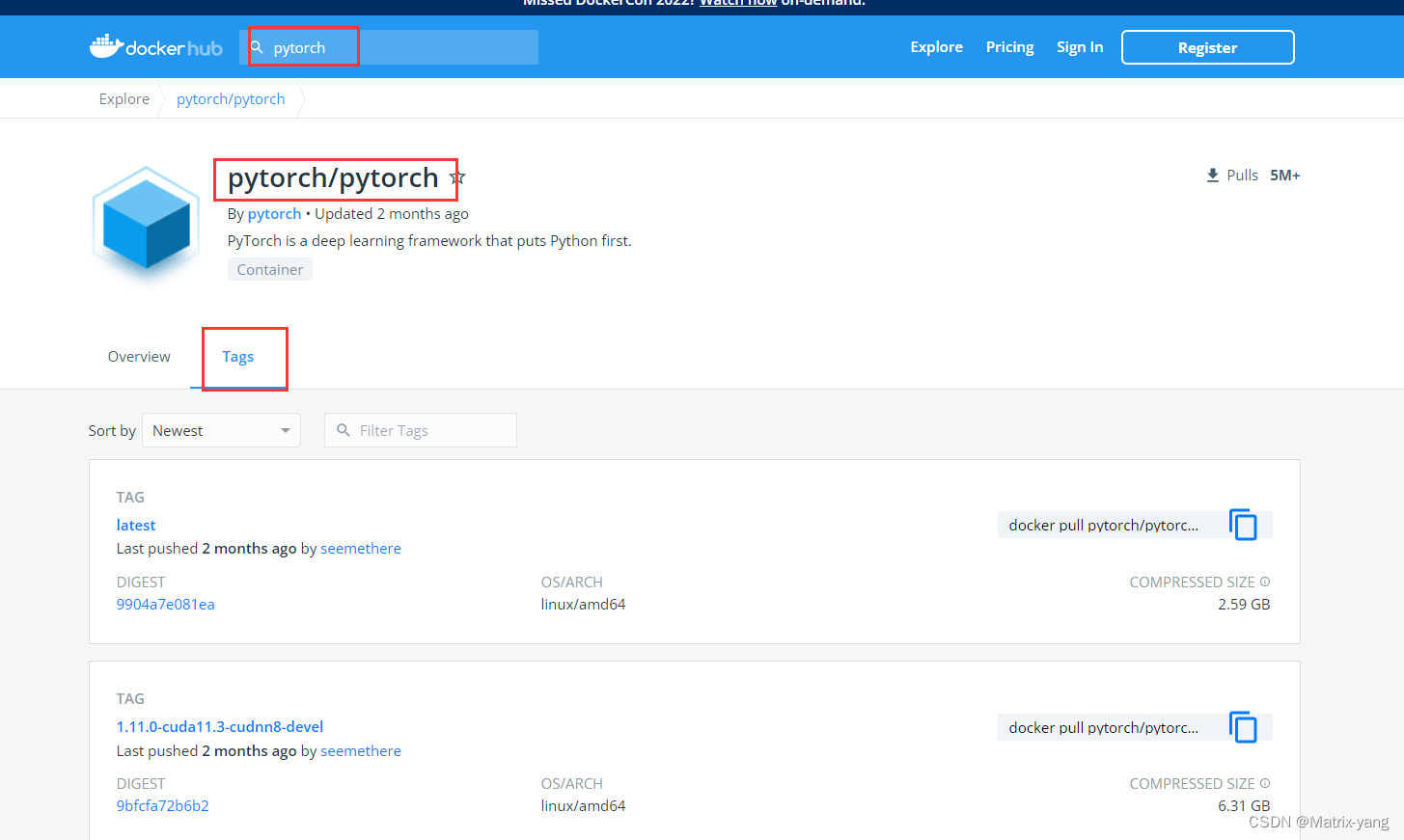
在资产项目中我们使用的是

细心的小伙伴们可能以及注意到该镜像的cuda是11.0,而目标服务器的版本是11.3
这里涉及到一个兼容规则,一般有有向下兼容的特点,目标服务器的cuda版本是11.3它理论上支持任何版本小于11.3的镜像,但是这类基础软件有时候也存在大版本不兼容的情况,因此我们需要尽可能的选择大版本相同,小版本小于等于目标服务器的镜像。同理pytoch的版本也是一样比如开发时使用的是pytoch1.6。在选择生产镜像时pytroch版本时高于1.6即可,pytorch的向前兼容性还是比较好的。
在目标服务器上下载该镜像(点击右边复制按钮,可复制下载)
docker pull pytorch/pytorch:1.7.1-cuda11.0-cudnn8-runtime
在目标服务器上查看下载镜像
docker image ls | grep cuda11.0

3. 缺失包安装
- 创建并进入容器(–rm 会在退出容器时删除该容器)
docker run --runtime=nvidia -it --rm --name ydq_image_test -v /data:/data pytorch/pytorch:1.7.1-cuda11.0-cudnn8-runtime /bin/bash
-
查看容器内包含的包,如果你知道项目使用到得包直接使用pip intall 安装包即可,如果不知道继续往下看
-
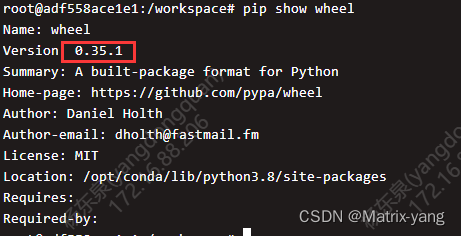
在容器内运行你的项目,查看项目报错的得知所缺少的包,并且在开发环境中查看该包的版本
#这里查看是 wheel包的版本
pip show wheel
- 将缺少的包和版本,新建requirements.txt并记录
PyMuPDF==1.18.14
starlette==0.14.2
matplotlib==3.3.3
uvicorn==0.14.0
scipy==1.5.2
fastapi==0.66.0
pdfminer3k==1.3.4
cos-python-sdk-v5==1.9.14
joblib==0.17.0
xlrd==1.2.0
pandas==1.1.4
opencv-python==4.4.0.46
ConcurrentLogHandler==0.9.1
4.Dcokerfile编写
如果你对Dockerfile编写的一些命令不熟悉可以参考
Dockerfile的编写和命令
切换目录到requirements.txt所在目录,新建Dockerfile
#以刚刚下载的镜像为基础镜像
FROM pytorch/pytorch:1.7.1-cuda11.0-cudnn8-runtime
ENV LANG C.UTF-8
ENV DEBIAN_FRONTEND noninteractive
LABEL maintainer="new_ai@linklogis.com"
# 更新时区
ENV TZ=Asia/Shanghai
#将依赖包列表拷贝到镜像
ADD requirements.txt /workspace
WORKDIR /workspace
#安装依赖包
RUN /opt/conda/bin/pip install --no-cache-dir -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ \
&& apt update \
&& apt install -y tzdata \
&& ln -fs /usr/share/zoneinfo/${TZ} /etc/localtime \
&& echo ${TZ} > /etc/timezone \
&& apt install -y libglib2.0-dev \
&& apt install -y libgl1-mesa-glx \
&& apt autoremove
5.以编写好的Dockerfile构建新镜像
构建镜像
#ydq_test:v1修改成你需要的镜像名称:版本
docker build -t ydq_test:v2 .
至此镜像制作完成,你可以进入新制作的镜像中验证代码运行情况
docker run --runtime=nvidia -it --rm --name ydq_image_test -v /data:/data ydq_test:v2 /bin/bash
2.生产镜像的制作的推荐操作
-
(1) 关键字使用大写
-
(2) FROM镜像,指定明确的Tag,不允许使用latest
-
(3) 将上下文依赖命令放在同一个RUN命令下,减少镜像层数
-
(4) 优化Dockerfile命令顺序,将不变的放在前面
-
(5) 使用WORKDIR指定工作目录,避免绝对路径扩散
-
(6) 优先使用COPY,ADD支持远程下载,会存在安全隐患
-
(7) 避免直接在镜像中设置默认密码
-
(8) 镜像中不要安装sshd
-
(9) 对于需要访问的目录文件执行相关命令修改权限
-
(10) 使用Label命令为镜像设置元数据
-
(11) 清理临时文件,如yum install后需要执行yum clean all -y
-
(12) 禁止使用ENV和ARG传递敏感信息,因为这些信息会被通过docker image
history看到 -
(13) 优先使用CMD/ENTRYPOINT指令的EXEC格式设置镜像的默认执行程序,
使得应用进程PID为1,这样对容器内应用管理相对简单,1号进程退出后整个容
器也就退出了。 -
(14) 禁用ROOT用户运行应用,为应用创建用户与用户组,应用运行用户的
Shell设置为/sbin/nologin -
(15) 应用程序部署WORKDIR为/opt/应用程序名称,子目录如下:
应用程序名称
|----bin
|----程序二进制或者启动脚本之类
|----conf
|----log
|----业务访问日志access.log
|----业务程序运行日志 -
(16) 对于有持久性需求的应用程序,需要添加Volumes声明
-
(17) 对于Web类应用程序,统一Expose端口使用80
-
(18) 运行程序的基础镜像采用ubuntu 20.04版本
-
(19) 程序的启动命令需要加入到Entrypoint指令中,采用Exec格式
-
(20) 镜像选择release版,通过dockerfile生成镜像,不要使用docker commit 生成(没有docker分层的记录)
-
(21) 清除安装包缓存
-
(21) 多个RUN可以合并到一层

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









