







 本文详细分析了OkHttp的连接复用机制,包括HTTP的连接复用原理,OkHttp中的连接池实现,连接清理机制,以及连接的建立过程,如直接连接、通过隧道连接和启动HTTP/2连接。通过理解这些机制,可以更好地优化网络请求,提高应用性能。
本文详细分析了OkHttp的连接复用机制,包括HTTP的连接复用原理,OkHttp中的连接池实现,连接清理机制,以及连接的建立过程,如直接连接、通过隧道连接和启动HTTP/2连接。通过理解这些机制,可以更好地优化网络请求,提高应用性能。
当 findConnection 的过程中无法从 transmitter 中取得 Connection 时,会调用 connectionPool.transmitterAcquirePooledConnection 方法来尝试从连接池中获取连接,让我们从这篇文章开始研究一下 OkHttp 中连接池的实现。
系列索引
本系列文章基于 OkHttp3.14
OkHttp3.14 源码剖析系列(一)——请求的发起及拦截器机制概述
OkHttp3.14 源码剖析系列(二)——拦截器大体流程分析
OkHttp3.14 源码剖析系列(六)——连接复用机制及连接的建立
OkHttp3.14 源码剖析系列(七)——请求的发起及响应的读取
HTTP 中的复用机制
HTTP/1.0
在 HTTP/1.0 中,由于 HTTP 协议是一种无连接的网络协议,进行一次 HTTP 请求是这样的一条流程:

这样设计可以保证每条 HTTP 请求都是独立的,互不干扰。但这样的设计有一个致命的缺点——如果我们向同一个服务器发起数十个 HTTP 请求,则我们的每条 HTTP 请求都需要与这个服务器建立一条 TCP 连接。而我们知道,建立 TCP 连接需要经过三次握手,而关闭 TCP 连接则需要四次挥手,可想而知这样频繁地建立与关闭 TCP 连接对网络资源的消耗是十分严重的,极大地降低了网络的效率,并且提高了服务器的压力。
在 HTTP/1.0 中存在一个名为 Connection:Keep-Alive 的 Header,但没有官方的标准规定其工作机制,它默认是关闭的,可以通过在 Header 中加入从而开启。当客户端及服务端都对 Keep-Alive 机制支持时,就可以维持该 TCP 连接从而使得下一次可以进行复用。
HTTP/1.1
而在 HTTP/1.1 中,真正引入了 Keep-Alive 机制,它默认是开启的,可以通过 Connection:close 进行关闭。在 HTTP 请求结束时,若启动了 Keep-Alive 机制,则该连接并不会立即关闭,此时如果有新的请求到来,且 host 相同,则会复用这条 TCP 连接进行请求,减少了 TCP 连接的频繁建立与关闭的资源消耗。
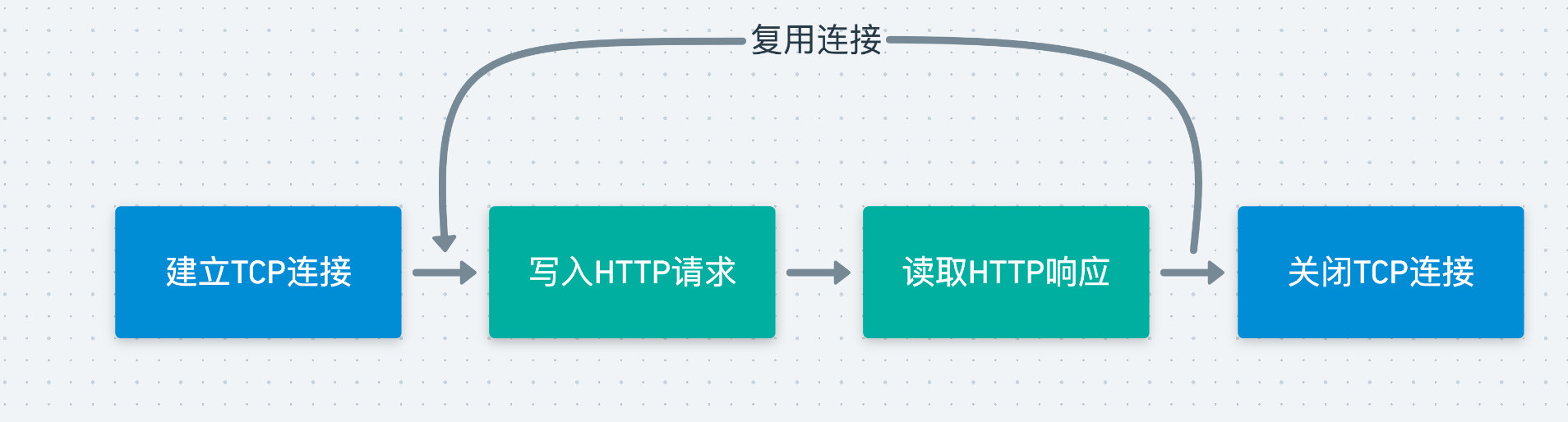
通过这样的连接复用的做法,可以大幅地减少对资源的消耗,如下图所示:
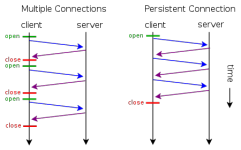
同时,在 HTTP/1.1 中还引入了 Keep-Alive 请求头,在其中可以设定两个值:timeout 与 max ,从而设定这个连接何时被关闭。
timeout:指定了一个空闲连接需要保持打开状态的最小时长(以秒为单位)max:在连接关闭之前,在此连接可以发送的请求的最大值
但这样就存在了一个问题,在原来不采用 Keep-Alive 的时候,客户端可以通过 TCP 连接是否关闭来判断数据是否接收完成,但在采用了 Keep-Alive 的情况下,客户端如何才能得知自己需要的数据已经接收完毕了呢?
Content-Length
看过我之前的多线程下载的实现博文的读者,应该知道在服务端的 Response 的 Header 中,会包含 Content-Length 这一字段,它表示了实体内容的长度(比如文件 / 图片的大小),通过该字段客户端就可以确定自己需要接受的字节数。从而确认数据已接收完成。
Transfer-Encoding:chunked
前面的 Content-Length 看上去完美解决了无法判断数据接收完毕的问题。但对于一些动态的场景,比如一些动态页面,服务端是无法预先知道该页面的大小的,在该页面创建完成前,其长度是不可知的,服务端也就无法返回一个确切的 Content-Length 字段给客户端了,只能开启一个足够大的 buffer。
此时,就可以采用 Transfer-Encoding:chunked 来实现,它表示一种分块编码的意思,它只在 HTTP/1.1 中提供,允许服务端将发送给客户端的数据分成多个部分。
如果使用了分块编码,则请求及响应有以下的特点:
- 在 Header 中加入
Transfer-Encoding:chunked,表示使用分块编码 - 每一个分块有两行,每一行都以
\r\n结尾,第一行表示这个分块的数据长度,是一个十六进制的数(不包括数据结尾的\r\n),第二行则是这个分块的具体数据。 - 最后一个分块长度为0,且数据没有内容,表示整个实体的结束。
HTTP/2
在前面的 HTTP/1.1 中,虽然实现了 TCP 连接的复用,但仍有如下几个缺陷:
- 如果客户端想要发起并行的请求,则必须建立多个 TCP 连接,这对网络资源的消耗也是十分严重的。
- 不会读对请求及响应的 Header 进行压缩,造成了网络流量的浪费。
- 不支持资源优先级导致 TCP 连接利用率低下。
多路复用
为了解决上面几个问题,HTTP/2 引入了多路复用机制,同时引入了几个新的概念:
- 数据流:基于 TCP 连接上的一个双向的字节流,每发起一个请求,就会建立一个数据流,后续的请求过程的数据传递都通过该流进行
- 数据帧:HTTP/2 中的数据最小切片单位,其中又分为了
Header Frame、Data Frame等等。 - 消息:一个请求或响应对应的一系列数据帧。
引入了这些概念之后,在 HTTP 请求的过程中,服务端/客户端首先会将我们的请求/响应切分为不同的数据帧,当另一方接收到后再将其组装从而形成完整的请求/响应,如下所示
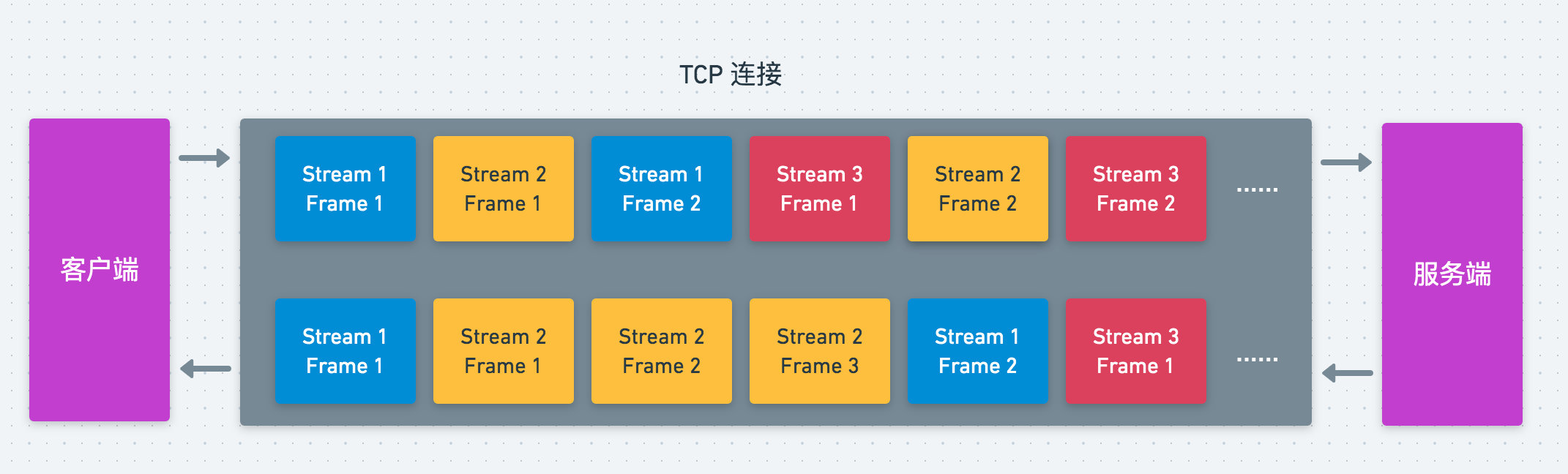
这样,就实现了对 TCP 连接的多路复用,将一个请求或响应分为了一个个的数据帧,使得多个请求可以并行地进行。
多路复用与 Keep-Alive 的区别
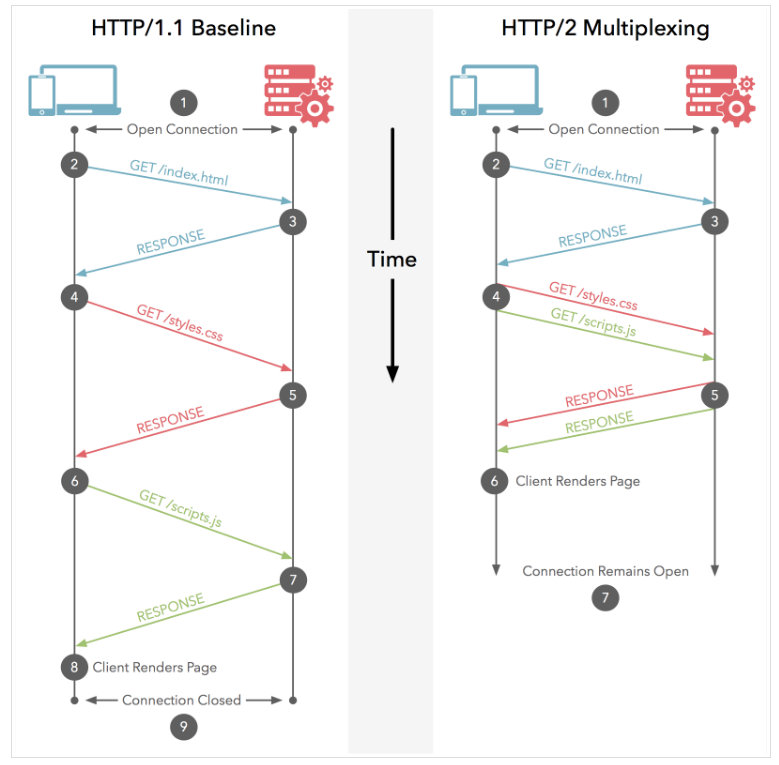
- Keep-Alive 机制虽然解决了复用 TCP 连接问题,但没有解决请求阻塞的问题,需要等到上一个请求结束后,才能复用该 TCP 连接进行下一个请求。
- HTTP/1.x 对数据的传递仍然是以一个整体进行传递,而在 HTTP/2 中引入了数据帧的概念,使得多个请求可以同时在流中进行传递。
- HTTP/2 采用了 HPACK 压缩算法对 Header 进行压缩,降低了请求的流量消耗。
OkHttp 中的复用机制
前面提了 HTTP 中的复用机制,通过对 TCP 连接的复用,大幅提高了网络请求的效率。无论是 HTTP/1.1 中的 Keep-Alive 还是 HTTP/2 中的多路复用,都需要连接池来维护 TCP 连接,让我们看看 OkHttp 中连接池的实现。
我们知道,在 findConnection 过程中,若无法从 transimitter 中获取到连接,则会尝试从连接池中获取连接。
我们可以看到 RealConnectionPool.connections,它是一个 Deque,保存了所有的连接:
private final Deque<RealConnection> connections = new ArrayDeque<>();
连接清理机制
同时会发现,在这个类中还存在着一个 executor,它的设置与 OkHttp 用于异步请求的线程池的设置几乎一样,它是用来做什么的呢?
/**
* Background threads are used to cleanup expired connections. There will be at most a single
* thread running per connection pool. The thread pool executor permits the pool itself to be
* garbage collected.
*/
private static final Executor executor = new ThreadPoolExecutor(0 /* corePoolSize */,
Integer.MAX_VALUE /* maximumPoolSize */, 60L /* keepAliveTime */, TimeUnit.SECONDS,
new SynchronousQueue<>(), Util.threadFactory("OkHttp ConnectionPool", true));
通过上面的注释可以看出,它是用来执行清理过期连接的任务的,并且最多每个连接池只会有一个线程在执行清理任务。这个清理的任务就是下面的 cleanupRunnable:
private final Runnable cleanupRunnable = () -> {
while (true) {
long waitNanos = cleanup(System.nanoTime());
if (waitNanos == -1) return;
if (waitNanos > 0) {
long waitMillis = waitNanos / 1000000L;
waitNanos -= (waitMillis * 1000000L);
synchronized (RealConnectionPool.this) {
try {
RealConnectionPool.this.wait(waitMillis, (int) waitNanos);
} catch (InterruptedException ignored) {
}
}
}
}
};
可以看到它是采用一个循环的方式调用 cleanup 方法进行清理,并从返回值中获取了需要 wait 的秒数,调用 wait 方法进入阻塞,也就是说每次清理的间隔由 cleanup 的返回值进行决定。
我们看到 cleanup 方法:
/**
* Performs maintenance on this pool, evicting the connection that has been idle the longest if
* either it has exceeded the keep alive limit or the idle connections limit.
*
* <p>Returns the duration in nanos to sleep until the next scheduled call to this method. Returns
* -1 if no further cleanups are required.
*/
long cleanup(long now) {
int inUseConnectionCount = 0;
int idleConnectionCount = 0;
RealConnection longestIdleConnection = null;
long longestIdleDurationNs = Long.MIN_VALUE;
synchronized (this) {
for (Iterator<RealConnection> i = connections.iterator(); i.hasNext(); ) {
RealConnection connection = i.next();
// 统计连接被引用的transimitter的个数,若大于0则说明是正在使用的连接
if (pruneAndGetAllocationCount(connection, now) > 0) {
inUseConnectionCount++;
continue;
}
// 否则是空闲连接
idleConnectionCount++;
// 找出空闲连接中空闲时间最长的连接
long idleDurationNs = now - connection.idleAtNanos;
if (idleDurationNs > longestIdleDurationNs) {
longestIdleDurationNs = idleDurationNs;
longestIdleConnection = connection;
}
}
if (longestIdleDurationNs >= this.keepAliveDurationNs
|| idleConnectionCount > this.maxIdleConnections) {
// 如果发现空闲时间最久的连接所空闲时间超过了Keep-Alive设定的时间,或者是空闲连接数超过了最大空闲连接数
// 将前面的其从队列中删除,并且在之后对其socket进行关闭
connections.remove(longestIdleConnection);
} else if (idleConnectionCount > 0) {
// 返回离达到keep-alive设定的时间的距离,将在达到时执行进行清理
return keepAliveDurationNs - longestIdleDurationNs;
} else if (inUseConnectionCount > 0) {
// 如果当前连接都是正在使用的,返回keep-alive所设定的时间
return keepAliveDurationNs;
} else {
// 没有连接了,停止运行cleanup
cleanupRunning = false;
return -1;
}
}
// 关闭空闲最久的连接,继续尝试清理
closeQuietly(longestIdleConnection.socket());
return 0;
}
可以看到,主要是下面几步:
- 调用
pruneAndGetAllocationCount方法统计连接被引用的数量,大于 0 说明连接正在被使用 - 通过上面的方法统计空闲连接数及正在使用的连接数,并从中找出空闲最久的连接
- 若空闲最久的连接空闲的时间超过了所设定的
keepAliveDurationNs(这里不是指的Keep-Alive所设定时间),或者空闲连接数超过了所设定的maxIdleConnections,清理该连接(移除并关闭socket),并返回 0 表示立即继续清理。 - 若还未超过,则返回下一次超过外部设定的
keepAliveDurationNs,表示等到下次超时的时候再进行清理 - 若当前连接都正处于使用中,返回所设定的
keepAliveDurationNs - 若当前没有连接,则将
cleanupRunning置为 false 停止清理
在 OkHttp 中,将空闲连接的最长存活时间设定为了 5 分钟,并且将最大空闲连接数设置为了 5
我们看看 pruneAndGetAllocationCount 是如何对连接被引用的数量进行统计的:
/**
* Prunes any leaked transmitters and then returns the number of remaining live transmitters on
* {@code connection}. Transmitters are leaked if the connection is tracking them but the
* application code has abandoned them. Leak detection is imprecise and relies on garbage
* collection.
*/
private int pruneAndGetAllocationCount(RealConnection connection, long now) {
List<Reference<Transmitter>> references = connection.transmitters;
for (int i = 0; i < references.size(); ) {
Reference<Transmitter> reference = references.get(i);
if (reference.get( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 871
871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









