







docker问题汇总
文章目录
我不会设置仅粉丝可见,不需要你关注我,仅仅希望我的踩坑经验能帮到你。如果有帮助,麻烦点个 👍 吧,这会让我创作动力+1 😁
docker问题汇总贴,不断学习不断更新。当前更新时间: 20250430

银河麒麟不删podman无法运行docker
-
报错内容:
docker: Error response from daemon: failed to create task for container: failed to create shim task: OCI runtime create failed: container_linux.go:318: starting container process caused "permission denied": unknown. -
最终解决方案:删掉podman就ok了,
yum remove podman -
原因分析:
-
检查镜像架构是否正确:查看镜像架构:
docker inspect hello-world,兄弟,amd64架构你才能跑啊,别搞成arm了
-
这里要安装 docker-ce 19.03 版本,因为我在使用最新版 20.10 启动容器时出现了未知的权限问题,而麒麟服务器操作系统资料相对较少,我未能找到相应的解决方案,只好退而求其次,换到上一个稳定版本。
-
找了N多了地方 最后发现是这个podman惹的祸
yum remove podman
删掉后docker start *
世界清净了
-
docker镜像盘迁移
参考链接1:https://blog.youkuaiyun.com/qq_15607445/article/details/142753636
参考链接2:https://www.cnblogs.com/FatSheepKiller/p/17884682.html
-
先把应用停一停:
docker ps | awk '{print $1}' |xargs docker stop -
停止docker先啦:
systemctl stop docker -
复制原来docker的内容到新建的文件夹里:
cp -pr /var/lib/docker/ /data/[!warning] 路径警告
路径这里需要注意的是你把
/var/lib/docker/*复制到/data/docker/*中,直接跑代码就行了。不需要额外的mkdir /data/docker😅 可能是复制的时候我没加 * ?
-
docker原来的的文件改名:
mv /var/lib/docker /var/lib/docker2 -
配置
/etc/docker/daemon.json,再重启docker即可syatemctl start docker{ "data-root": "/data/docker/" }[!tag] 方法2,建立软连接(懒得试了)
ln -s /data/docker/ /var/lib/docker
docker怎么用gpu
在用vllm的时候,发现使用 docker run --runtime nvidia --gpus all,增加了一些运行的命令,其中 --gpus all 就是用宿主机的gpu驱动,不过要想起作用还得装 NVIDIA Container Toolkit,在线安装很简单,我必然要搞离线安装的~
先看清楚依赖,四个rpm,问题不大~
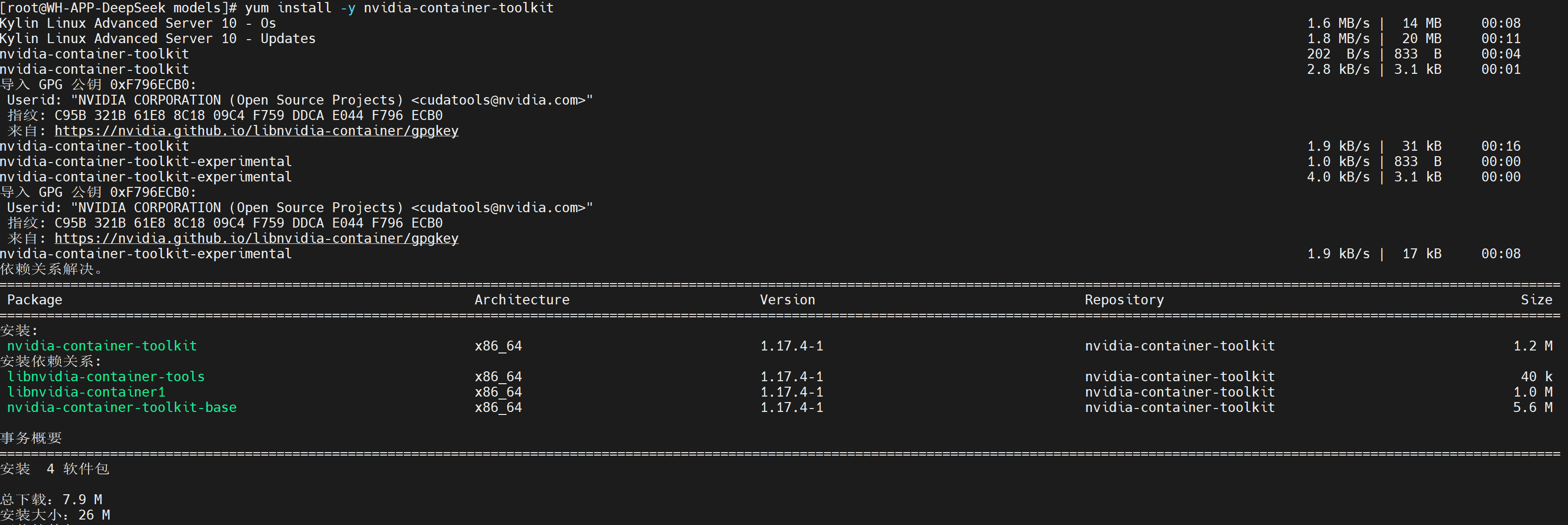
这四个可以从github上找到:https://github.com/NVIDIA/libnvidia-container/tree/gh-pages/stable/rpm/x86_64
[!warning] 问题来了,怎么从github中下载单个文件
从
raw.githubusercontent.com中下载:比如wget https://raw.githubusercontent.com/NVIDIA/libnvidia-container/refs/heads/gh-pages/stable/rpm/x86_64/libnvidia-container1-1.17.4-1.x86_64.rpm包括下面4个,改一下url就行:
nvidia-container-toolkit-base-1.17.4-1.x86_64.rpmnvidia-container-toolkit-1.17.4-1.x86_64.rpmlibnvidia-container1-1.17.4-1.x86_64.rpmlibnvidia-container-tools-1.17.4-1.x86_64.rpm
下载完了之后传到没网的服务器,再安装:rpm -ivh *
unknown or invalid runtime name: nvidia
参考链接:https://developer.baidu.com/article/details/2805250
配置 /etc/docker/daemon.json,既然没有这个runtime name,那我自己建一个
{
...
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
...
}
然后重启 systemctl restart docker 完事儿~
Docker进阶命令
-
清除没有up的容器:
docker container prune -
以follow的形式查看日志:
docker logs -f xxx -
更新容器设置:
-
先stop容器:
docker stop xxx -
再update,以restart举例:
docker update --restart=no xxx[!info] restart的区别
--restart=always:- 容器将始终尝试重启,无论它是如何停止的。
- 如果容器崩溃,它会自动重启。
- 如果Docker守护进程重启,容器也会自动启动。
- 即使容器被手动停止(如使用
docker stop命令),当Docker守护进程重启时,它也会重新启动。
--restart=unless-stopped:- 容器会在崩溃时自动重启。
- 如果Docker守护进程重启,容器也会自动启动。
- 关键区别:如果容器被手动停止(如使用
docker stop命令),它不会在Docker守护进程重启时自动启动。
-
-
获取某个镜像的tags有哪些,用sglang举例:
curl -s https://registry.hub.docker.com/v2/repositories/lmsysorg/sglang/tags/
常见容器使用
银河麒麟
我用的是V10SP3版本,启动:
docker run -it --name huazhi --privileged=true --network host -v E:\1-Work\4-Project\1-万华智享平台\HuaZhi-Backend:/data/HuaZhi ubuntu:18.04
Ubuntu
docker run -it --name ubuntu-test --runtime nvidia --gpus all --privileged=true --network host -v E:/11-container/ubuntu-test:/data/ ubuntu:22.04
MySQL
可以直接启动容器:
docker run -p 3306:3306 --name mysql-test --restart=always --privileged=true -v E:/11-container/mysql-test/log:/var/log/mysql -v E:/11-container/mysql-test/data:/var/lib/mysql -v E:/11-container/mysql-test/conf:/etc/mysql/conf.d -e MYSQL_ROOT_PASSWORD=Qiangmima@666 -d mysql:8.0.29
如果想用配置的话,可以把下面的配置文件复制到配置的路径,然后重启容器:
[client]
default-character-set=utf8mb4
[mysql]
default-character-set=utf8mb4
[mysqld]
lower_case_table_names=1
init_connect='SET collation_connection = utf8mb4_unicode_ci'
init_connect='SET NAMES utf8mb4'
character-set-server=utf8mb4
collation-server=utf8mb4_unicode_ci
skip-character-set-client-handshake
skip-name-resolve
Redis
redis其实也是相似的,比如编辑配置文件
mkdir -p E:/11-container/redis-test/conf && vim E:/11-container/redis-test/conf/redis.conf
# 配置示例
appendonly yes
port 6379
bind 0.0.0.0
启动容器,跟mysql不同的时候,redis是有启动命令的,在最后
docker run -d -p 6379:6379 --restart=always --privileged=true -v E:/11-container/redis-test/conf/redis.conf:/etc/redis/redis.conf -v E:/11-container/redis-test/data:/data --name redis-test redis:7.4 redis-server /etc/redis/redis.conf
💡 其实docker在进行-v路径挂载中,路径挂路径,文件挂文件,但是如果宿主机文件的路径写错了/不存在,那么文件就会变成路径的样子,要仔细检查哦~
Mongo
这里给mongo挂载一下本地的盘好了
docker run -d -p 27017:27017 --restart=always --privileged=true --name mongo-test -v E:/11-container/mongo-test/data:/data/db -v E:/11-container/mongo-test/backup:/data/backup -e MONGO_INITDB_ROOT_USERNAME=root -e MONGO_INITDB_ROOT_PASSWORD=Qiangmima@666 mongo:6.0.20
- 如果还想限制资源:
--memory 2g --cpu 1.0
备份 mongo的数据备份:
-
进入容器:
docker exec -it mongo-test bash -
使用
mongodump进行备份,注意这里的备份记得提前挂载哦,不然后面就得docker cp复制出来了mongodump --username root --password Qiangmima@666 --out /data/backup
Minio
直接启动!直接启动!
docker run -d -p 9000:9000 -p 9001:9001 --restart=always --privileged=true --name minio-test -v E:/11-container/minio-test/data:/data -v E:/11-container/minio-test/config:/root/.minio -e MINIO_ACCESS_KEY=root -e MINIO_SECRET_KEY=Qiangmima@666 quay.io/minio/minio:RELEASE.2023-12-20T01-00-02Z server /data --console-address ":9001"
要注意版本问题,之前我跑2019的版本,反正就各种出错,上面的可以跑通。
--console-address:这里一定要制定管理端口,默认的可不是9001
[!tag] SGLang和vLLM有哪些区别?
参考:https://www.zhihu.com/question/666943660/answer/77360338901
- vLLM(Virtual Large Language Model)的核心技术是PagedAttention。
- PagedAttention是一种新颖的注意力算法,其设计灵感来源于操作系统中的虚拟内存分页管理技术。通过将LLM(大型语言模型)服务状态分页管理,PagedAttention算法能够高效地处理大规模数据,从而实现高吞吐量的服务性能。
- 具体来说,PagedAttention算法将注意力机制中的缓存(如KV缓存)划分为多个小块(pages),根据用户输入token的数量动态分配这些小块的空间。这种非连续的内存管理方式避免了显存的浪费,提高了内存的利用率。同时,PagedAttention算法能够高效地管理注意力键和值,减少了重复计算,从而显著提高了推理速度。
- 相较于传统的注意力算法,PagedAttention算法在保持模型精度的同时,大幅提升了推理性能。实验表明,vLLM凭借PagedAttention算法,其吞吐量比HuggingFace Transformers高14-24倍,为自然语言处理领域的高效推理提供了新的解决方案。
SGLang
怎么大厂都在说 SGLang 比vLLM更好啊,奶奶滴,做了fp8优化吗?
ds-32b 蒸馏模型
docker run -d --privileged=true --runtime nvidia --gpus all --shm-size 32g --name sglang-test -v /data/models:/data/models -p 8000:8000 10.4.32.48:5000/lmsysorg/sglang:v0.4.3.post2-cu124 python3 -m sglang.launch_server --model /data/models/DeepSeek-R1-Distill-Qwen-32B --host 0.0.0.0 --port 8000 --allow-auto-truncate --enable-dp-attention
qwen3-30b moe模型
docker run -d --privileged=true --runtime nvidia --gpus all --shm-size 32g --name qwen3 -v /data/models:/data/models -p 8000:8000 10.4.32.48:5000/lmsysorg/sglang:v0.4.6.post1-cu124 python3 -m sglang.launch_server --model /data/models/Qwen3-30B-A3B --host 0.0.0.0 --port 8000 --allow-auto-truncate
-
--shm-size:用来设置容器内一个特殊区域的大小,这个区域叫做“共享内存”(Shared Memory)。你可以把它想象成一个超级快的临时存储空间,它位于内存中,比普通硬盘快得多。 -
--enable-dp-attention:Data Parallelism Attention optimization can be enabled for DeepSeek Series Models. -
--enable-torch-compile:启用 Torch Compile 优化,虽然会增加服务启动时间,但能显著提升推理性能。 -
--allow-auto-truncate: 自动截断超过最大输入长度的请求。 -
--watchdog-timeout: 调整看门狗线程的超时时间,在批处理生成花费过长时间时终止服务器。 -
--reasoning-parser:解析思考内容,响应消息除了包含content字段外,还会有一个名为reasoning_content的字段,其中包含模型生成的思考内容。请注意,此功能与 OpenAI API 规范不一致。
enable_thinking=False可能与思考内容解析不兼容。如果需要向 API 传递enable_thinking=False,请考虑禁用该功能。
⚠️ 如果跑起来报错啊啥的,服务启不起来,有可能是sglang的bug。比如:v0.4.3-cu124,就各种报错,切换了v0.4.3.post2-cu124就没事了
vLLM
可恶啊vLLM不能在windows上跑,下好模型,做好路径映射,然后:
比如qwen
docker run -d --privileged=true --runtime nvidia --gpus all --name vllm-test -v /data/vllm/huggingface:/root/.cache/huggingface -v /data/models:/data/models -p 8000:8000 --ipc=host vllm/vllm-openai:latest --model /data/models/qwen-2.5-1.5b
比如deepseek,注意,这里我80g A100也无法完美运行 --max-model-len 32768,因此修改为 --max-model-len 10000
[!warning] deepseek推理要用新版vllm
除此之外还要用推理模式:
--enable-reasoning --reasoning-parser deepseek_r1
docker run -d --runtime nvidia --gpus all --name vllm-test --ipc=host -v /data/models:/data/models -p 8000:8000 10.4.32.48:5000/vllm/vllm-openai:latest --model /data/models/DeepSeek-R1-Distill-Qwen-32B --max-model-len 10000 --gpu-memory-utilization 0.9
其中,参考vLLM相关配置参数,docker相关参数解释如下:
- –ipc=host: 让容器与主机共享进程间通信(IPC)命名空间。这个选项能提高 GPU 任务的性能,尤其在使用诸如深度学习框架时。
- –runtime nvidia: 指定使用 NVIDIA 的运行时环境,以便在容器中启用 GPU 功能。这个需要主机上有 NVIDIA 的驱动和 Docker 的 NVIDIA 插件。
- –gpus all: 允许容器访问主机的所有 GPU。这对于需要使用多个 GPU 来加速计算的深度学习任务是必要的。
调用方法:
-
python
⚠️ 注意!model要填真实模型地址,其实就是-v映射的容器内的地址
from openai import OpenAI openai_api_key = "EMPTY" openai_api_base = "http://localhost:8000/v1" client = OpenAI( api_key=openai_api_key, base_url=openai_api_base, ) chat_response = client.chat.completions.create( model="/data/models/qwen-2.5-1.5b", messages=[ {"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."}, {"role": "user", "content": "Tell me something about large language models."}, ], temperature=0.7, top_p=0.8, max_tokens=512, extra_body={ "repetition_penalty": 1.05, }, )输出
Chat response: ChatCompletion(id='chatcmpl-1daa244c6ca14f5fa8baa9c0d8233f6b', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='Large Language Models (LLMs) are artificial intelligence systems that can generate human-like text based on the input provided to them. These models are designed to understand and respond to natural language queries, such as writing stories, generating poetry, answering questions, and more.\n\nOne of the key features of LLMs is their ability to learn from vast amounts of data. They are trained using massive datasets, which allows them to recognize patterns and relationships in language that humans might not be able to detect on their own. This makes them particularly useful for tasks that require a high level of understanding and interpretation of language, such as machine translation, sentiment analysis, and question-answering systems.\n\nThere are several types of LLMs, including transformer-based models like BERT, GPT, and T5, which have been successful in various applications due to their ability to handle long sequences of text and their capacity for fine-tuning specific tasks.\n\nHowever, LLMs also come with some challenges and limitations. One of the main concerns is bias, as these models can inherit biases present in the training data. Additionally, they can produce inappropriate or offensive responses if they are exposed to inappropriate or offensive inputs. Furthermore, the sheer size and complexity of these models can make them difficult to train and optimize, and they may struggle with certain types of language or complex tasks.\n\nDespite these challenges, large language models continue to advance rapidly, and they are being used in a wide range of applications, from chatbots and virtual assistants to scientific research and language translation. As they become more sophisticated, it will be important to continue developing techniques to address their limitations and ensure they are used responsibly and ethically.', refusal=None, role='assistant', audio=None, function_call=None, tool_calls=[]), stop_reason=None)], created=1736401336, model='/data/models/qwen-2.5-1.5b', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=337, prompt_tokens=37, total_tokens=374, completion_tokens_details=None, prompt_tokens_details=None), prompt_logprobs=None) -
curl
curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{ "model": "/data/models/qwen-2.5-1.5b", "messages": [ {"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."}, {"role": "user", "content": "Tell me something about large language models."} ], "temperature": 0.7, "top_p": 0.8, "repetition_penalty": 1.05, "max_tokens": 512 }'
[!tag] 在vllm后面加个ollama的备注不过分吧
部署参考官网:https://github.com/ollama/ollama/blob/main/docs/linux.md
量化bge reranker参考hf:https://huggingface.co/gpustack/bge-reranker-v2-m3-GGUF
注意:怎么导入hf上下的模型,先编写一个
Modelfile,里面FROM /data/models/bge-reranker-v2-m3-GGUF,后面的文件夹就是你的模型路径,然后用ollama导入,ollama create bge-reranker-v2-m3-GGUF -f Modelfile,🎉 然后你就能在ollama list中看到你导入的模型了~
Text Embedding Interface
参考链接:https://huggingface.co/docs/text-embeddings-inference/quick_tour
以embedding举例:
docker run -d --runtime nvidia --gpus all --name embedding-test -v /data/models:/data/models -p 8001:8001 --ipc=host text-embeddings-inference --model-id /data/models/bge-m3 --port 8001
调用:如果是dify,直接配置到端口就行
curl 127.0.0.1:8080/embed \
-X POST \
-d '{"inputs":"What is Deep Learning?"}' \
-H 'Content-Type: application/json'
以rerank举例:
docker run -d --runtime nvidia --gpus all --name rerank-test -v /data/models:/data/models -p 8002:8002 --ipc=host text-embeddings-inference --model-id /data/models/bge-reranker-v2-m3 --port 8002
调用:如果是dify,直接配置到端口就行,垃圾RAGFlow,TEI部署的rerank竟然不支持,ollama部署的也不支持,我真服了 😄
curl 127.0.0.1:8080/rerank \
-X POST \
-d '{"query":"What is Deep Learning?", "texts": ["Deep Learning is not...", "Deep learning is..."], "raw_scores": false}' \
-H 'Content-Type: application/json'
GitLab
参考链接:https://blog.youkuaiyun.com/weixin_42286658/article/details/144768578
docker run -d --name mygitlab --restart always --privileged=true -p 8180:80 -p 8122:22 -v /data/gitlab/etc:/etc/gitlab -v /data/gitlab/log:/var/log/gitlab -v /data/gitlab/opt:/var/opt/gitlab gitlab/gitlab-ce:17.8.0-ce.0
修改gitlab的配置
改 /data/gitlab/etc/gitlab.rb 这个文件,在宿主机改就行。一定要改哦,不然后面你push的时候就会很痛苦的。。。
[!warning] push的时候会报下面的错。。。
# git push --set-upstream origin main ssh: Could not resolve hostname 724d10cd38bf: Name or service not known fatal: Could not read from remote repository.
# 取消external_url注释,地址为宿主机地址,不需要设置端口,别忘了http这些,否则会报错
external_url 'http://你的IP'
# ssh主机ip
gitlab_rails['gitlab_ssh_host'] = '你的IP'
# ssh连接端口
gitlab_rails['gitlab_shell_ssh_port'] =8122
# 时区顺便也改一下吧
gitlab_rails['time_zone'] = 'Asia/Shanghai'
改好之后,生成配置文件:
# 宿主机输入:在容器中执行 gitlab-ctl reconfigure
docker exec -t mygitlab gitlab-ctl reconfigure
配置文件中,还要改个web server的端口,不然http的请求就不显示啦:/opt/gitlab/embedded/service/gitlab-rails/config/gitlab.yml,修改这个端口哦~
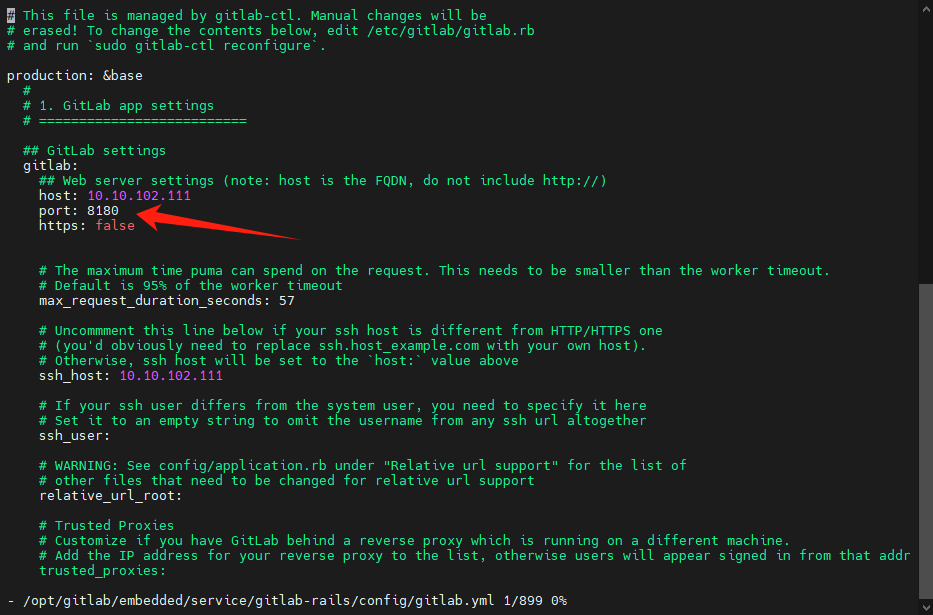
修改之后,这里的http才正常显示端口
最后,要重启服务哦~
# 宿主机输入:在容器中执行 gitlab-ctl restart
docker exec -t mygitlab gitlab-ctl restart
配置root用户
# 进入容器内部
docker exec -it mygitlab /bin/bash
# 进入控制台,要等一会儿哦~
gitlab-rails console -e production
# 查询id为1的用户,id为1的用户是超级管理员
user = User.where(id:1).first
# 修改密码,注意这里密码要求比较严格~
user.password='Qi@ngmima@666'
# 保存
user.save!
# 退出
exit
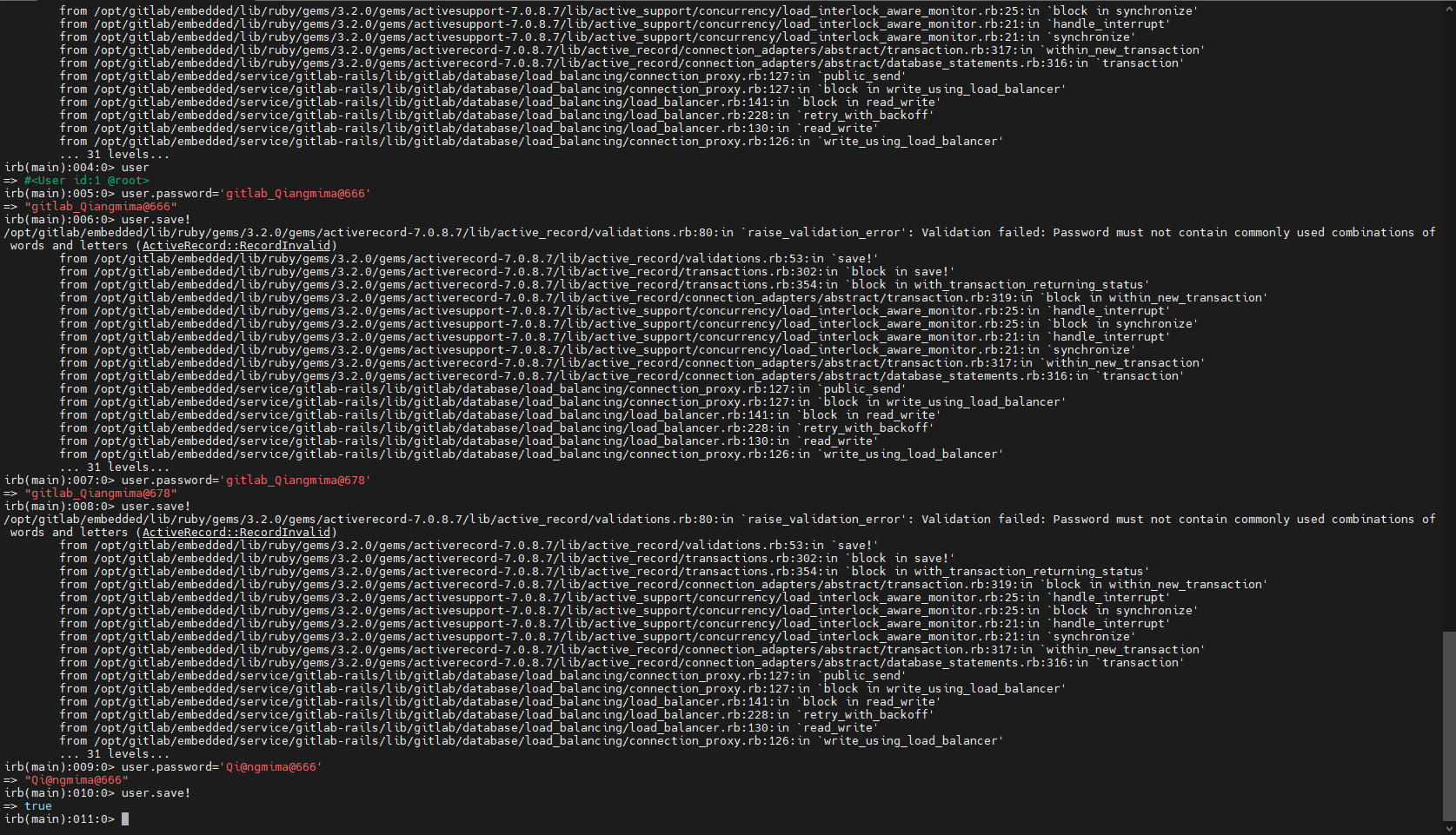
现在就可以去登录啦,pia的一下就登录进去了,很快哦
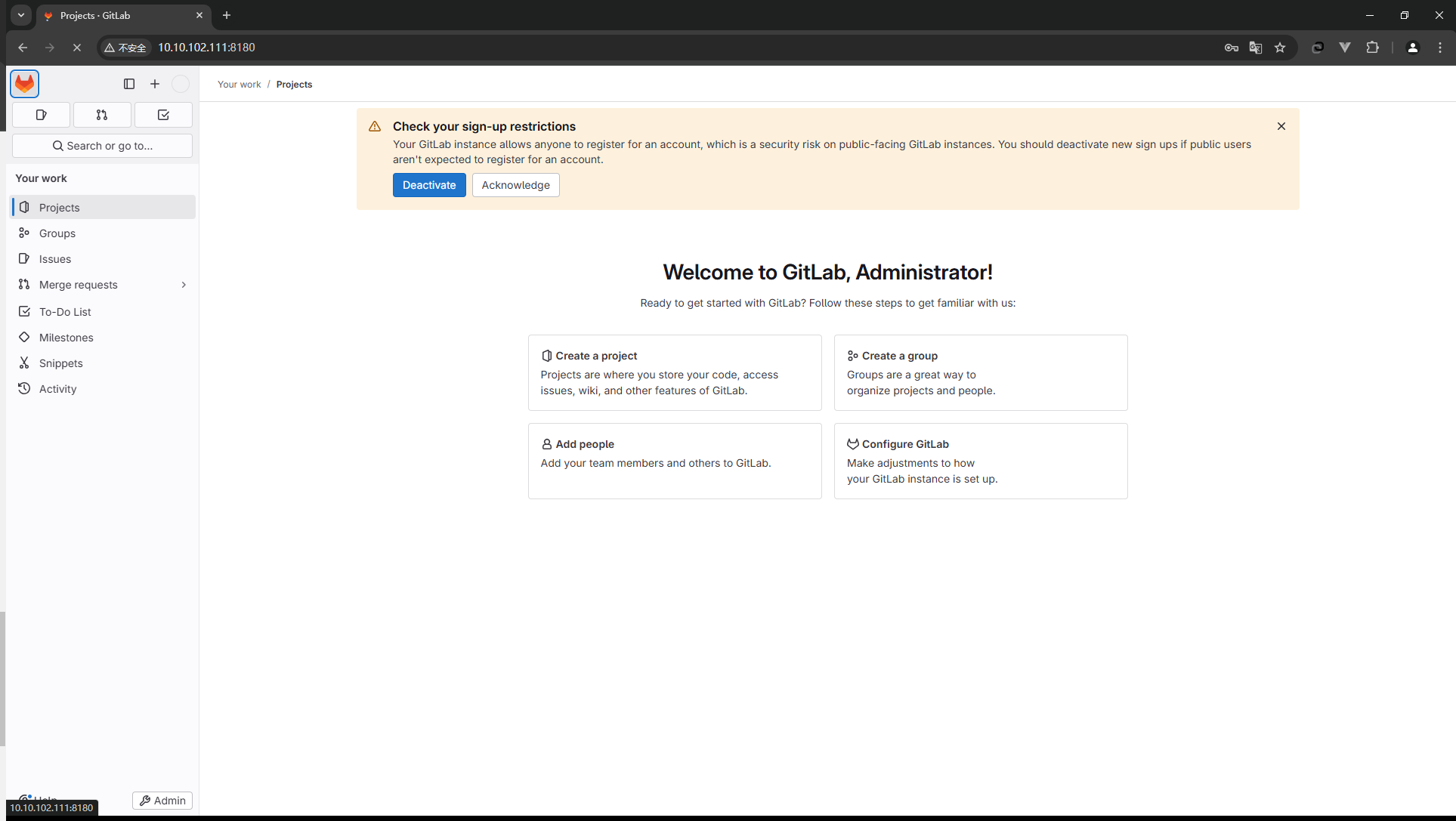
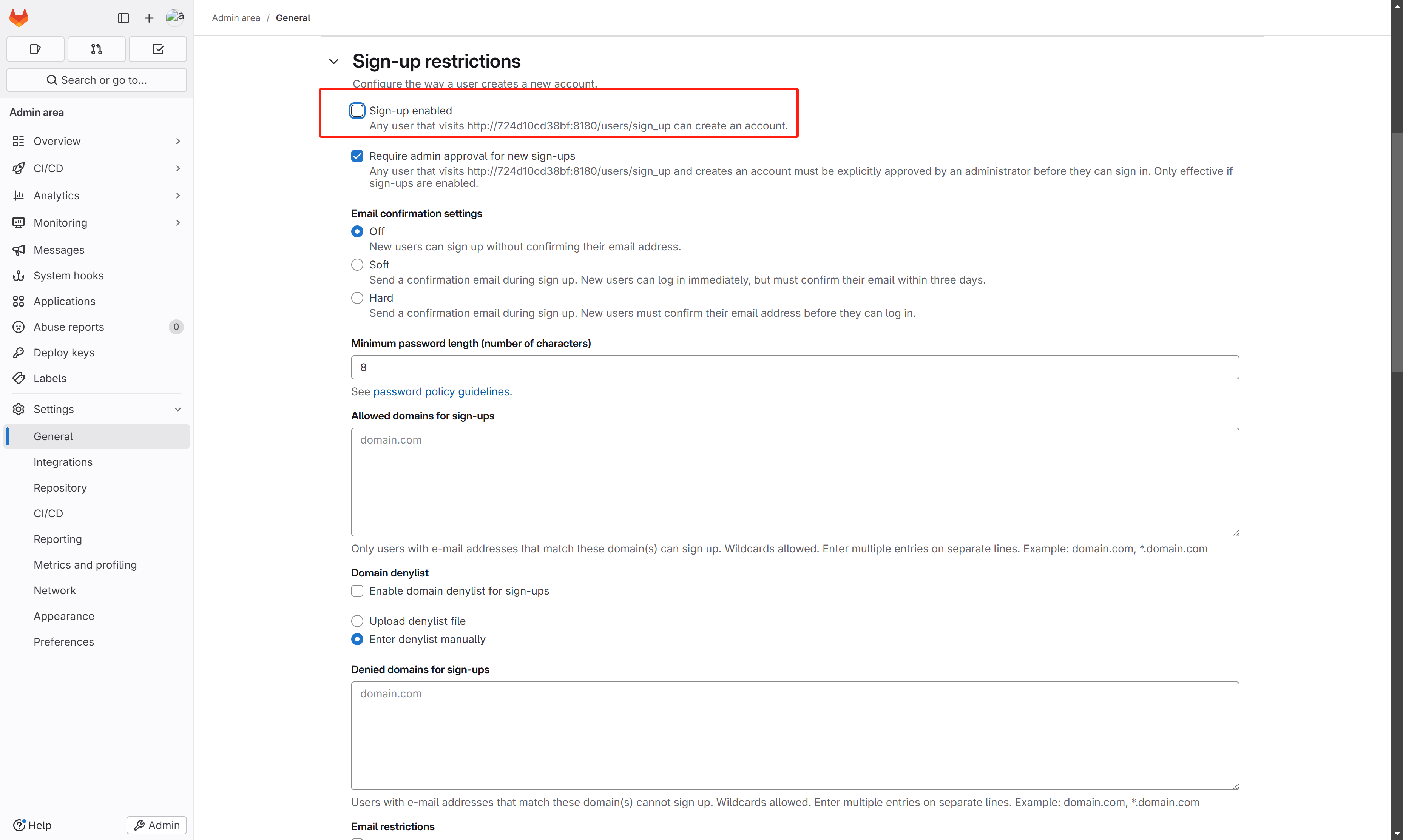
设置关闭自动创建账号功能:gitlab默认是开放注册账号功能的,在企业里面使用是不允许的,用户的账号是通过管理员创建出来的。😉 去掉勾选哦
使用说明
-
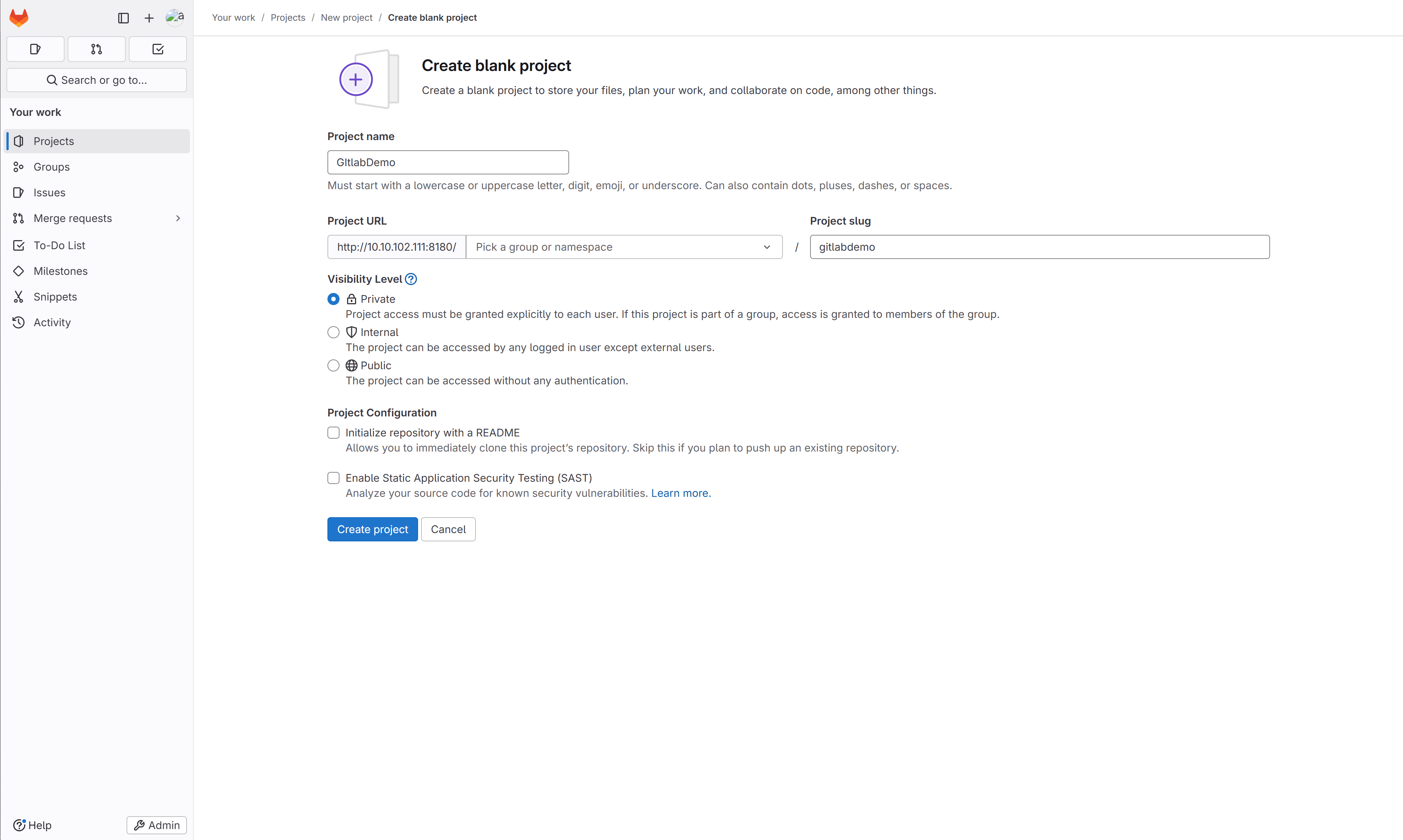
创建项目,一般选私有啦
-
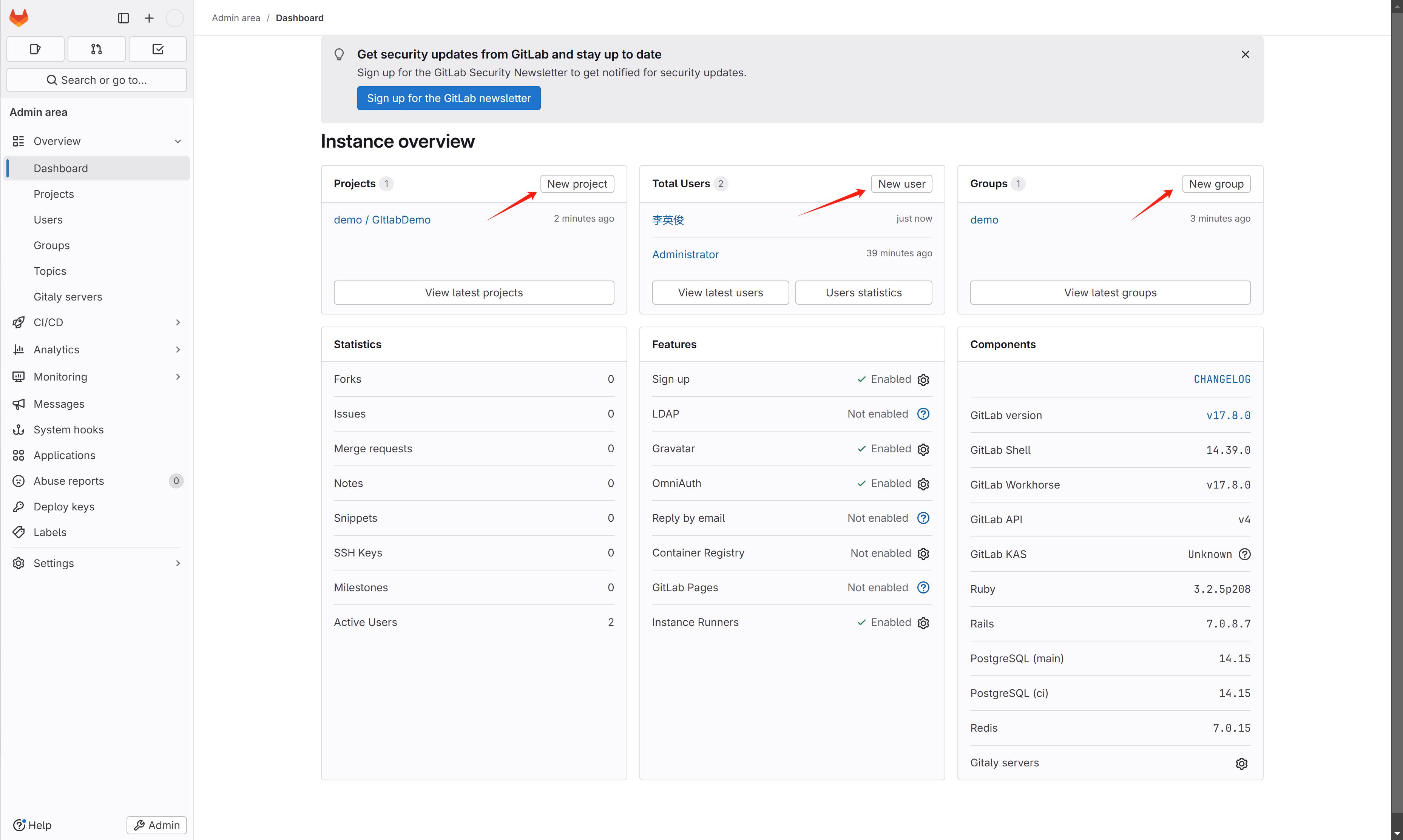
创建用户、组、项目
-
添加用户到项目中
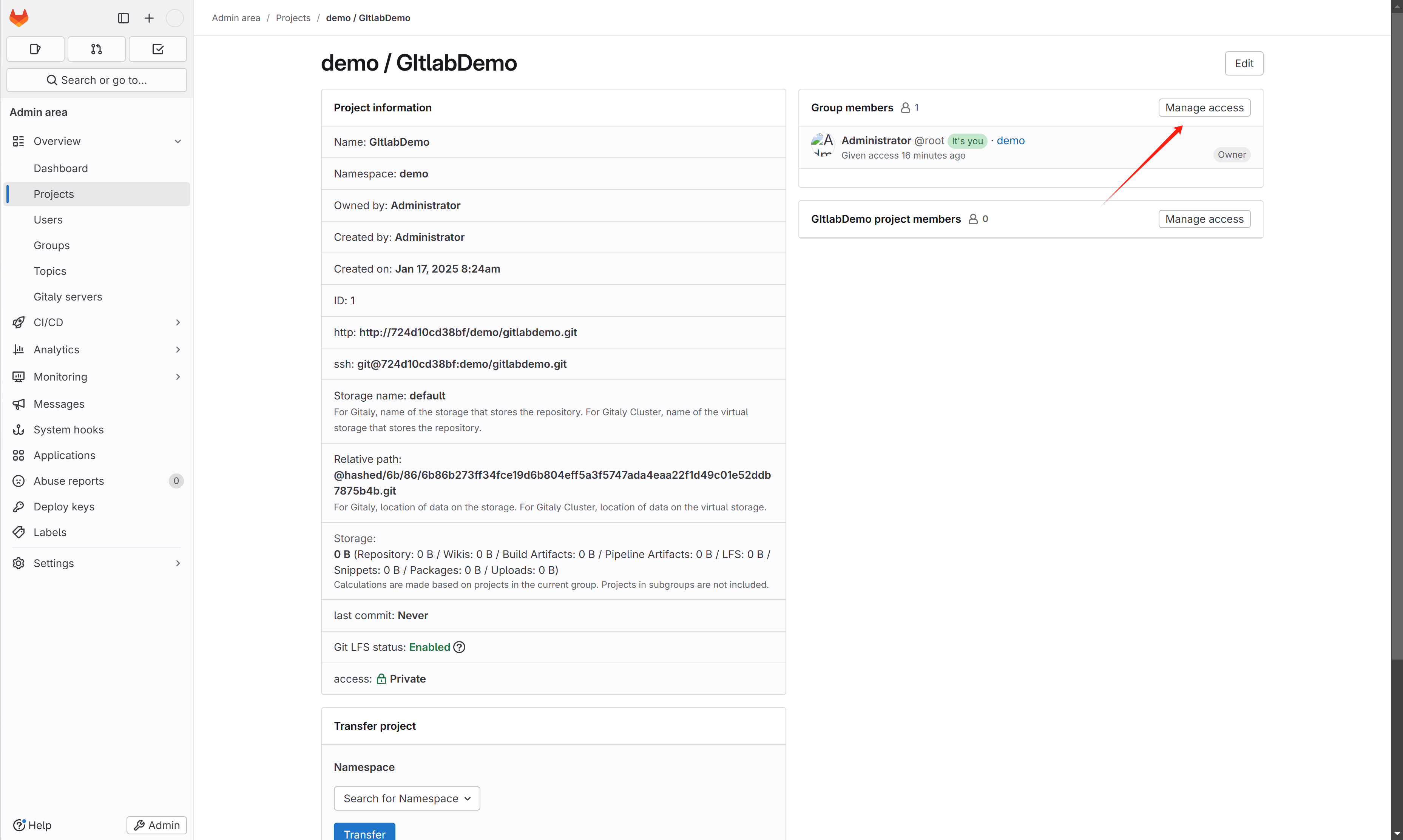
邀请用户,设置权限:

[!info] GitLab用户权限管理
GitLab用户在组中有五种权限:Guest、Reporter、Developer、Maintainer、Owner
1.Guest:可以创建issue、发表评论、不能读写版本库
2.Reporter:可以克隆代码,不能提交,QA、PM可以赋予这个权限
3.Developer:可以克隆代码、开发、提交、push、研发人员可以赋予这个权限
4.Maintainer:可以创建项目、添加 tag 、保护分支、添加项目成员、编辑项目、核心研发负责人可以赋予这个权限
5.Owner:可以设置项目的访问权限-Visibility Level、删除项目、迁移项目、管理组成员、项目经理,部门经理可以赋予这个权限
配置说明
-
第一步必然是配置ssh呀,你肯定会git吧,用过吧,不然跑来折腾gitlab干嘛,所以假定你懂啊,不懂自己百度去。以windows举例,在你的
C:\Users\用户名\.ssh文件夹中有你之前生成的公钥和私钥,把公钥填到 SSH Keys 中哦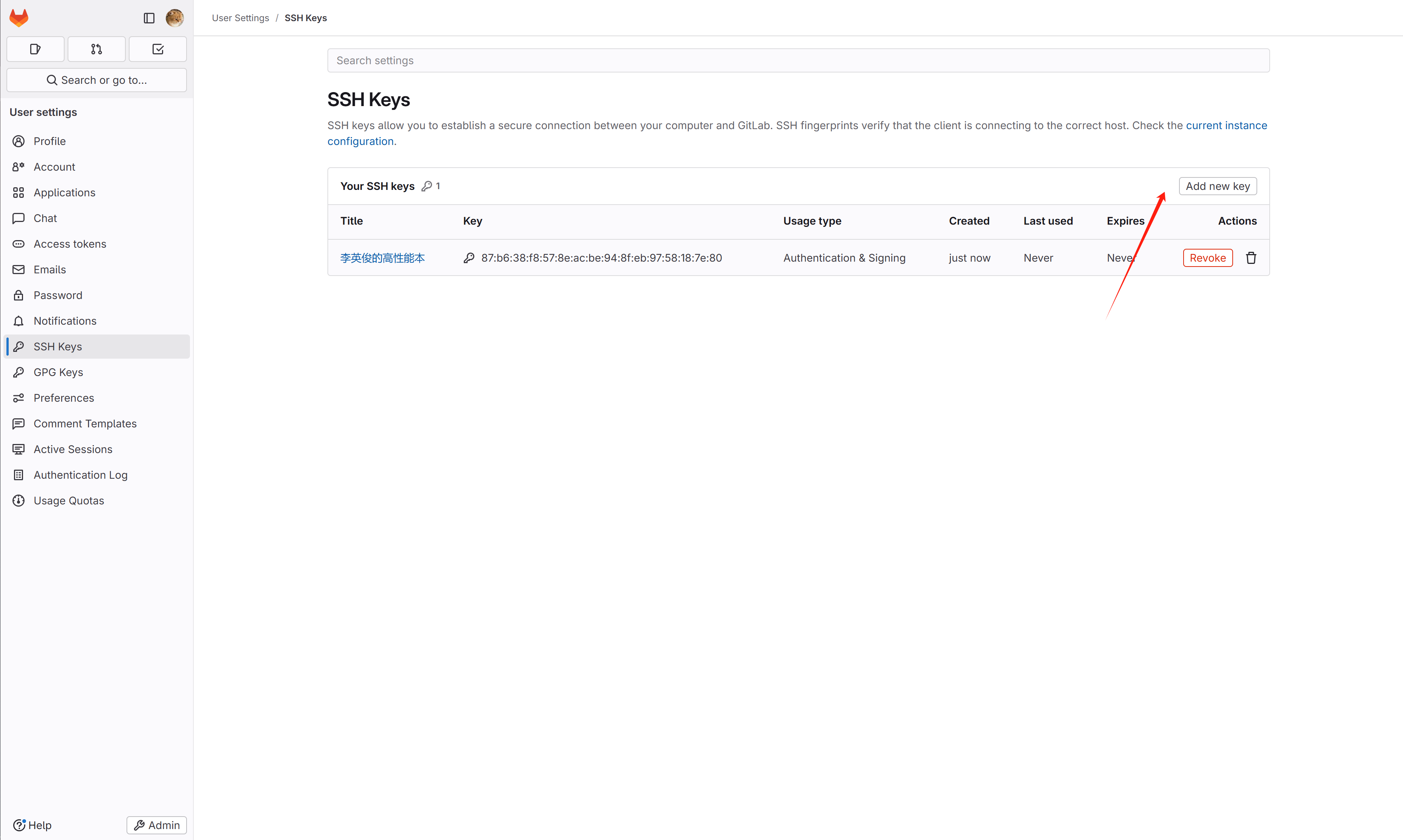
-
项目都只能管理员建啊,多的不说,我自己习惯了先建一个啥没有的空的项目
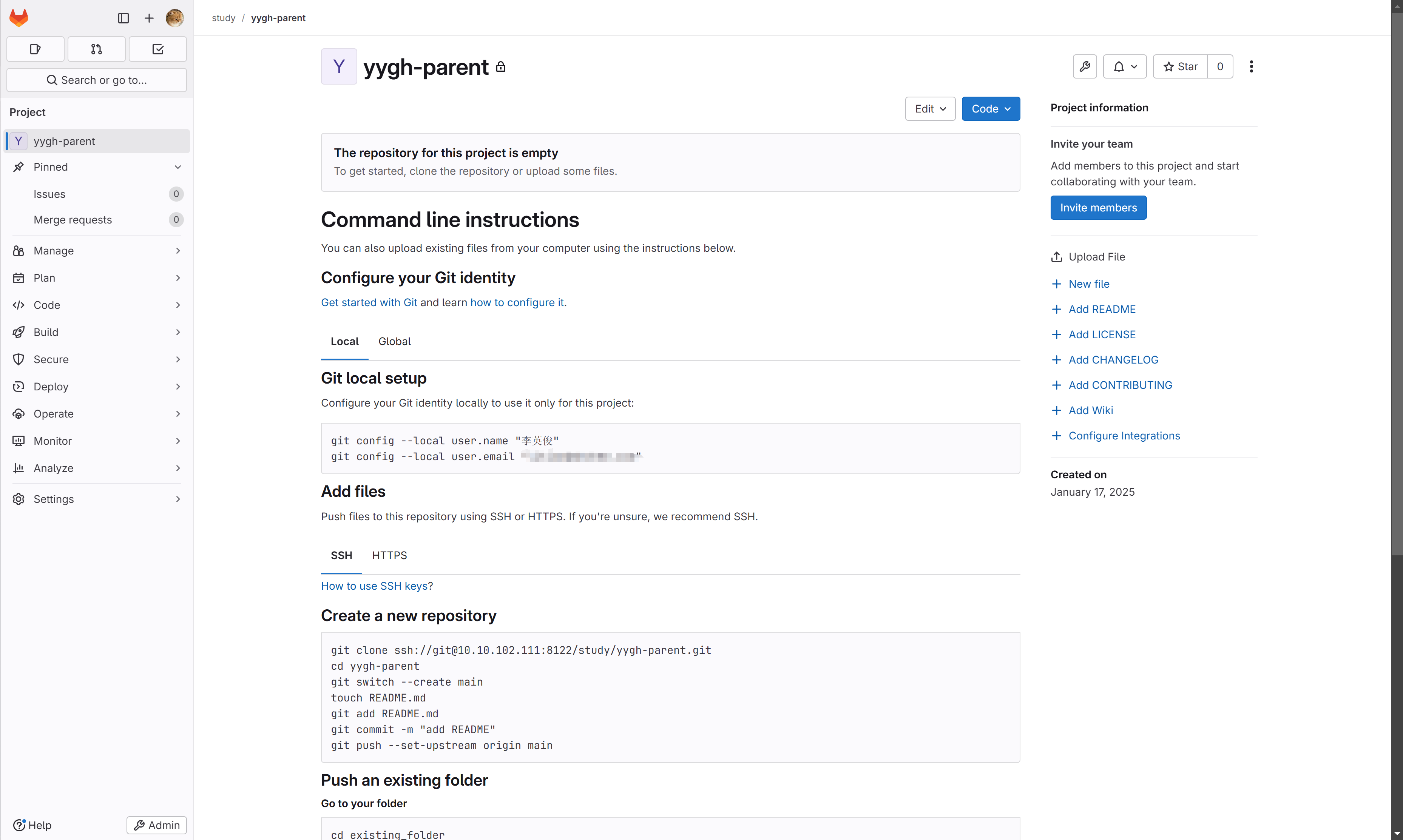
然后根据下面的提示,直接把本地的目录一顿操作之后push
git init --initial-branch=main git remote add origin ssh://git@10.10.102.111:8122/study/yygh-parent.git git add . git commit -m "Initial commit" git push --set-upstream origin main🎉 然后就OK啦,刷新就能看到全部推上去咯
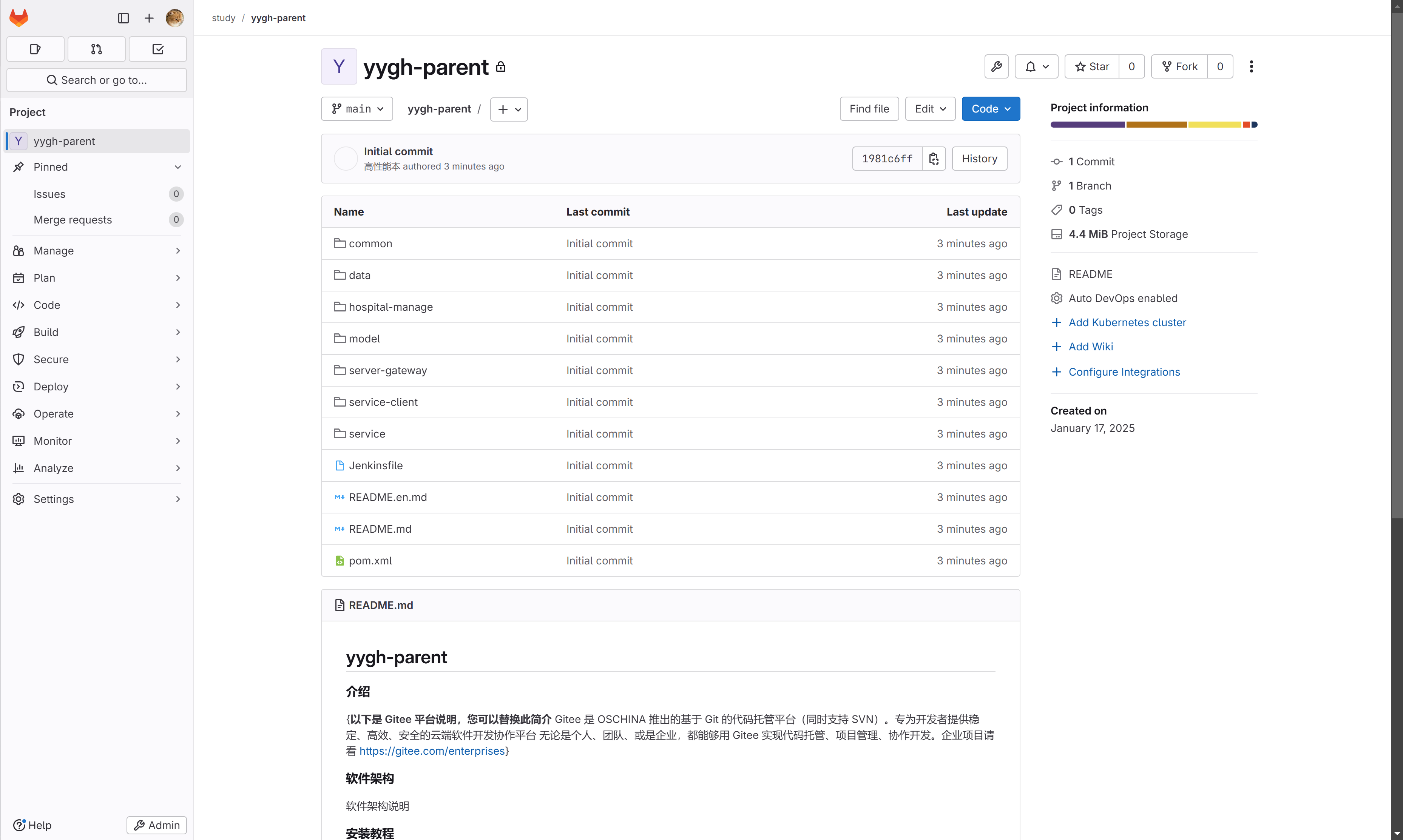
- ☁️ 我的优快云:
https://blog.youkuaiyun.com/qq_21579045 - ❄️ 我的博客园:
https://www.cnblogs.com/lyjun/ - ☀️ 我的Github:
https://github.com/TinyHandsome - 🌈 我的bilibili:
https://space.bilibili.com/8182822 - 🥑 我的思否:
https://segmentfault.com/u/liyj - 🍅 我的知乎:
https://www.zhihu.com/people/lyjun_ - 🐧 粉丝交流群:1060163543,神秘暗号:为干饭而来
碌碌谋生,谋其所爱。🌊 @李英俊小朋友


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











